 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Frustum PointNets for 3D Object Detection from RGB-D Data
Apr 13, 2018

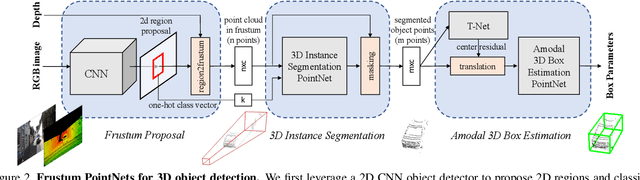
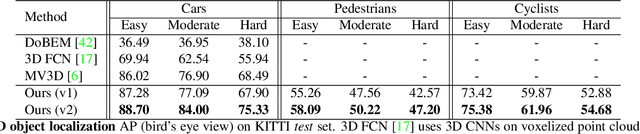
In this work, we study 3D object detection from RGB-D data in both indoor and outdoor scenes. While previous methods focus on images or 3D voxels, often obscuring natural 3D patterns and invariances of 3D data, we directly operate on raw point clouds by popping up RGB-D scans. However, a key challenge of this approach is how to efficiently localize objects in point clouds of large-scale scenes (region proposal). Instead of solely relying on 3D proposals, our method leverages both mature 2D object detectors and advanced 3D deep learning for object localization, achieving efficiency as well as high recall for even small objects. Benefited from learning directly in raw point clouds, our method is also able to precisely estimate 3D bounding boxes even under strong occlusion or with very sparse points. Evaluated on KITTI and SUN RGB-D 3D detection benchmarks, our method outperforms the state of the art by remarkable margins while having real-time capability.
Human Centred Object Co-Segmentation
Jun 12, 2016
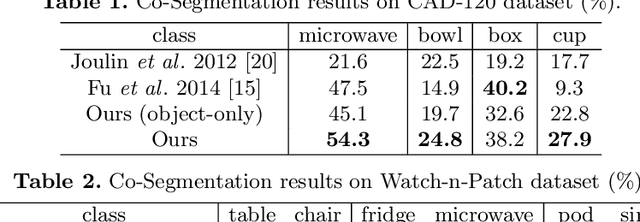
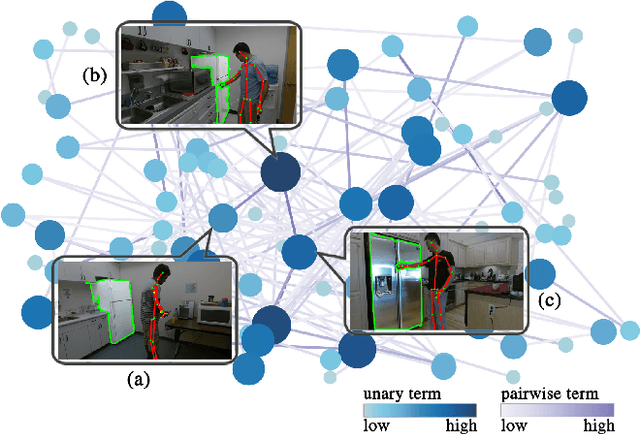
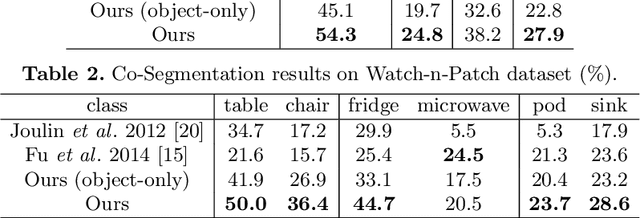
Co-segmentation is the automatic extraction of the common semantic regions given a set of images. Different from previous approaches mainly based on object visuals, in this paper, we propose a human centred object co-segmentation approach, which uses the human as another strong evidence. In order to discover the rich internal structure of the objects reflecting their human-object interactions and visual similarities, we propose an unsupervised fully connected CRF auto-encoder incorporating the rich object features and a novel human-object interaction representation. We propose an efficient learning and inference algorithm to allow the full connectivity of the CRF with the auto-encoder, that establishes pairwise relations on all pairs of the object proposals in the dataset. Moreover, the auto-encoder learns the parameters from the data itself rather than supervised learning or manually assigned parameters in the conventional CRF. In the extensive experiments on four datasets, we show that our approach is able to extract the common objects more accurately than the state-of-the-art co-segmentation algorithms.
