 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockchain-Empowered Trustworthy Data Sharing: Fundamentals, Applications, and Challenges
Mar 12, 2023

Various data-sharing platforms have emerged with the growing public demand for open data and legislation mandating certain data to remain open. Most of these platforms remain opaque, leading to many questions about data accuracy, provenance and lineage, privacy implications, consent management, and the lack of fair incentives for data providers. With their transparency, immutability, non-repudiation, and decentralization properties, blockchains could not be more apt to answer these questions and enhance trust in a data-sharing platform. However, blockchains are not good at handling the four Vs of big data (i.e., volume, variety, velocity, and veracity) due to their limited performance, scalability, and high cost. Given many related works proposes blockchain-based trustworthy data-sharing solutions, there is increasing confusion and difficulties in understanding and selecting these technologies and platforms in terms of their sharing mechanisms, sharing services, quality of services, and applications. In this paper, we conduct a comprehensive survey on blockchain-based data-sharing architectures and applications to fill the gap. First, we present the foundations of blockchains and discuss the challenges of current data-sharing techniques. Second, we focus on the convergence of blockchain and data sharing to give a clear picture of this landscape and propose a reference architecture for blockchain-based data sharing. Third, we discuss the industrial applications of blockchain-based data sharing, ranging from healthcare and smart grid to transportation and decarbonization. For each application, we provide lessons learned for the deployment of Blockchain-based data sharing. Finally, we discuss research challenges and open research directions.
FedToken: Tokenized Incentives for Data Contribution in Federated Learning
Sep 20, 2022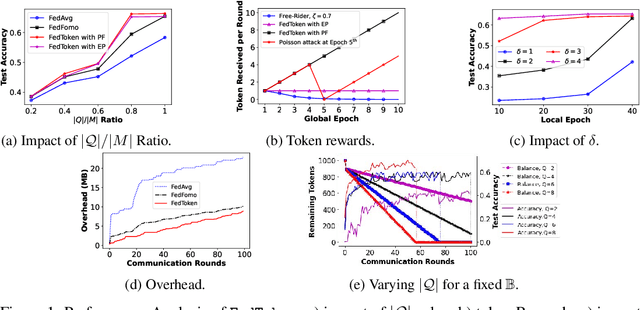
Incentives that compensate for the involved costs in the decentralized training of a Federated Learning (FL) model act as a key stimulus for clients' long-term participation. However, it is challenging to convince clients for quality participation in FL due to the absence of: (i) full information on the client's data quality and properties; (ii) the value of client's data contributions; and (iii) the trusted mechanism for monetary incentive offers. This often leads to poor efficiency in training and communication. While several works focus on strategic incentive designs and client selection to overcome this problem, there is a major knowledge gap in terms of an overall design tailored to the foreseen digital economy, including Web 3.0, while simultaneously meeting the learning objectives. To address this gap, we propose a contribution-based tokenized incentive scheme, namely \texttt{FedToken}, backed by blockchain technology that ensures fair allocation of tokens amongst the clients that corresponds to the valuation of their data during model training. Leveraging the engineered Shapley-based scheme, we first approximate the contribution of local models during model aggregation, then strategically schedule clients lowering the communication rounds for convergence and anchor ways to allocate \emph{affordable} tokens under a constrained monetary budget. Extensive simulations demonstrate the efficacy of our proposed method.
