 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAL-Net: Weakly supervised auxiliary task learning network for carotid plaques classification
Jan 27, 2024



The classification of carotid artery ultrasound images is a crucial means for diagnosing carotid plaques, holding significant clinical relevance for predicting the risk of stroke. Recent research suggests that utilizing plaque segmentation as an auxiliary task for classification can enhance performance by leveraging the correlation between segmentation and classification tasks. However, this approach relies on obtaining a substantial amount of challenging-to-acquire segmentation annotations. This paper proposes a novel weakly supervised auxiliary task learning network model (WAL-Net) to explore the interdependence between carotid plaque classification and segmentation tasks. The plaque classification task is primary task, while the plaque segmentation task serves as an auxiliary task, providing valuable information to enhance the performance of the primary task. Weakly supervised learning is adopted in the auxiliary task to completely break away from the dependence on segmentation annotations. Experiments and evaluations are conducted on a dataset comprising 1270 carotid plaque ultrasound images from Wuhan University Zhongnan Hospital. Results indicate that the proposed method achieved an approximately 1.3% improvement in carotid plaque classification accuracy compared to the baseline network. Specifically, the accuracy of mixed-echoic plaques classification increased by approximately 3.3%, demonstrating the effectiveness of our approach.
A multi-task learning framework for carotid plaque segmentation and classification from ultrasound images
Jul 02, 2023



Carotid plaque segmentation and classification play important roles in the treatment of atherosclerosis and assessment for risk of stroke. Although deep learning methods have been used for carotid plaque segmentation and classification, most focused on a single task and ignored the relationship between the segmentation and classification of carotid plaques. Therefore, we propose a multi-task learning framework for ultrasound carotid plaque segmentation and classification, which utilizes a region-weight module (RWM) and a sample-weight module (SWM) to exploit the correlation between these two tasks. The RWM provides a plaque regional prior knowledge to the classification task, while the SWM is designed to learn the categorical sample weight for the segmentation task. A total of 1270 2D ultrasound images of carotid plaques were collected from Zhongnan Hospital (Wuhan, China) for our experiments. The results of the experiments showed that the proposed method can significantly improve the performance compared to existing networks trained for a single task, with an accuracy of 85.82% for classification and a Dice similarity coefficient of 84.92% for segmentation. In the ablation study, the results demonstrated that both the designed RWM and SWM were beneficial in improving the network's performance. Therefore, we believe that the proposed method could be useful for carotid plaque analysis in clinical trials and practice.
