 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Capabilities of Vision-Language Models for Generalizable and Explainable Deepfake Detection
Mar 19, 2025Current vision-language models (VLMs) have demonstrated remarkable capabilities in understanding multimodal data, but their potential remains underexplored for deepfake detection due to the misaligned of their knowledge and forensics patterns. To this end, we present a novel paradigm that unlocks VLMs' potential capabilities through three components: (1) A knowledge-guided forgery adaptation module that aligns VLM's semantic space with forensic features through contrastive learning with external manipulation knowledge; (2) A multi-modal prompt tuning framework that jointly optimizes visual-textual embeddings for both localization and explainability; (3) An iterative refinement strategy enabling multi-turn dialog for evidence-based reasoning. Our framework includes a VLM-based Knowledge-guided Forgery Detector (KFD), a VLM image encoder, and a Large Language Model (LLM). The VLM image encoder extracts visual prompt embeddings from images, while the LLM receives visual and question prompt embeddings for inference. The KFD is used to calculate correlations between image features and pristine/deepfake class embeddings, enabling forgery classification and localization. The outputs from these components are used to construct forgery prompt embeddings. Finally, we feed these prompt embeddings into the LLM to generate textual detection responses to assist judgment. Extensive experiments on multiple benchmarks, including FF++, CDF2, DFD, DFDCP, and DFDC, demonstrate that our scheme surpasses state-of-the-art methods in generalization performance, while also supporting multi-turn dialogue capabilities.
Mercury: An Automated Remote Side-channel Attack to Nvidia Deep Learning Accelerator
Aug 02, 2023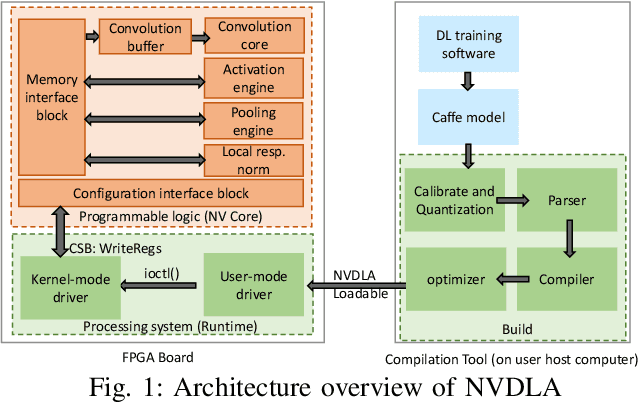
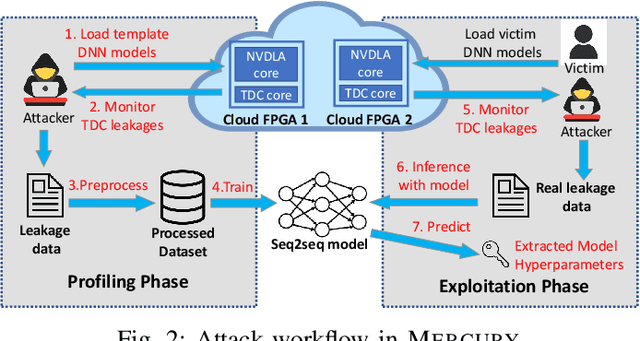
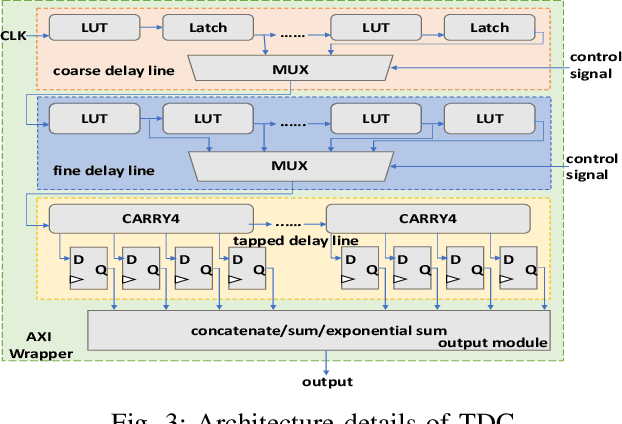
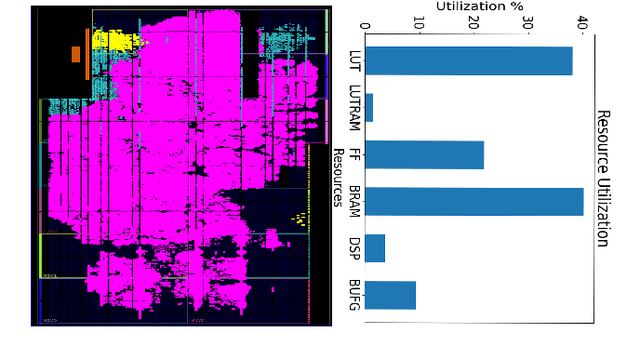
DNN accelerators have been widely deployed in many scenarios to speed up the inference process and reduce the energy consumption. One big concern about the usage of the accelerators is the confidentiality of the deployed models: model inference execution on the accelerators could leak side-channel information, which enables an adversary to preciously recover the model details. Such model extraction attacks