 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroundingGPT:Language Enhanced Multi-modal Grounding Model
Jan 30, 2024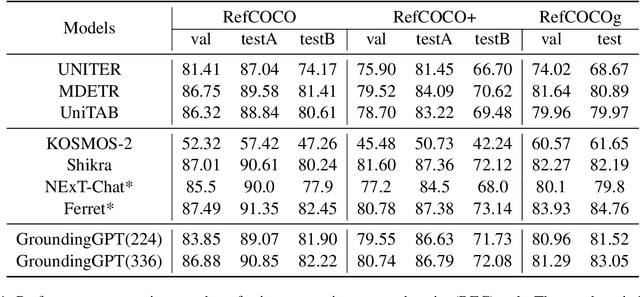
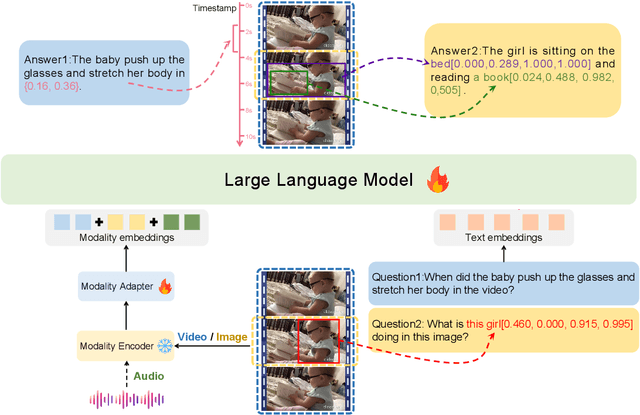
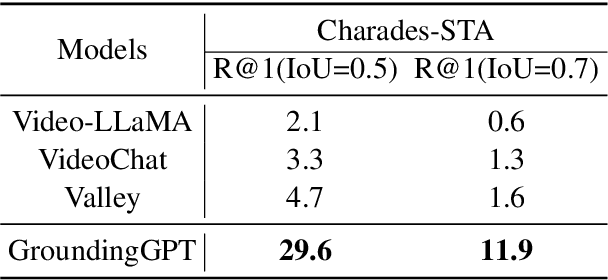
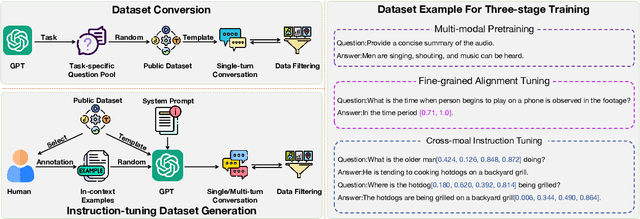
Multi-modal large language models have demonstrated impressive performance across various tasks in different modalities. However, existing multi-modal models primarily emphasize capturing global information within each modality while neglecting the importance of perceiving local information across modalities. Consequently, these models lack the ability to effectively understand the fine-grained details of input data, limiting their performance in tasks that require a more nuanced understanding. To address this limitation, there is a compelling need to develop models that enable fine-grained understanding across multiple modalities, thereby enhancing their applicability to a wide range of tasks. In this paper, we propose GroundingGPT, a language enhanced multi-modal grounding model. Beyond capturing global information like other multi-modal models, our proposed model excels at tasks demanding a detailed understanding of local information within the input. It demonstrates precise identification and localization of specific regions in images or moments in videos. To achieve this objective, we design a diversified dataset construction pipeline, resulting in a multi-modal, multi-granularity dataset for model training. The code, dataset, and demo of our model can be found at https: //github.com/lzw-lzw/GroundingGPT.