A Marketplace for Trading AI Models based on Blockchain and Incentives for IoT Data
Dec 06, 2021
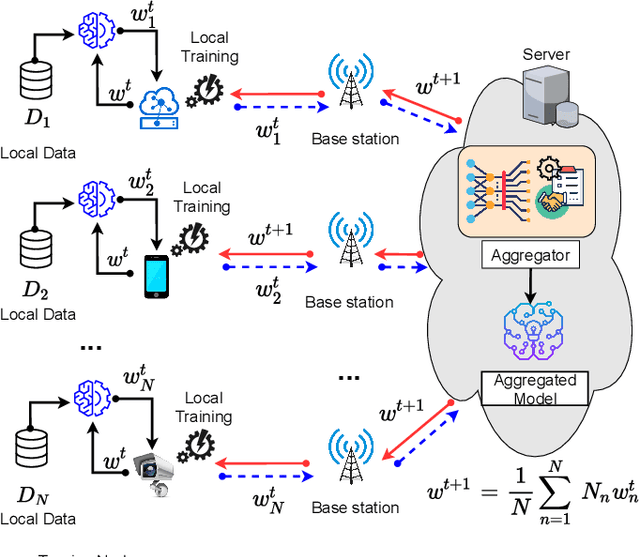
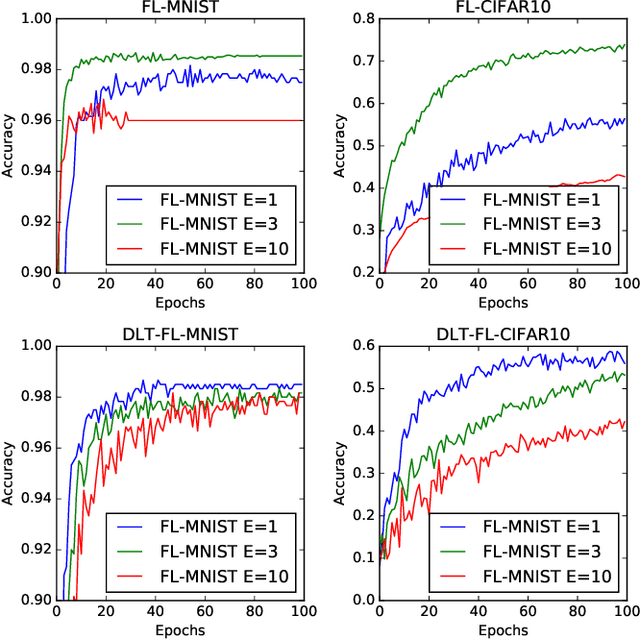
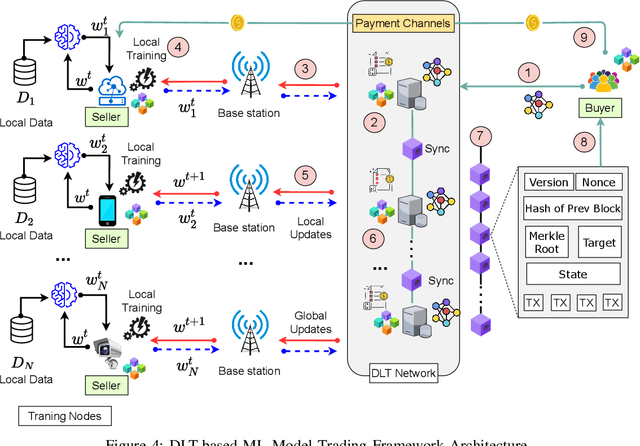
As Machine Learning (ML) models are becoming increasingly complex, one of the central challenges is their deployment at scale, such that companies and organizations can create value through Artificial Intelligence (AI). An emerging paradigm in ML is a federated approach where the learning model is delivered to a group of heterogeneous agents partially, allowing agents to train the model locally with their own data. However, the problem of valuation of models, as well the questions of incentives for collaborative training and trading of data/models, have received limited treatment in the literature. In this paper, a new ecosystem of ML model trading over a trusted Blockchain-based network is proposed. The buyer can acquire the model of interest from the ML market, and interested sellers spend local computations on their data to enhance that model's quality. In doing so, the proportional relation between the local data and the quality of trained models is considered, and the valuations of seller's data in training the models are estimated through the distributed Data Shapley Value (DSV). At the same time, the trustworthiness of the entire trading process is provided by the distributed Ledger Technology (DLT). Extensive experimental evaluation of the proposed approach shows a competitive run-time performance, with a 15\% drop in the cost of execution, and fairness in terms of incentives for the participants.