 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Layered Architecture for Developing and Enhancing Capabilities in Large Language Model-based Software Systems
Nov 19, 2024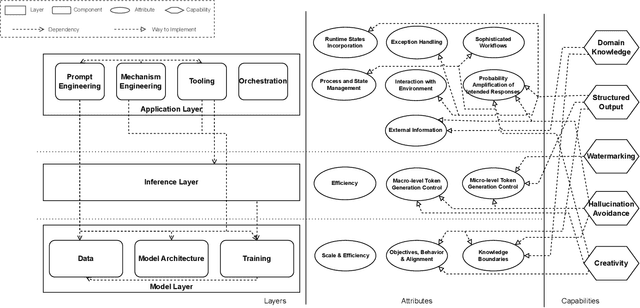
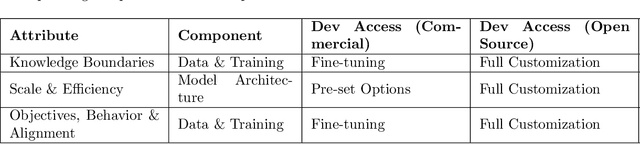

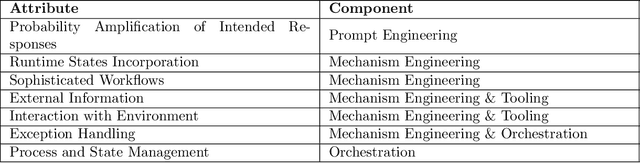
Significant efforts has been made to expand the use of Large Language Models (LLMs) beyond basic language tasks. While the generalizability and versatility of LLMs have enabled widespread adoption, evolving demands in application development often exceed their native capabilities. Meeting these demands may involve a diverse set of methods, such as enhancing creativity through either inference temperature adjustments or creativity-provoking prompts. Selecting the right approach is critical, as different methods lead to trade-offs in engineering complexity, scalability, and operational costs. This paper introduces a layered architecture that organizes LLM software system development into distinct layers, each characterized by specific attributes. By aligning capabilities with these layers, the framework encourages the systematic implementation of capabilities in effective and efficient ways that ultimately supports desired functionalities and qualities. Through practical case studies, we illustrate the utility of the framework. This work offers developers actionable insights for selecting suitable technologies in LLM-based software system development, promoting robustness and scalability.
Blockchain-Enabled Accountability in Data Supply Chain: A Data Bill of Materials Approach
Aug 16, 2024

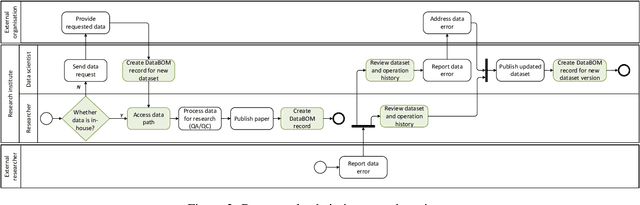
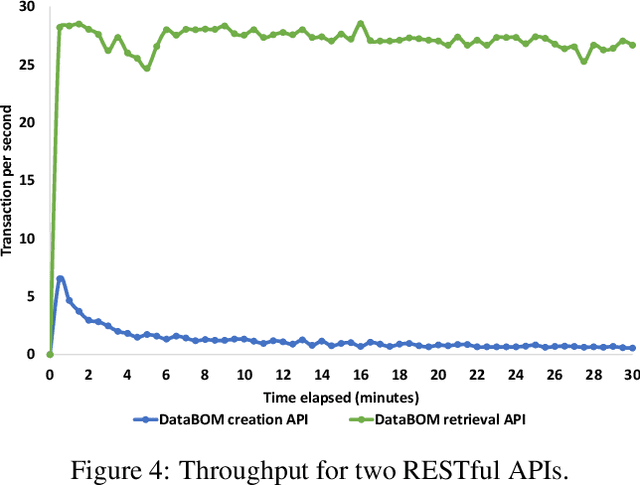
In the era of advanced artificial intelligence, highlighted by large-scale generative models like GPT-4, ensuring the traceability, verifiability, and reproducibility of datasets throughout their lifecycle is paramount for research institutions and technology companies. These organisations increasingly rely on vast corpora to train and fine-tune advanced AI models, resulting in intricate data supply chains that demand effective data governance mechanisms. In addition, the challenge intensifies as diverse stakeholders may use assorted tools, often without adequate measures to ensure the accountability of data and the reliability of outcomes. In this study, we adapt the concept of ``Software Bill of Materials" into the field of data governance and management to address the above challenges, and introduce ``Data Bill of Materials" (DataBOM) to capture the dependency relationship between different datasets and stakeholders by storing specific metadata. We demonstrate a platform architecture for providing blockchain-based DataBOM services, present the interaction protocol for stakeholders, and discuss the minimal requirements for DataBOM metadata. The proposed solution is evaluated in terms of feasibility and performance via case study and quantitative analysis respectively.
Navigating Privacy and Copyright Challenges Across the Data Lifecycle of Generative AI
Nov 30, 2023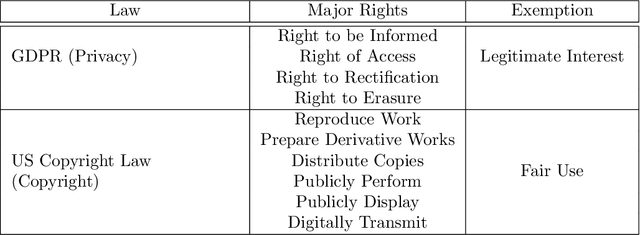
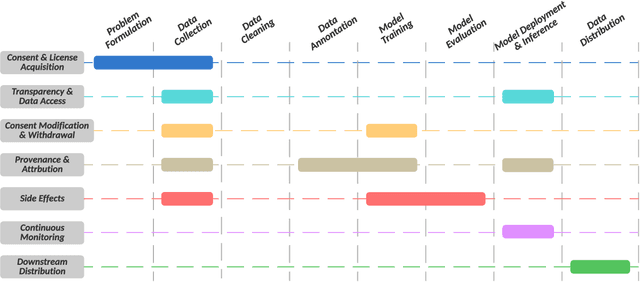
The advent of Generative AI has marked a significant milestone in artificial intelligence, demonstrating remarkable capabilities in generating realistic images, texts, and data patterns. However, these advancements come with heightened concerns over data privacy and copyright infringement, primarily due to the reliance on vast datasets for model training. Traditional approaches like differential privacy, machine unlearning, and data poisoning only offer fragmented solutions to these complex issues. Our paper delves into the multifaceted challenges of privacy and copyright protection within the data lifecycle. We advocate for integrated approaches that combines technical innovation with ethical foresight, holistically addressing these concerns by investigating and devising solutions that are informed by the lifecycle perspective. This work aims to catalyze a broader discussion and inspire concerted efforts towards data privacy and copyright integrity in Generative AI.
Test-takers have a say: understanding the implications of the use of AI in language tests
Jul 19, 2023
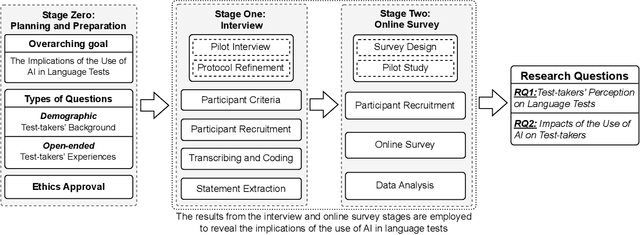