Unsupervised Semantic Action Discovery from Video Collections
May 11, 2016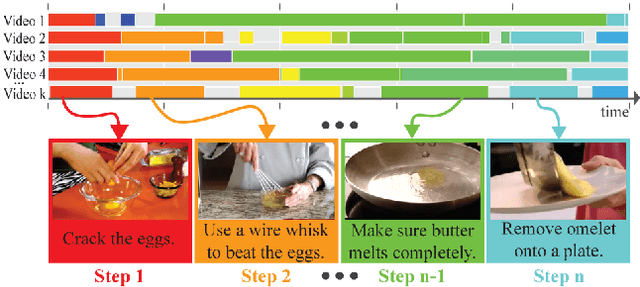


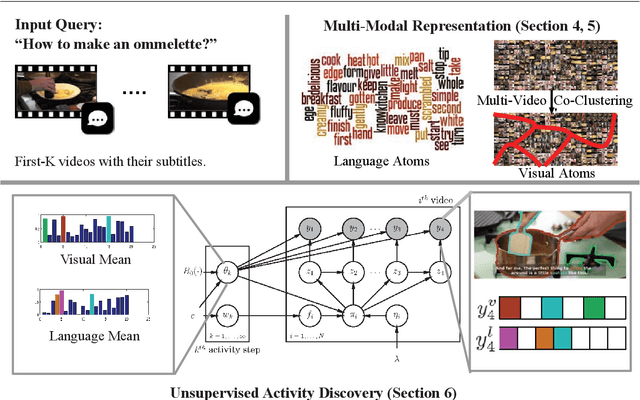
Human communication takes many forms, including speech, text and instructional videos. It typically has an underlying structure, with a starting point, ending, and certain objective steps between them. In this paper, we consider instructional videos where there are tens of millions of them on the Internet. We propose a method for parsing a video into such semantic steps in an unsupervised way. Our method is capable of providing a semantic "storyline" of the video composed of its objective steps. We accomplish this using both visual and language cues in a joint generative model. Our method can also provide a textual description for each of the identified semantic steps and video segments. We evaluate our method on a large number of complex YouTube videos and show that our method discovers semantically correct instructions for a variety of tasks.
Watch-n-Patch: Unsupervised Learning of Actions and Relations
Mar 11, 2016

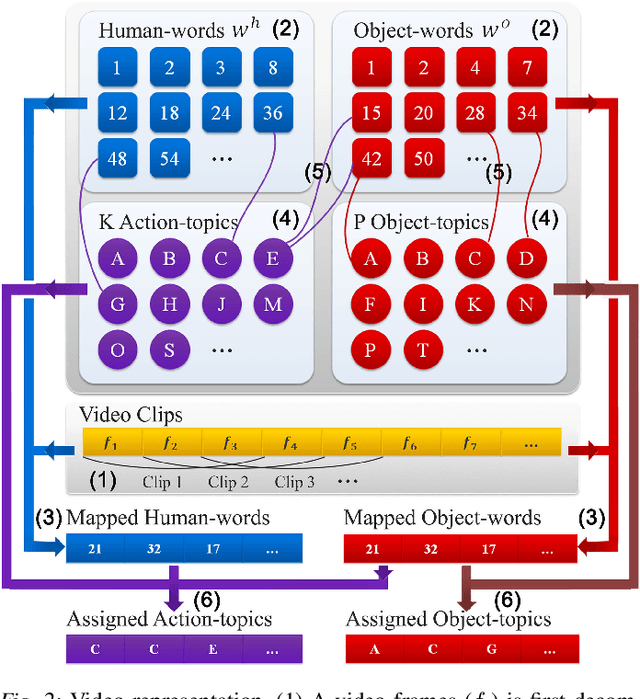
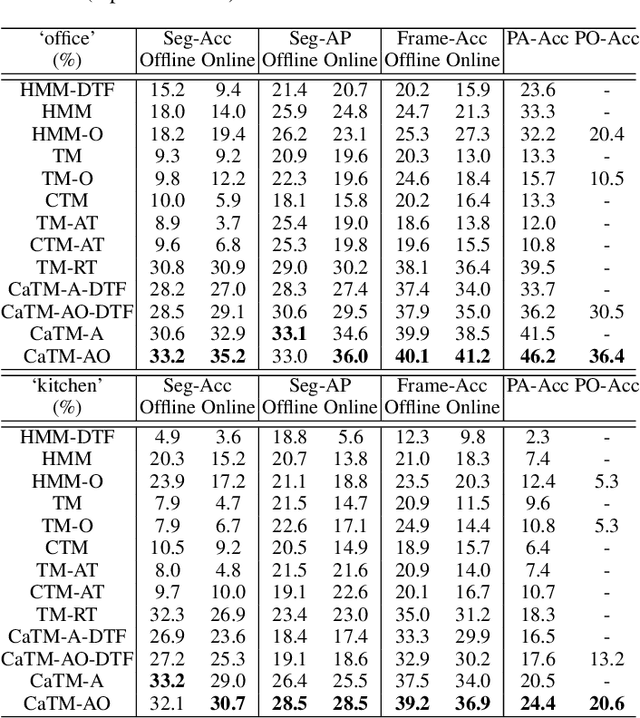
There is a large variation in the activities that humans perform in their everyday lives. We consider modeling these composite human activities which comprises multiple basic level actions in a completely unsupervised setting. Our model learns high-level co-occurrence and temporal relations between the actions. We consider the video as a sequence of short-term action clips, which contains human-words and object-words. An activity is about a set of action-topics and object-topics indicating which actions are present and which objects are interacting with. We then propose a new probabilistic model relating the words and the topics. It allows us to model long-range action relations that commonly exist in the composite activities, which is challenging in previous works. We apply our model to the unsupervised action segmentation and clustering, and to a novel application that detects forgotten actions, which we call action patching. For evaluation, we contribute a new challenging RGB-D activity video dataset recorded by the new Kinect v2, which contains several human daily activities as compositions of multiple actions interacting with different objects. Moreover, we develop a robotic system that watches people and reminds people by applying our action patching algorithm. Our robotic setup can be easily deployed on any assistive robot.
