 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Jun 26, 2024



Automated software engineering has been greatly empowered by the recent advances in Large Language Models (LLMs) for programming. While current benchmarks have shown that LLMs can perform various software engineering tasks like human developers, the majority of their evaluations are limited to short and self-contained algorithmic tasks. Solving challenging and practical programming tasks requires the capability of utilizing diverse function calls as tools to efficiently implement functionalities like data analysis and web development. In addition, using multiple tools to solve a task needs compositional reasoning by accurately understanding complex instructions. Fulfilling both of these characteristics can pose a great challenge for LLMs. To assess how well LLMs can solve challenging and practical programming tasks, we introduce Bench, a benchmark that challenges LLMs to invoke multiple function calls as tools from 139 libraries and 7 domains for 1,140 fine-grained programming tasks. To evaluate LLMs rigorously, each programming task encompasses 5.6 test cases with an average branch coverage of 99%. In addition, we propose a natural-language-oriented variant of Bench, Benchi, that automatically transforms the original docstrings into short instructions only with essential information. Our extensive evaluation of 60 LLMs shows that LLMs are not yet capable of following complex instructions to use function calls precisely, with scores up to 60%, significantly lower than the human performance of 97%. The results underscore the need for further advancements in this area.
Navigating Privacy and Copyright Challenges Across the Data Lifecycle of Generative AI
Nov 30, 2023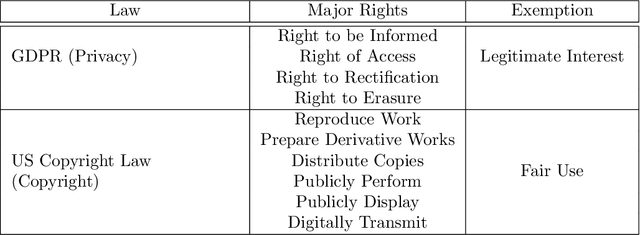
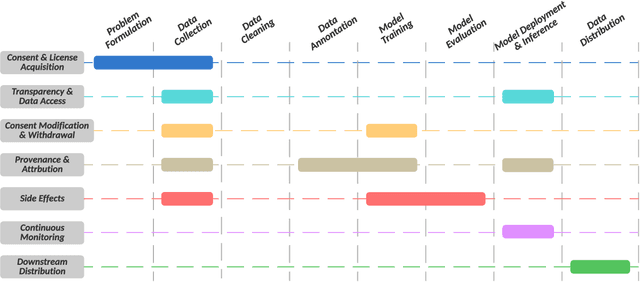
The advent of Generative AI has marked a significant milestone in artificial intelligence, demonstrating remarkable capabilities in generating realistic images, texts, and data patterns. However, these advancements come with heightened concerns over data privacy and copyright infringement, primarily due to the reliance on vast datasets for model training. Traditional approaches like differential privacy, machine unlearning, and data poisoning only offer fragmented solutions to these complex issues. Our paper delves into the multifaceted challenges of privacy and copyright protection within the data lifecycle. We advocate for integrated approaches that combines technical innovation with ethical foresight, holistically addressing these concerns by investigating and devising solutions that are informed by the lifecycle perspective. This work aims to catalyze a broader discussion and inspire concerted efforts towards data privacy and copyright integrity in Generative AI.
Test-takers have a say: understanding the implications of the use of AI in language tests
Jul 19, 2023
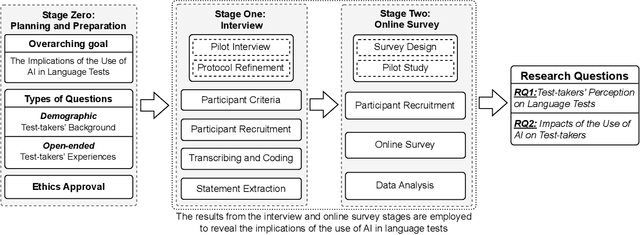

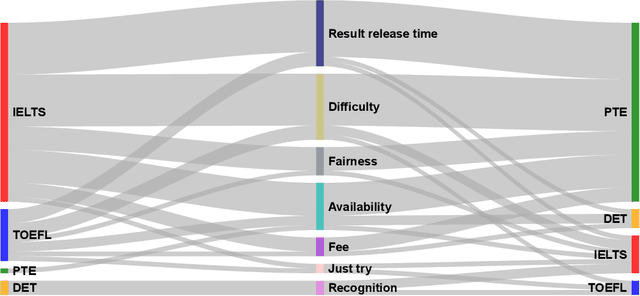
Language tests measure a person's ability to use a language in terms of listening, speaking, reading, or writing. Such tests play an integral role in academic, professional, and immigration domains, with entities such as educational institutions, professional accreditation bodies, and governments using them to assess candidate language proficiency. Recent advances in Artificial Intelligence (AI) and the discipline of Natural Language Processing have prompted language test providers to explore AI's potential applicability within language testing, leading to transformative activity patterns surrounding language instruction and learning. However, with concerns over AI's trustworthiness, it is imperative to understand the implications of integrating AI into language testing. This knowledge will enable stakeholders to make well-informed decisions, thus safeguarding community well-being and testing integrity. To understand the concerns and effects of AI usage in language tests, we conducted interviews and surveys with English test-takers. To the best of our knowledge, this is the first empirical study aimed at identifying the implications of AI adoption in language tests from a test-taker perspective. Our study reveals test-taker perceptions and behavioral patterns. Specifically, we identify that AI integration may enhance perceptions of fairness, consistency, and availability. Conversely, it might incite mistrust regarding reliability and interactivity aspects, subsequently influencing the behaviors and well-being of test-takers. These insights provide a better understanding of potential societal implications and assist stakeholders in making informed decisions concerning AI usage in language testing.
