 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMReD: A Meta-Review Dataset for Controllable Text Generation
Paper and Code

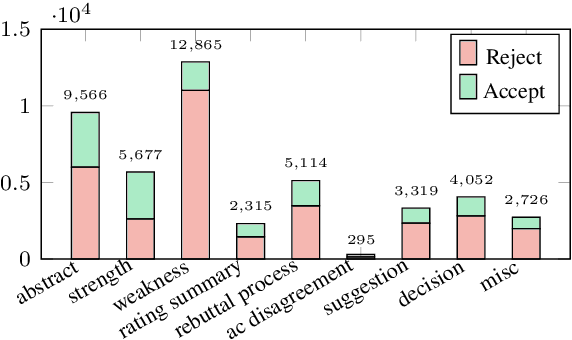
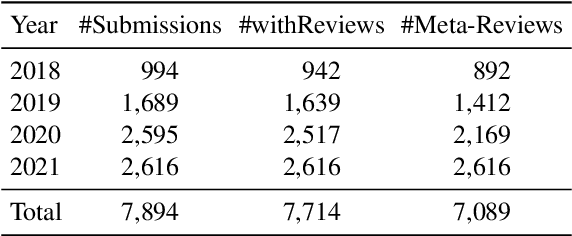
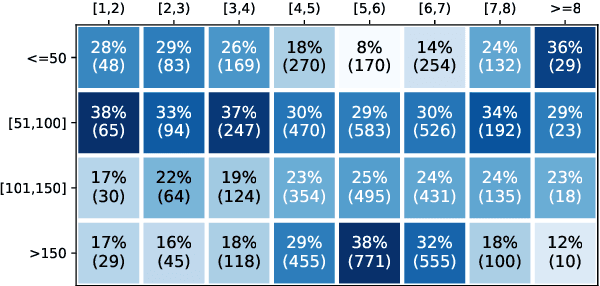
When directly using existing text generation datasets for controllable generation, we are facing the problem of not having the domain knowledge and thus the aspects that could be controlled are limited.A typical example is when using CNN/Daily Mail dataset for controllable text summarization, there is no guided information on the emphasis of summary sentences. A more useful text generator should leverage both the input text and control variables to guide the generation, which can only be built with deep understanding of the domain knowledge. Motivated by this vi-sion, our paper introduces a new text generation dataset, named MReD. Our new dataset consists of 7,089 meta-reviews and all its 45k meta-review sentences are manually annotated as one of the carefully defined 9 categories, including abstract, strength, decision, etc. We present experimental results on start-of-the-art summarization models, and propose methods for controlled generation on both extractive and abstractive models using our annotated data. By exploring various settings and analaysing the model behavior with respect to the control inputs, we demonstrate the challenges and values of our dataset. MReD allows us to have a better understanding of the meta-review corpora and enlarge the research room for controllable text generation.