can not only compromise the intellectual property of DNN models, but also facilitate some adversarial attacks. Although previous works have demonstrated a number of side-channel techniques to extract models from DNN accelerators, they are not practical for two reasons. (1) They only target simplified accelerator implementations, which have limited practicality in the real world. (2) They require heavy human analysis and domain knowledge. To overcome these limitations, this paper presents Mercury, the first automated remote side-channel attack against the off-the-shelf Nvidia DNN accelerator. The key insight of Mercury is to model the side-channel extraction process as a sequence-to-sequence problem. The adversary can leverage a time-to-digital converter (TDC) to remotely collect the power trace of the target model's inference. Then he uses a learning model to automatically recover the architecture details of the victim model from the power trace without any prior knowledge. The adversary can further use the attention mechanism to localize the leakage points that contribute most to the attack. Evaluation results indicate that Mercury can keep the error rate of model extraction below 1%.
Zero-Shot Text Classification via Self-Supervised Tuning
May 25, 2023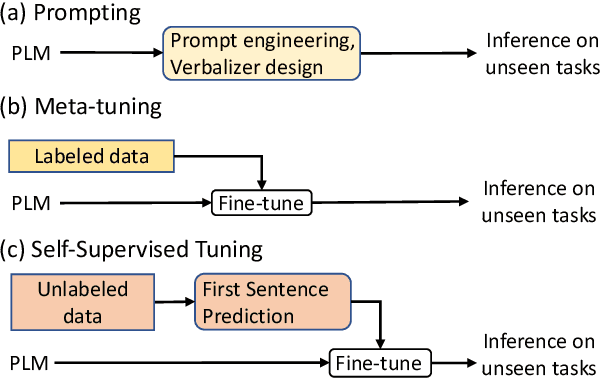



Existing solutions to zero-shot text classification either conduct prompting with pre-trained language models, which is sensitive to the choices of templates, or rely on large-scale annotated data of relevant tasks for meta-tuning. In this work, we propose a new paradigm based on self-supervised learning to solve zero-shot text classification tasks by tuning the language models with unlabeled data, called self-supervised tuning. By exploring the inherent structure of free texts, we propose a new learning objective called first sentence prediction to bridge the gap between unlabeled data and text classification tasks. After tuning the model to learn to predict the first sentence in a paragraph based on the rest, the model is able to conduct zero-shot inference on unseen tasks such as topic classification and sentiment analysis. Experimental results show that our model outperforms the state-of-the-art baselines on 7 out of 10 tasks. Moreover, the analysis reveals that our model is less sensitive to the prompt design. Our code and pre-trained models are publicly available at https://github.com/DAMO-NLP-SG/SSTuning .