Watch-Bot: Unsupervised Learning for Reminding Humans of Forgotten Actions
Dec 14, 2015
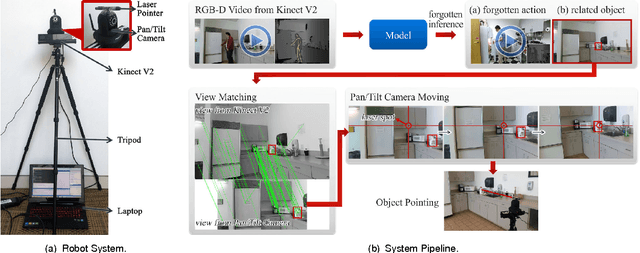
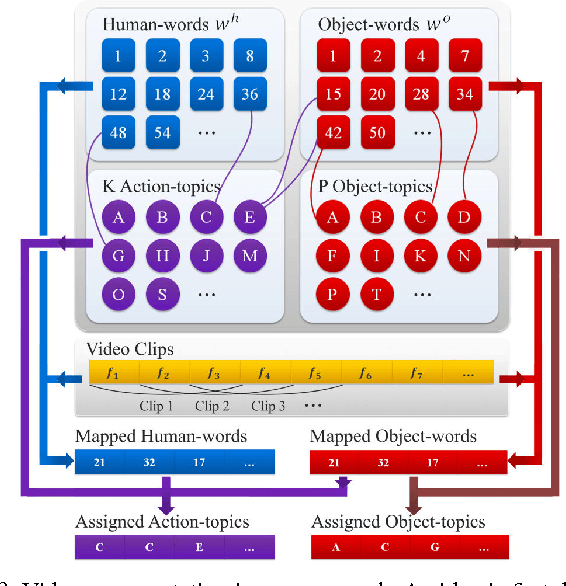
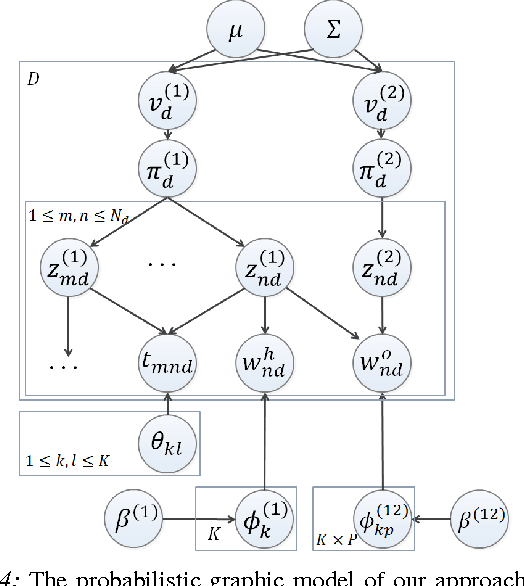
We present a robotic system that watches a human using a Kinect v2 RGB-D sensor, detects what he forgot to do while performing an activity, and if necessary reminds the person using a laser pointer to point out the related object. Our simple setup can be easily deployed on any assistive robot. Our approach is based on a learning algorithm trained in a purely unsupervised setting, which does not require any human annotations. This makes our approach scalable and applicable to variant scenarios. Our model learns the action/object co-occurrence and action temporal relations in the activity, and uses the learned rich relationships to infer the forgotten action and the related object. We show that our approach not only improves the unsupervised action segmentation and action cluster assignment performance, but also effectively detects the forgotten actions on a challenging human activity RGB-D video dataset. In robotic experiments, we show that our robot is able to remind people of forgotten actions successfully.