 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAMNER: Code Comment Generation Using Character Language Model and Named Entity Recognition
Paper and Code
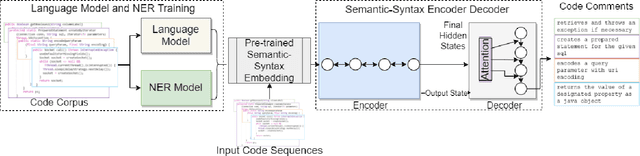
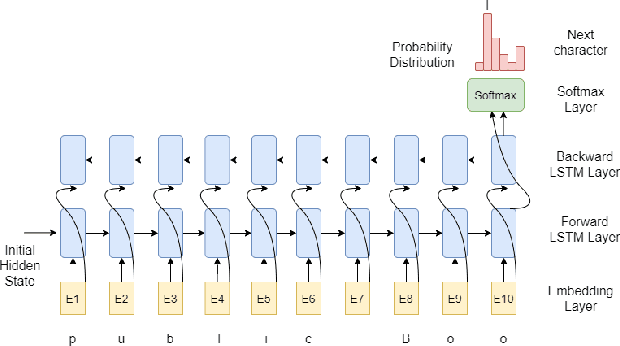
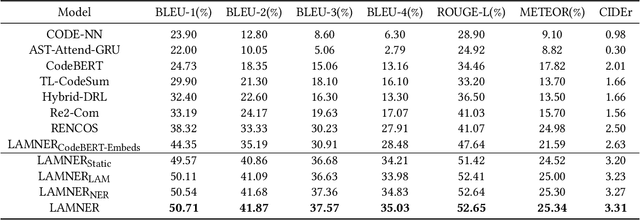
Code comment generation is the task of generating a high-level natural language description for a given code method or function. Although researchers have been studying multiple ways to generate code comments automatically, previous work mainly considers representing a code token in its entirety semantics form only (e.g., a language model is used to learn the semantics of a code token), and additional code properties such as the tree structure of a code are included as an auxiliary input to the model. There are two limitations: 1) Learning the code token in its entirety form may not be able to capture information succinctly in source code, and 2) The code token does not contain additional syntactic information, inherently important in programming languages. In this paper, we present LAnguage Model and Named Entity Recognition (LAMNER), a code comment generator capable of encoding code constructs effectively and capturing the structural property of a code token. A character-level language model is used to learn the semantic representation to encode a code token. For the structural property of a token, a Named Entity Recognition model is trained to learn the different types of code tokens. These representations are then fed into an encoder-decoder architecture to generate code comments. We evaluate the generated comments from LAMNER and other baselines on a popular Java dataset with four commonly used metrics. Our results show that LAMNER is effective and improves over the best baseline model in BLEU-1, BLEU-2, BLEU-3, BLEU-4, ROUGE-L, METEOR, and CIDEr by 14.34%, 18.98%, 21.55%, 23.00%, 10.52%, 1.44%, and 25.86%, respectively. Additionally, we fused LAMNER's code representation with the baseline models, and the fused models consistently showed improvement over the non-fused models. The human evaluation further shows that LAMNER produces high-quality code comments.