 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Scene Grammar for Parsing RGB-D Pointclouds
Paper and Code
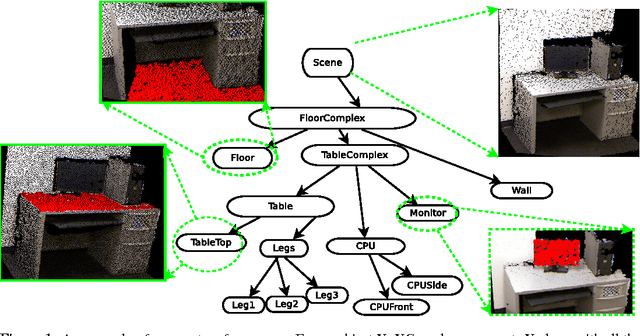

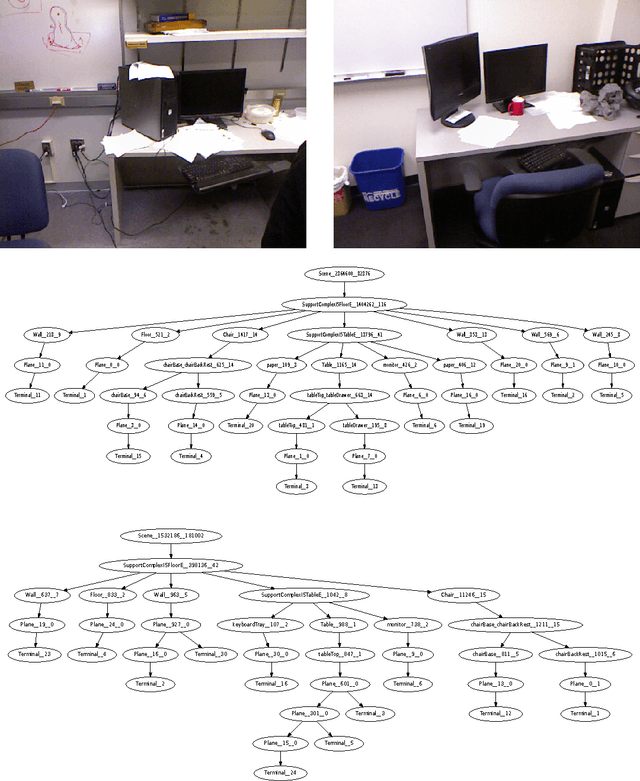

We pose 3D scene-understanding as a problem of parsing in a grammar. A grammar helps us capture the compositional structure of real-word objects, e.g., a chair is composed of a seat, a back-rest and some legs. Having multiple rules for an object helps us capture structural variations in objects, e.g., a chair can optionally also have arm-rests. Finally, having rules to capture composition at different levels helps us formulate the entire scene-processing pipeline as a single problem of finding most likely parse-tree---small segments combine to form parts of objects, parts to objects and objects to a scene. We attach a generative probability model to our grammar by having a feature-dependent probability function for every rule. We evaluated it by extracting labels for every segment and comparing the results with the state-of-the-art segment-labeling algorithm. Our algorithm was outperformed by the state-or-the-art method. But, Our model can be trained very efficiently (within seconds), and it scales only linearly in with the number of rules in the grammar. Also, we think that this is an important problem for the 3D vision community. So, we are releasing our dataset and related code.