Right to be Forgotten in the Era of Large Language Models: Implications, Challenges, and Solutions
Jul 08, 2023


The Right to be Forgotten (RTBF) was first established as the result of the ruling of Google Spain SL, Google Inc. v AEPD, Mario Costeja Gonz\'alez, and was later included as the Right to Erasure under the General Data Protection Regulation (GDPR) of European Union to allow individuals the right to request personal data be deleted by organizations. Specifically for search engines, individuals can send requests to organizations to exclude their information from the query results. With the recent development of Large Language Models (LLMs) and their use in chatbots, LLM-enabled software systems have become popular. But they are not excluded from the RTBF. Compared with the indexing approach used by search engines, LLMs store, and process information in a completely different way. This poses new challenges for compliance with the RTBF. In this paper, we explore these challenges and provide our insights on how to implement technical solutions for the RTBF, including the use of machine unlearning, model editing, and prompting engineering.
Blockchain-Empowered Trustworthy Data Sharing: Fundamentals, Applications, and Challenges
Mar 12, 2023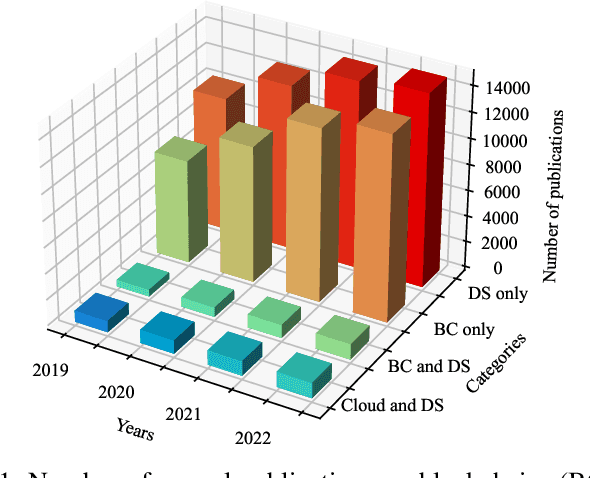
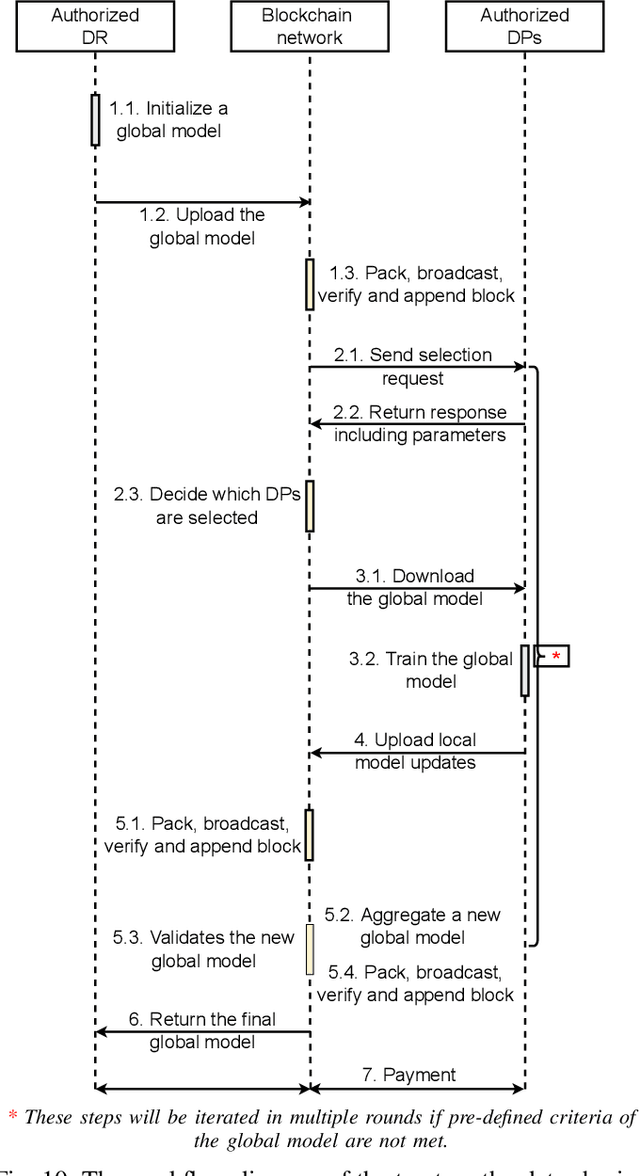
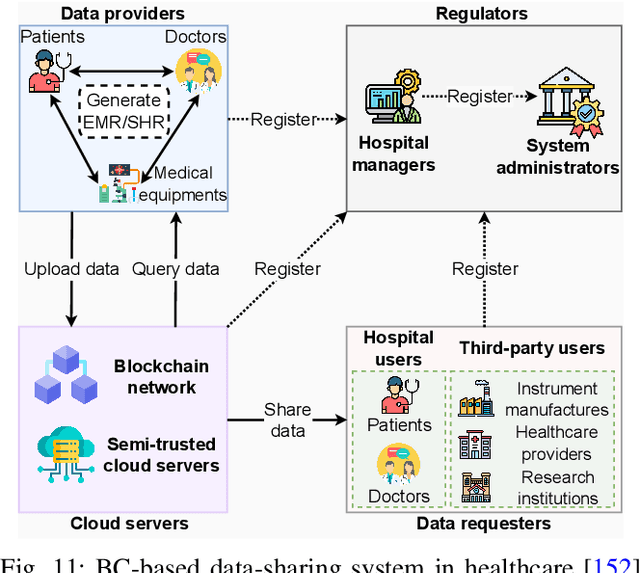

Various data-sharing platforms have emerged with the growing public demand for open data and legislation mandating certain data to remain open. Most of these platforms remain opaque, leading to many questions about data accuracy, provenance and lineage, privacy implications, consent management, and the lack of fair incentives for data providers. With their transparency, immutability, non-repudiation, and decentralization properties, blockchains could not be more apt to answer these questions and enhance trust in a data-sharing platform. However, blockchains are not good at handling the four Vs of big data (i.e., volume, variety, velocity, and veracity) due to their limited performance, scalability, and high cost. Given many related works proposes blockchain-based trustworthy data-sharing solutions, there is increasing confusion and difficulties in understanding and selecting these technologies and platforms in terms of