 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation of a Pretrained Cross-Lingual Language Model
Paper and Code
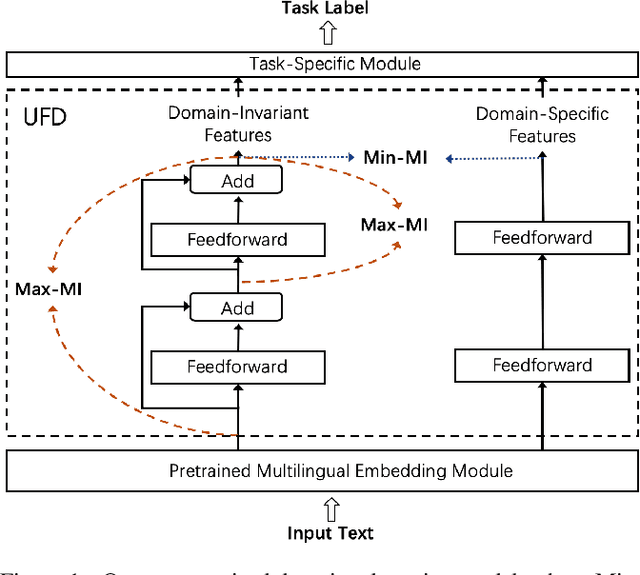



Recent research indicates that pretraining cross-lingual language models on large-scale unlabeled texts yields significant performance improvements over various cross-lingual and low-resource tasks. Through training on one hundred languages and terabytes of texts, cross-lingual language models have proven to be effective in leveraging high-resource languages to enhance low-resource language processing and outperform monolingual models. In this paper, we further investigate the cross-lingual and cross-domain (CLCD) setting when a pretrained cross-lingual language model needs to adapt to new domains. Specifically, we propose a novel unsupervised feature decomposition method that can automatically extract domain-specific features and domain-invariant features from the entangled pretrained cross-lingual representations, given unlabeled raw texts in the source language. Our proposed model leverages mutual information estimation to decompose the representations computed by a cross-lingual model into domain-invariant and domain-specific parts. Experimental results show that our proposed method achieves significant performance improvements over the state-of-the-art pretrained cross-lingual language model in the CLCD setting. The source code of this paper is publicly available at https://github.com/lijuntaopku/UFD.