 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Current Language Models Support Code Intelligence for R Programming Language?
Oct 10, 2024
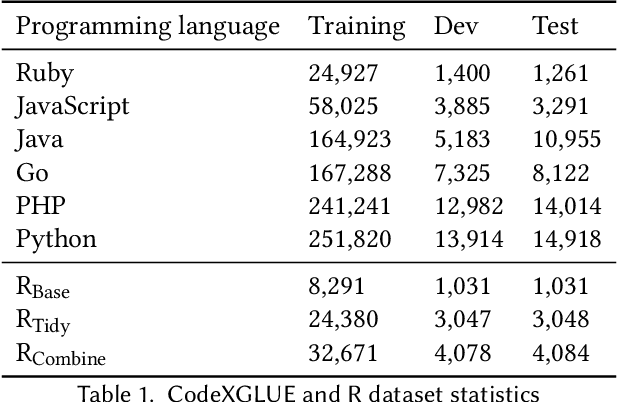
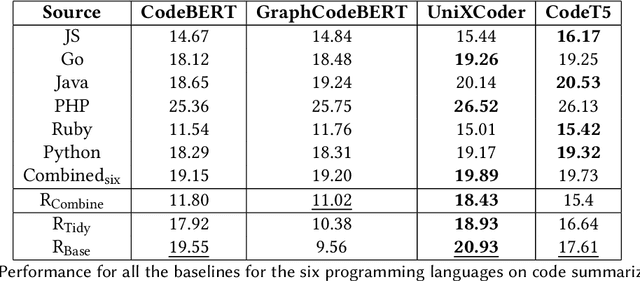
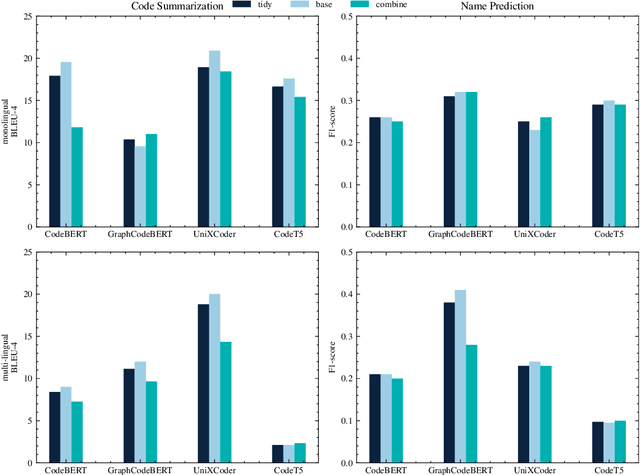
Recent advancements in developing Pre-trained Language Models for Code (Code-PLMs) have urged many areas of Software Engineering (SE) and brought breakthrough results for many SE tasks. Though these models have achieved the state-of-the-art performance for SE tasks for many popular programming languages, such as Java and Python, the Scientific Software and its related languages like R programming language have rarely benefited or even been evaluated with the Code-PLMs. Research has shown that R has many differences with other programming languages and requires specific techniques. In this study, we provide the first insights for code intelligence for R. For this purpose, we collect and open source an R dataset, and evaluate Code-PLMs for the two tasks of code summarization and method name prediction using several settings and strategies, including the differences in two R styles, Tidy-verse and Base R. Our results demonstrate that the studied models have experienced varying degrees of performance degradation when processing R programming language code, which is supported by human evaluation. Additionally, not all models show performance improvement in R-specific tasks even after multi-language fine-tuning. The dual syntax paradigms in R significantly impact the models' performance, particularly in code summarization tasks. Furthermore, the project-specific context inherent in R codebases significantly impacts the performance when attempting cross-project training.