their sharing mechanisms, sharing services, quality of services, and applications. In this paper, we conduct a comprehensive survey on blockchain-based data-sharing architectures and applications to fill the gap. First, we present the foundations of blockchains and discuss the challenges of current data-sharing techniques. Second, we focus on the convergence of blockchain and data sharing to give a clear picture of this landscape and propose a reference architecture for blockchain-based data sharing. Third, we discuss the industrial applications of blockchain-based data sharing, ranging from healthcare and smart grid to transportation and decarbonization. For each application, we provide lessons learned for the deployment of Blockchain-based data sharing. Finally, we discuss research challenges and open research directions.
To Be Forgotten or To Be Fair: Unveiling Fairness Implications of Machine Unlearning Methods
Feb 07, 2023The right to be forgotten (RTBF) is motivated by the desire of people not to be perpetually disadvantaged by their past deeds. For this, data deletion needs to be deep and permanent, and should be removed from machine learning models. Researchers have proposed machine unlearning algorithms which aim to erase specific data from trained models more efficiently. However, these methods modify how data is fed into the model and how training is done, which may subsequently compromise AI ethics from the fairness perspective. To help software engineers make responsible decisions when adopting these unlearning methods, we present the first study on machine unlearning methods to reveal their fairness implications. We designed and conducted experiments on two typical machine unlearning methods (SISA and AmnesiacML) along with a retraining method (ORTR) as baseline using three fairness datasets under three different deletion strategies. Experimental results show that under non-uniform data deletion, SISA leads to better fairness compared with ORTR and AmnesiacML, while initial training and uniform data deletion do not necessarily affect the fairness of all three methods. These findings have exposed an important research problem in software engineering, and can help practitioners better understand the potential trade-offs on fairness when considering solutions for RTBF.