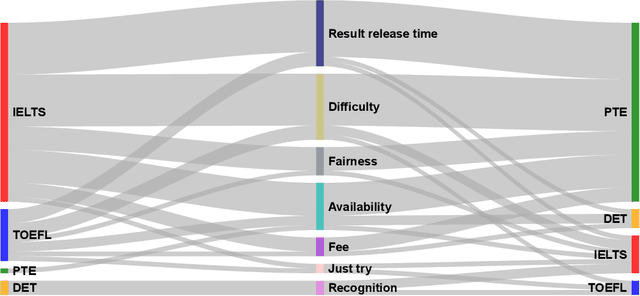
Language tests measure a person's ability to use a language in terms of listening, speaking, reading, or writing. Such tests play an integral role in academic, professional, and immigration domains, with entities such as educational institutions, professional accreditation bodies, and governments using them to assess candidate language proficiency. Recent advances in Artificial Intelligence (AI) and the discipline of Natural Language Processing have prompted language test providers to explore AI's potential applicability within language testing, leading to transformative activity patterns surrounding language instruction and learning. However, with concerns over AI's trustworthiness, it is imperative to understand the implications of integrating AI into language testing. This knowledge will enable stakeholders to make well-informed decisions, thus safeguarding community well-being and testing integrity. To understand the concerns and effects of AI usage in language tests, we conducted interviews and surveys with English test-takers. To the best of our knowledge, this is the first empirical study aimed at identifying the implications of AI adoption in language tests from a test-taker perspective. Our study reveals test-taker perceptions and behavioral patterns. Specifically, we identify that AI integration may enhance perceptions of fairness, consistency, and availability. Conversely, it might incite mistrust regarding reliability and interactivity aspects, subsequently influencing the behaviors and well-being of test-takers. These insights provide a better understanding of potential societal implications and assist stakeholders in making informed decisions concerning AI usage in language testing.
Right to be Forgotten in the Era of Large Language Models: Implications, Challenges, and Solutions
Jul 08, 2023


The Right to be Forgotten (RTBF) was first established as the result of the ruling of Google Spain SL, Google Inc. v AEPD, Mario Costeja Gonz\'alez, and was later included as the Right to Erasure under the General Data Protection Regulation (GDPR) of European Union to allow individuals the right to request personal data be deleted by organizations. Specifically for search engines, individuals can send requests to organizations to exclude their information from the query results. With the recent development of Large Language Models (LLMs) and their use in chatbots, LLM-enabled software systems have become popular. But they are not excluded from the RTBF. Compared with the indexing approach used by search engines, LLMs store, and process information in a completely different way. This poses new challenges for compliance with the RTBF. In this paper, we explore these challenges and provide our insights on how to implement technical solutions for the RTBF, including the use of machine unlearning, model editing, and prompting engineering.
To Be Forgotten or To Be Fair: Unveiling Fairness Implications of Machine Unlearning Methods
Feb 07, 2023The right to be forgotten (RTBF) is motivated by the desire of people not to be perpetually disadvantaged by their past deeds. For this, data deletion needs to be deep and permanent, and should be removed from machine learning models. Researchers have proposed machine unlearning algorithms which aim to erase specific data from trained models more efficiently. However, these methods modify how data is fed into the model and how training is done, which may subsequently compromise AI ethics from the fairness perspective. To help software engineers make responsible decisions when adopting these unlearning methods, we present the first study on machine unlearning methods to reveal their fairness implications. We designed and conducted experiments on two typical machine unlearning methods (SISA and AmnesiacML) along with a retraining method (ORTR) as baseline using three fairness datasets under three different deletion strategies. Experimental results show that under non-uniform data deletion, SISA leads to better fairness compared with ORTR and AmnesiacML, while initial training and uniform data deletion do not necessarily affect the fairness of all three methods. These findings have exposed an important research problem in software engineering, and can help practitioners better understand the potential trade-offs on fairness when considering solutions for RTBF.