 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Generative Transformer Is What You Need for Image Editing
May 11, 2026Diffusion models dominate image editing, yet their global denoising mechanism entangles edited regions with surrounding context, causing modifications to propagate into areas that should remain intact. We propose a fundamentally different approach by leveraging Masked Generative Transformers (MGTs), whose localized token-prediction paradigm naturally confines changes to intended regions. We present EditMGT, an MGT-based editing framework that is the first of its kind. Our approach employs multi-layer attention consolidation to aggregate cross-attention maps into precise edit localization signals, and region-hold sampling to explicitly prevent token flipping in non-target areas. To support training, we construct CrispEdit-2M, a 2M-sample high-resolution (>1024) editing dataset spanning seven categories. With only 960M parameters, EditMGT achieves state-of-the-art image similarity on multiple benchmarks while delivering 6x faster editing, demonstrating that MGTs offer a compelling alternative to diffusion-based editing.
Otherness as a Quality in Designing Expressive Robotic Touch
Apr 25, 2026Haptic technologies have advanced rapidly, yet exploration of robotic touch remains dominated by replicating realistic environmental cues or hand gestures, which narrows the design space and risks social resistance. This paper argues for alternatives: grounded in the notion of "otherness" from human-robot interaction (HRI), we propose treating robotic touch's inherent otherness as a design quality. Instead of being a limitation in pursuing realism, otherness can be embraced to elicit ambiguity and provoke alternative interpretations, fostering expressive and evocative robotic touch design. To develop this perspective, we analyze inspirational art and design precedents and four design research cases through a reflective Research through Design (RtD) approach. Through this analysis, we articulate a set of design languages structured around why otherness matters for touch meaning-making, how it can be shaped through design strategies, and where it can be embedded within robotic touch systems. We conclude by reflecting on the tensions and risks involved in designing robotic touch with otherness in mind.
Grounded Token Initialization for New Vocabulary in LMs for Generative Recommendation
Apr 02, 2026Language models (LMs) are increasingly extended with new learnable vocabulary tokens for domain-specific tasks, such as Semantic-ID tokens in generative recommendation. The standard practice initializes these new tokens as the mean of existing vocabulary embeddings, then relies on supervised fine-tuning to learn their representations. We present a systematic analysis of this strategy: through spectral and geometric diagnostics, we show that mean initialization collapses all new tokens into a degenerate subspace, erasing inter-token distinctions that subsequent fine-tuning struggles to fully recover. These findings suggest that \emph{token initialization} is a key bottleneck when extending LMs with new vocabularies. Motivated by this diagnosis, we propose the \emph{Grounded Token Initialization Hypothesis}: linguistically grounding novel tokens in the pretrained embedding space before fine-tuning better enables the model to leverage its general-purpose knowledge for novel-token domains. We operationalize this hypothesis as GTI (Grounded Token Initialization), a lightweight grounding stage that, prior to fine-tuning, maps new tokens to distinct, semantically meaningful locations in the pretrained embedding space using only paired linguistic supervision. Despite its simplicity, GTI outperforms both mean initialization and existing auxiliary-task adaptation methods in the majority of evaluation settings across multiple generative recommendation benchmarks, including industry-scale and public datasets. Further analyses show that grounded embeddings produce richer inter-token structure that persists through fine-tuning, corroborating the hypothesis that initialization quality is a key bottleneck in vocabulary extension.
EditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing
Dec 12, 2025Recent advances in diffusion models (DMs) have achieved exceptional visual quality in image editing tasks. However, the global denoising dynamics of DMs inherently conflate local editing targets with the full-image context, leading to unintended modifications in non-target regions. In this paper, we shift our attention beyond DMs and turn to Masked Generative Transformers (MGTs) as an alternative approach to tackle this challenge. By predicting multiple masked tokens rather than holistic refinement, MGTs exhibit a localized decoding paradigm that endows them with the inherent capacity to explicitly preserve non-relevant regions during the editing process. Building upon this insight, we introduce the first MGT-based image editing framework, termed EditMGT. We first demonstrate that MGT's cross-attention maps provide informative localization signals for localizing edit-relevant regions and devise a multi-layer attention consolidation scheme that refines these maps to achieve fine-grained and precise localization. On top of these adaptive localization results, we introduce region-hold sampling, which restricts token flipping within low-attention areas to suppress spurious edits, thereby confining modifications to the intended target regions and preserving the integrity of surrounding non-target areas. To train EditMGT, we construct CrispEdit-2M, a high-resolution dataset spanning seven diverse editing categories. Without introducing additional parameters, we adapt a pre-trained text-to-image MGT into an image editing model through attention injection. Extensive experiments across four standard benchmarks demonstrate that, with fewer than 1B parameters, our model achieves similarity performance while enabling 6 times faster editing. Moreover, it delivers comparable or superior editing quality, with improvements of 3.6% and 17.6% on style change and style transfer tasks, respectively.
GroundingGPT:Language Enhanced Multi-modal Grounding Model
Jan 30, 2024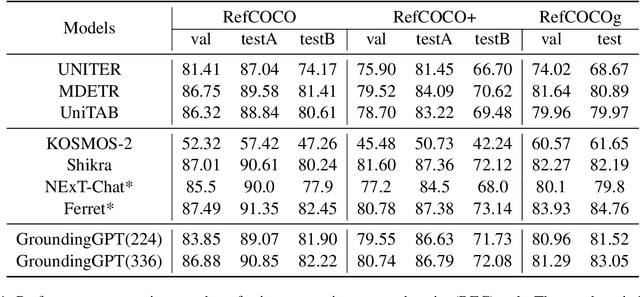
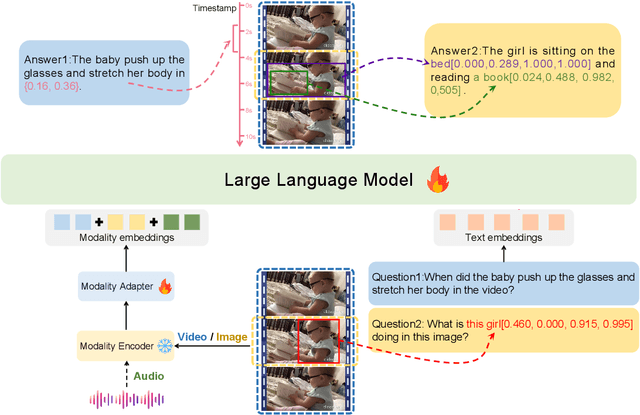
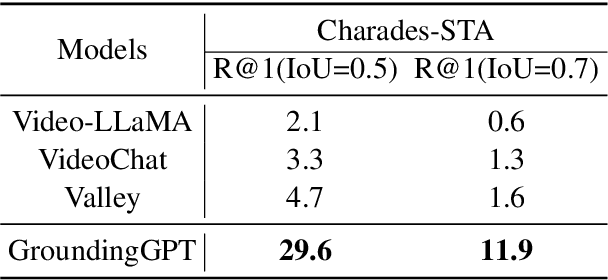
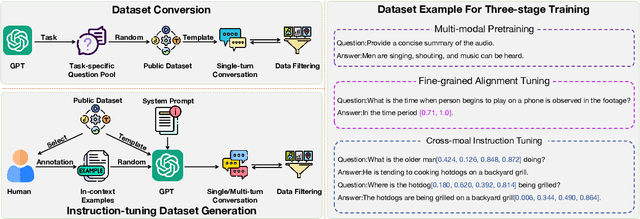
Multi-modal large language models have demonstrated impressive performance across various tasks in different modalities. However, existing multi-modal models primarily emphasize capturing global information within each modality while neglecting the importance of perceiving local information across modalities. Consequently, these models lack the ability to effectively understand the fine-grained details of input data, limiting their performance in tasks that require a more nuanced understanding. To address this limitation, there is a compelling need to develop models that enable fine-grained understanding across multiple modalities, thereby enhancing their applicability to a wide range of tasks. In this paper, we propose GroundingGPT, a language enhanced multi-modal grounding model. Beyond capturing global information like other multi-modal models, our proposed model excels at tasks demanding a detailed understanding of local information within the input. It demonstrates precise identification and localization of specific regions in images or moments in videos. To achieve this objective, we design a diversified dataset construction pipeline, resulting in a multi-modal, multi-granularity dataset for model training. The code, dataset, and demo of our model can be found at https: //github.com/lzw-lzw/GroundingGPT.