Keen2Act: Activity Recommendation in Online Social Collaborative Platforms
May 11, 2020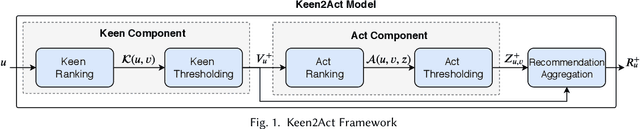
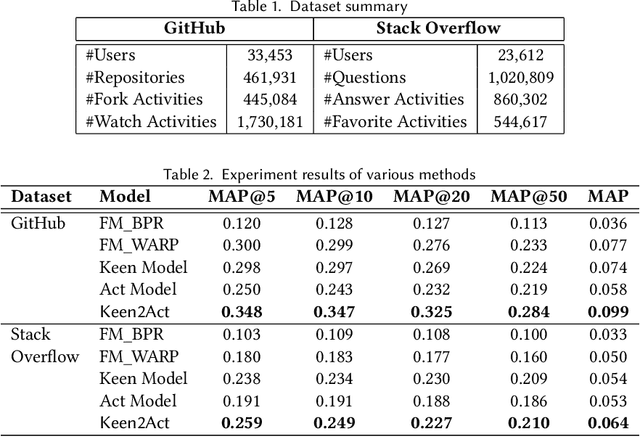
Social collaborative platforms such as GitHub and Stack Overflow have been increasingly used to improve work productivity via collaborative efforts. To improve user experiences in these platforms, it is desirable to have a recommender system that can suggest not only items (e.g., a GitHub repository) to a user, but also activities to be performed on the suggested items (e.g., forking a repository). To this end, we propose a new approach dubbed Keen2Act, which decomposes the recommendation problem into two stages: the Keen and Act steps. The Keen step identifies, for a given user, a (sub)set of items in which he/she is likely to be interested. The Act step then recommends to the user which activities to perform on the identified set of items. This decomposition provides a practical approach to tackling complex activity recommendation tasks while producing higher recommendation quality. We evaluate our proposed approach using two real-world datasets and obtain promising results whereby Keen2Act outperforms several baseline models.
PatchNet: A Tool for Deep Patch Classification
Mar 26, 2019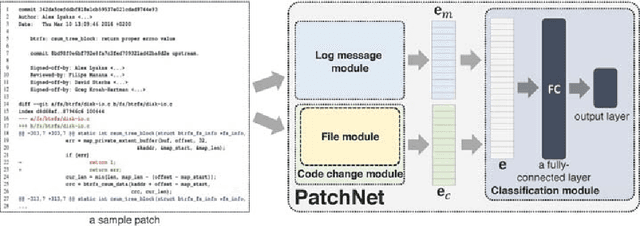
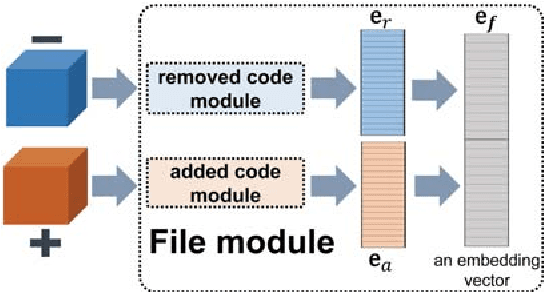
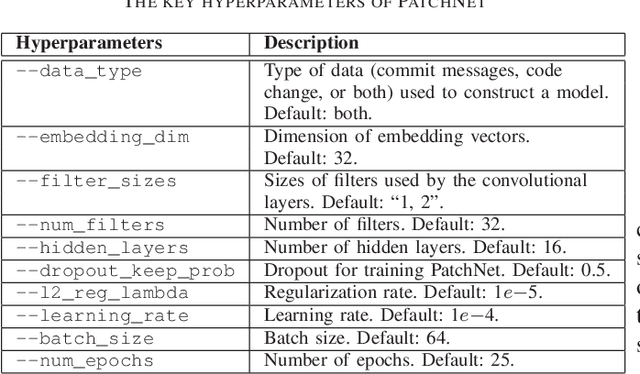
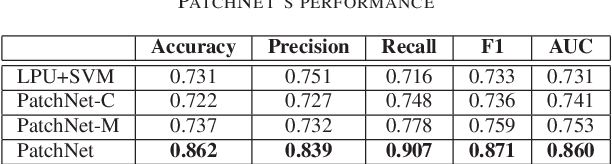
This work proposes PatchNet, an automated tool based on hierarchical deep learning for classifying patches by extracting features from commit messages and code changes. PatchNet contains a deep hierarchical structure that mirrors the hierarchical and sequential structure of a code change, differentiating it from the existing deep learning models on source code. PatchNet provides several options allowing users to select parameters for the training process. The tool has been validated in the context of automatic identification of stable-relevant patches in the Linux kernel and is potentially applicable to automate other software engineering tasks that can be formulated as patch classification problems. A video demonstrating PatchNet is available at https://goo.gl/CZjG6X. The PatchNet implementation is available at https://github.com/hvdthong/PatchNetTool.