Self-training with dual uncertainty for semi-supervised medical image segmentation
Apr 10, 2023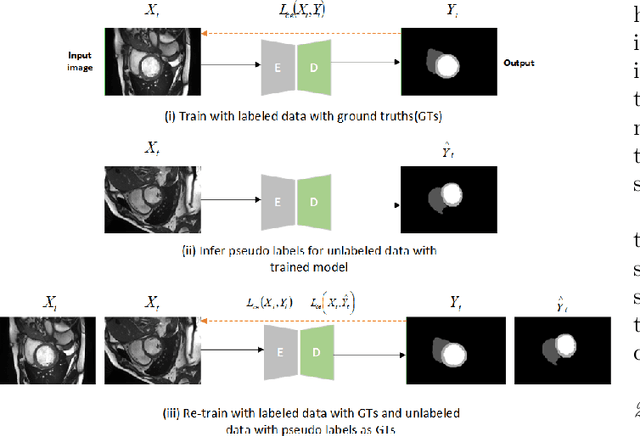
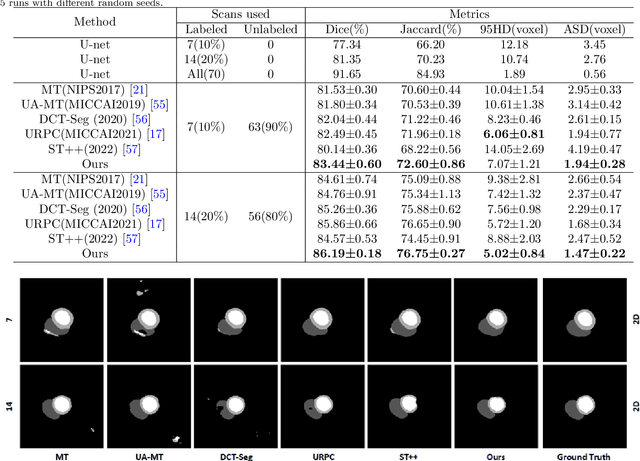
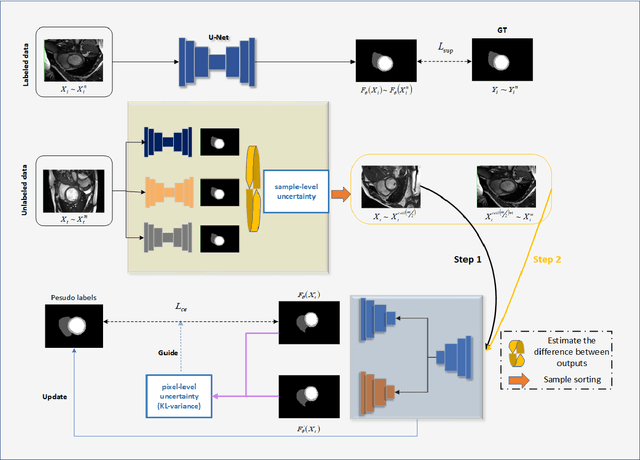
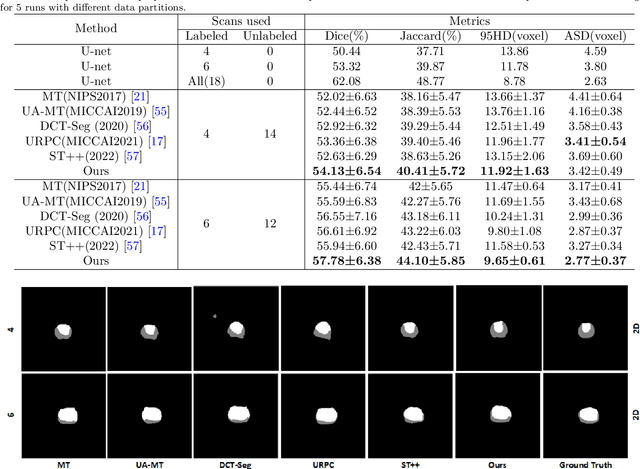
In the field of semi-supervised medical image segmentation, the shortage of labeled data is the fundamental problem. How to effectively learn image features from unlabeled images to improve segmentation accuracy is the main research direction in this field. Traditional self-training methods can partially solve the problem of insufficient labeled data by generating pseudo labels for iterative training. However, noise generated due to the model's uncertainty during training directly affects the segmentation results. Therefore, we added sample-level and pixel-level uncertainty to stabilize the training process based on the self-training framework. Specifically, we saved several moments of the model during pre-training, and used the difference between their predictions on unlabeled samples as the sample-level uncertainty estimate for that sample. Then, we gradually add unlabeled samples from easy to hard during training. At the same time, we added a decoder with different upsampling methods to the segmentation network and used the difference between the outputs of the two decoders as pixel-level uncertainty. In short, we selectively retrained unlabeled samples and assigned pixel-level uncertainty to pseudo labels to optimize the self-training process. We compared the segmentation results of our model with five semi-supervised approaches on the public 2017 ACDC dataset and 2018 Prostate dataset. Our proposed method achieves better segmentation performance on both datasets under the same settings, demonstrating its effectiveness, robustness, and potential transferability to other medical image segmentation tasks. Keywords: Medical image segmentation, semi-supervised learning, self-training, uncertainty estimation
HD-GCN:A Hybrid Diffusion Graph Convolutional Network
Mar 31, 2023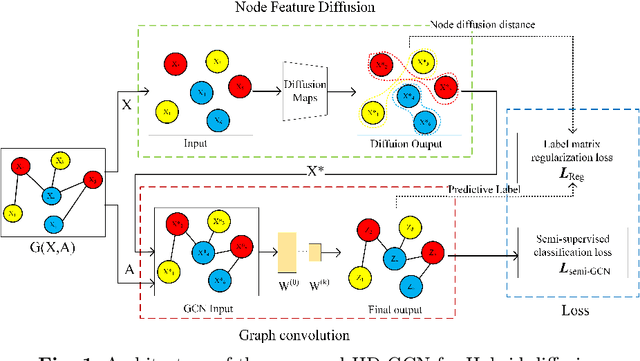
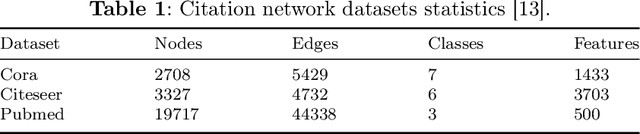
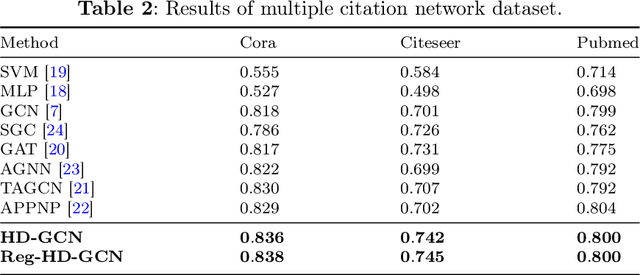