WAL-Net: Weakly supervised auxiliary task learning network for carotid plaques classification
Jan 27, 2024



The classification of carotid artery ultrasound images is a crucial means for diagnosing carotid plaques, holding significant clinical relevance for predicting the risk of stroke. Recent research suggests that utilizing plaque segmentation as an auxiliary task for classification can enhance performance by leveraging the correlation between segmentation and classification tasks. However, this approach relies on obtaining a substantial amount of challenging-to-acquire segmentation annotations. This paper proposes a novel weakly supervised auxiliary task learning network model (WAL-Net) to explore the interdependence between carotid plaque classification and segmentation tasks. The plaque classification task is primary task, while the plaque segmentation task serves as an auxiliary task, providing valuable information to enhance the performance of the primary task. Weakly supervised learning is adopted in the auxiliary task to completely break away from the dependence on segmentation annotations. Experiments and evaluations are conducted on a dataset comprising 1270 carotid plaque ultrasound images from Wuhan University Zhongnan Hospital. Results indicate that the proposed method achieved an approximately 1.3% improvement in carotid plaque classification accuracy compared to the baseline network. Specifically, the accuracy of mixed-echoic plaques classification increased by approximately 3.3%, demonstrating the effectiveness of our approach.
A multi-task learning framework for carotid plaque segmentation and classification from ultrasound images
Jul 02, 2023



Carotid plaque segmentation and classification play important roles in the treatment of atherosclerosis and assessment for risk of stroke. Although deep learning methods have been used for carotid plaque segmentation and classification, most focused on a single task and ignored the relationship between the segmentation and classification of carotid plaques. Therefore, we propose a multi-task learning framework for ultrasound carotid plaque segmentation and classification, which utilizes a region-weight module (RWM) and a sample-weight module (SWM) to exploit the correlation between these two tasks. The RWM provides a plaque regional prior knowledge to the classification task, while the SWM is designed to learn the categorical sample weight for the segmentation task. A total of 1270 2D ultrasound images of carotid plaques were collected from Zhongnan Hospital (Wuhan, China) for our experiments. The results of the experiments showed that the proposed method can significantly improve the performance compared to existing networks trained for a single task, with an accuracy of 85.82% for classification and a Dice similarity coefficient of 84.92% for segmentation. In the ablation study, the results demonstrated that both the designed RWM and SWM were beneficial in improving the network's performance. Therefore, we believe that the proposed method could be useful for carotid plaque analysis in clinical trials and practice.
Improving Self-training for Cross-lingual Named Entity Recognition with Contrastive and Prototype Learning
May 23, 2023In cross-lingual named entity recognition (NER), self-training is commonly used to bridge the linguistic gap by training on pseudo-labeled target-language data. However, due to sub-optimal performance on target languages, the pseudo labels are often noisy and limit the overall performance. In this work, we aim to improve self-training for cross-lingual NER by combining representation learning and pseudo label refinement in one coherent framework. Our proposed method, namely ContProto mainly comprises two components: (1) contrastive self-training and (2) prototype-based pseudo-labeling. Our contrastive self-training facilitates span classification by separating clusters of different classes, and enhances cross-lingual transferability by producing closely-aligned representations between the source and target language. Meanwhile, prototype-based pseudo-labeling effectively improves the accuracy of pseudo labels during training. We evaluate ContProto on multiple transfer pairs, and experimental results show our method brings in substantial improvements over current state-of-the-art methods.
