 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exploratory Study on Code Attention in BERT
Paper and Code
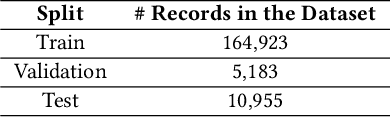
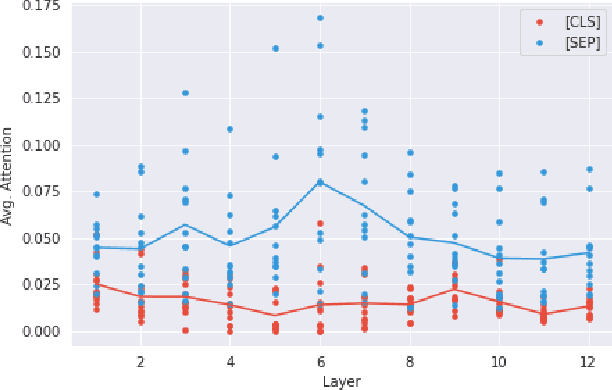

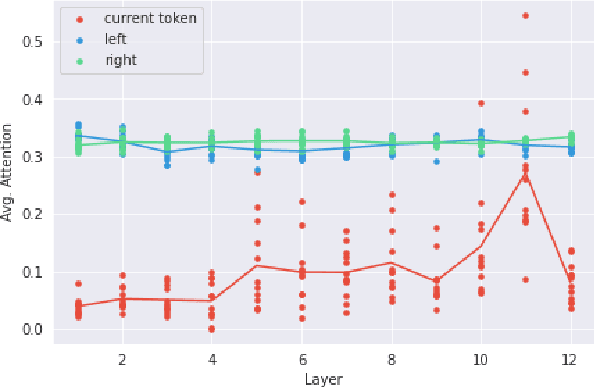
Many recent models in software engineering introduced deep neural models based on the Transformer architecture or use transformer-based Pre-trained Language Models (PLM) trained on code. Although these models achieve the state of the arts results in many downstream tasks such as code summarization and bug detection, they are based on Transformer and PLM, which are mainly studied in the Natural Language Processing (NLP) field. The current studies rely on the reasoning and practices from NLP for these models in code, despite the differences between natural languages and programming languages. There is also limited literature on explaining how code is modeled. Here, we investigate the attention behavior of PLM on code and compare it with natural language. We pre-trained BERT, a Transformer based PLM, on code and explored what kind of information it learns, both semantic and syntactic. We run several experiments to analyze the attention values of code constructs on each other and what BERT learns in each layer. Our analyses show that BERT pays more attention to syntactic entities, specifically identifiers and separators, in contrast to the most attended token [CLS] in NLP. This observation motivated us to leverage identifiers to represent the code sequence instead of the [CLS] token when used for code clone detection. Our results show that employing embeddings from identifiers increases the performance of BERT by 605% and 4% F1-score in its lower layers and the upper layers, respectively. When identifiers' embeddings are used in CodeBERT, a code-based PLM, the performance is improved by 21-24% in the F1-score of clone detection. The findings can benefit the research community by using code-specific representations instead of applying the common embeddings used in NLP, and open new directions for developing smaller models with similar performance.