The information diffusion performance of GCN and its variant models is limited by the adjacency matrix, which can lower their performance. Therefore, we introduce a new framework for graph convolutional networks called Hybrid Diffusion-based Graph Convolutional Network (HD-GCN) to address the limitations of information diffusion caused by the adjacency matrix. In the HD-GCN framework, we initially utilize diffusion maps to facilitate the diffusion of information among nodes that are adjacent to each other in the feature space. This allows for the diffusion of information between similar points that may not have an adjacent relationship. Next, we utilize graph convolution to further propagate information among adjacent nodes after the diffusion maps, thereby enabling the spread of information among similar nodes that are adjacent in the graph. Finally, we employ the diffusion distances obtained through the use of diffusion maps to regularize and constrain the predicted labels of training nodes. This regularization method is then applied to the HD-GCN training, resulting in a smoother classification surface. The model proposed in this paper effectively overcomes the limitations of information diffusion imposed only by the adjacency matrix. HD-GCN utilizes hybrid diffusion by combining information diffusion between neighborhood nodes in the feature space and adjacent nodes in the adjacency matrix. This method allows for more comprehensive information propagation among nodes, resulting in improved model performance. We evaluated the performance of DM-GCN on three well-known citation network datasets and the results showed that the proposed framework is more effective than several graph-based semi-supervised learning methods.
A Safe Semi-supervised Graph Convolution Network
Jul 05, 2022
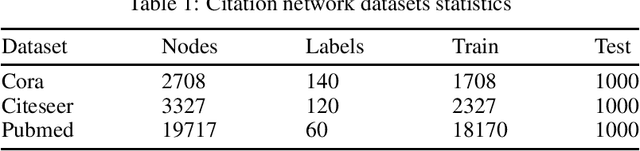
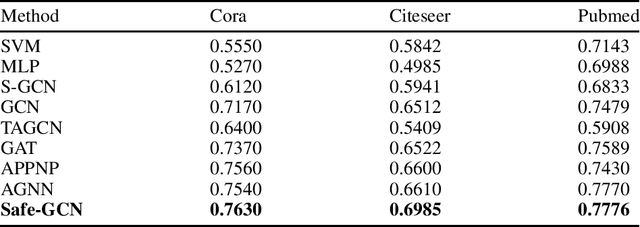
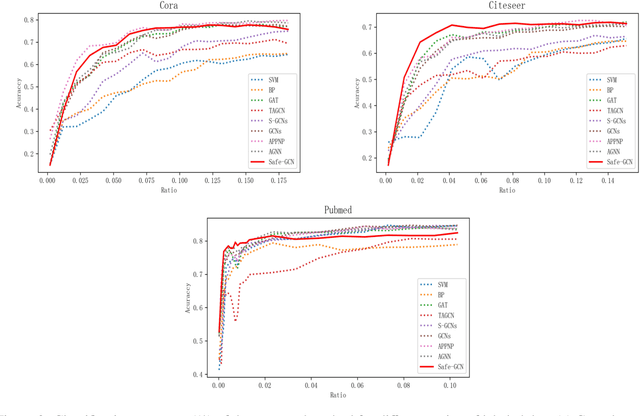
In the semi-supervised learning field, Graph Convolution Network (GCN), as a variant model of GNN, has achieved promising results for non-Euclidean data by introducing convolution into GNN. However, GCN and its variant models fail to safely use the information of risk unlabeled data, which will degrade the performance of semi-supervised learning. Therefore, we propose a Safe GCN framework (Safe-GCN) to improve the learning performance. In the Safe-GCN, we design an iterative process to label the unlabeled data. In each iteration, a GCN and its supervised version(S-GCN) are learned to find the unlabeled data with high confidence. The high-confidence unlabeled data and their pseudo labels are then added to the label set. Finally, both added unlabeled data and labeled ones are used to train a S-GCN which can achieve the safe exploration of the risk unlabeled data and enable safe use of large numbers of unlabeled data. The performance of Safe-GCN is evaluated on three well-known citation network datasets and the obtained results demonstrate the effectiveness of the proposed framework over several graph-based semi-supervised learning methods.