Network-Clustered Multi-Modal Bug Localization
Feb 27, 2018
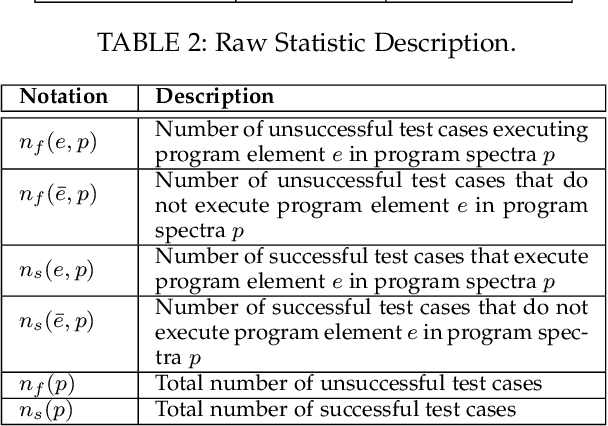
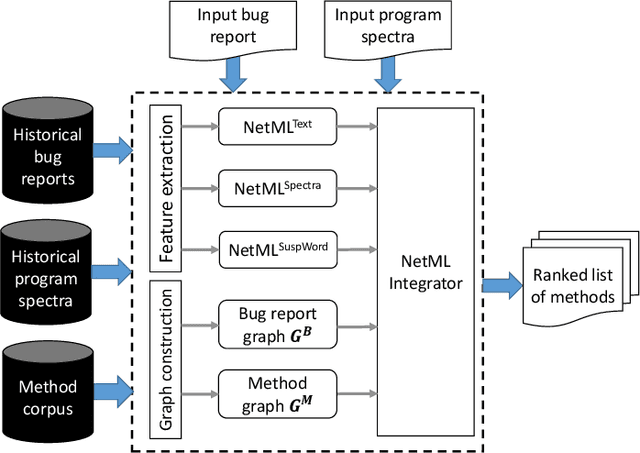
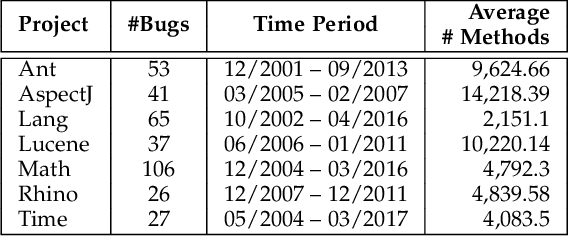
Developers often spend much effort and resources to debug a program. To help the developers debug, numerous information retrieval (IR)-based and spectrum-based bug localization techniques have been devised. IR-based techniques process textual information in bug reports, while spectrum-based techniques process program spectra (i.e., a record of which program elements are executed for each test case). While both techniques ultimately generate a ranked list of program elements that likely contain a bug, they only consider one source of information--either bug reports or program spectra--which is not optimal. In light of this deficiency, this paper presents a new approach dubbed Network-clustered Multi-modal Bug Localization (NetML), which utilizes multi-modal information from both bug reports and program spectra to localize bugs. NetML facilitates an effective bug localization by carrying out a joint optimization of bug localization error and clustering of both bug reports and program elements (i.e., methods). The clustering is achieved through the incorporation of network Lasso regularization, which incentivizes the model parameters of similar bug reports and similar program elements to be close together. To estimate the model parameters of both bug reports and methods, NetML employs an adaptive learning procedure based on Newton method that updates the parameters on a per-feature basis. Extensive experiments on 355 real bugs from seven software systems have been conducted to benchmark NetML against various state-of-the-art localization methods. The results show that NetML surpasses the best-performing baseline by 31.82%, 22.35%, 19.72%, and 19.24%, in terms of the number of bugs successfully localized when a developer inspects the top 1, 5, and 10 methods and Mean Average Precision (MAP), respectively.