ConNER: Consistency Training for Cross-lingual Named Entity Recognition
Nov 17, 2022Cross-lingual named entity recognition (NER) suffers from data scarcity in the target languages, especially under zero-shot settings. Existing translate-train or knowledge distillation methods attempt to bridge the language gap, but often introduce a high level of noise. To solve this problem, consistency training methods regularize the model to be robust towards perturbations on data or hidden states. However, such methods are likely to violate the consistency hypothesis, or mainly focus on coarse-grain consistency. We propose ConNER as a novel consistency training framework for cross-lingual NER, which comprises of: (1) translation-based consistency training on unlabeled target-language data, and (2) dropoutbased consistency training on labeled source-language data. ConNER effectively leverages unlabeled target-language data and alleviates overfitting on the source language to enhance the cross-lingual adaptability. Experimental results show our ConNER achieves consistent improvement over various baseline methods.
MReD: A Meta-Review Dataset for Controllable Text Generation
Oct 14, 2021
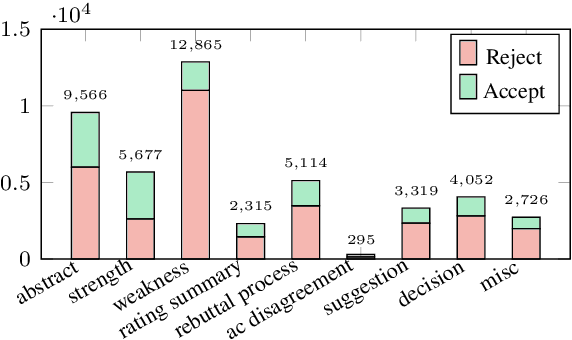
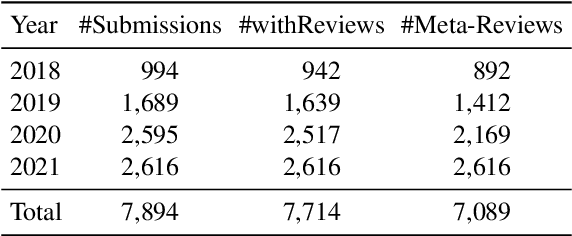
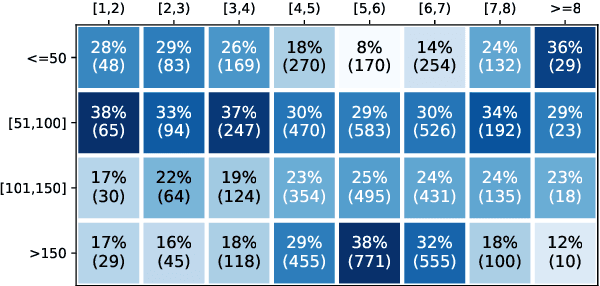
When directly using existing text generation datasets for controllable generation, we are facing the problem of not having the domain knowledge and thus the aspects that could be controlled are limited.A typical example is when using CNN/Daily Mail dataset for controllable text summarization, there is no guided information on the emphasis of summary sentences. A more useful text generator should leverage both the input text and control variables to guide the generation, which can only be built with deep understanding of the domain knowledge. Motivated by this vi-sion, our paper introduces a new text generation dataset, named MReD. Our new dataset consists of 7,089 meta-reviews and all its 45k meta-review sentences are manually annotated as one of the carefully defined 9 categories, including abstract, strength, decision, etc. We present experimental results on start-of-the-art summarization models, and propose methods for controlled generation on both extractive and abstractive models using our annotated data. By exploring various settings and analaysing the model behavior with respect to the control inputs, we demonstrate the challenges and values of our dataset. MReD allows us to have a better understanding of the meta-review corpora and enlarge the research room for controllable text generation.