 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning of Nonlinear Independent Representations
Paper and Code
Aug 11, 2024
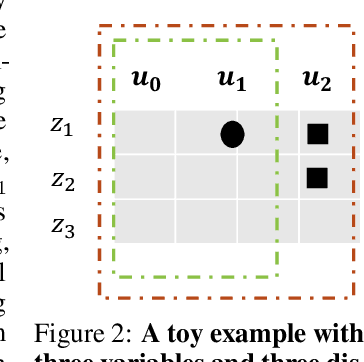
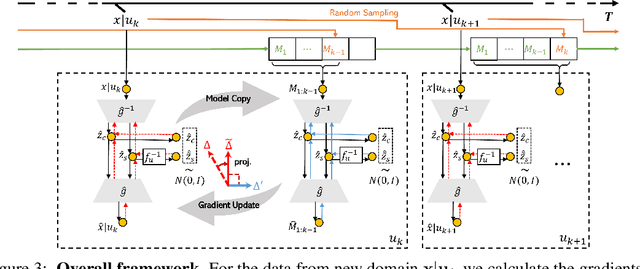
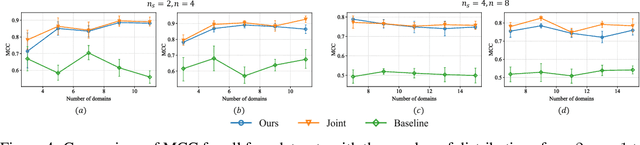
Identifying the causal relations between interested variables plays a pivotal role in representation learning as it provides deep insights into the dataset. Identifiability, as the central theme of this approach, normally hinges on leveraging data from multiple distributions (intervention, distribution shift, time series, etc.). Despite the exciting development in this field, a practical but often overlooked problem is: what if those distribution shifts happen sequentially? In contrast, any intelligence possesses the capacity to abstract and refine learned knowledge sequentially -- lifelong learning. In this paper, with a particular focus on the nonlinear independent component analysis (ICA) framework, we move one step forward toward the question of enabling models to learn meaningful (identifiable) representations in a sequential manner, termed continual causal representation learning. We theoretically demonstrate that model identifiability progresses from a subspace level to a component-wise level as the number of distributions increases. Empirically, we show that our method achieves performance comparable to nonlinear ICA methods trained jointly on multiple offline distributions and, surprisingly, the incoming new distribution does not necessarily benefit the identification of all latent variables.