 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSF-4D: A Progressive Sampling Framework for View Consistent 4D Editing
Mar 14, 2025Instruction-guided generative models, especially those using text-to-image (T2I) and text-to-video (T2V) diffusion frameworks, have advanced the field of content editing in recent years. To extend these capabilities to 4D scene, we introduce a progressive sampling framework for 4D editing (PSF-4D) that ensures temporal and multi-view consistency by intuitively controlling the noise initialization during forward diffusion. For temporal coherence, we design a correlated Gaussian noise structure that links frames over time, allowing each frame to depend meaningfully on prior frames. Additionally, to ensure spatial consistency across views, we implement a cross-view noise model, which uses shared and independent noise components to balance commonalities and distinct details among different views. To further enhance spatial coherence, PSF-4D incorporates view-consistent iterative refinement, embedding view-aware information into the denoising process to ensure aligned edits across frames and views. Our approach enables high-quality 4D editing without relying on external models, addressing key challenges in previous methods. Through extensive evaluation on multiple benchmarks and multiple editing aspects (e.g., style transfer, multi-attribute editing, object removal, local editing, etc.), we show the effectiveness of our proposed method. Experimental results demonstrate that our proposed method outperforms state-of-the-art 4D editing methods in diverse benchmarks.
Query Quantized Neural SLAM
Dec 21, 2024



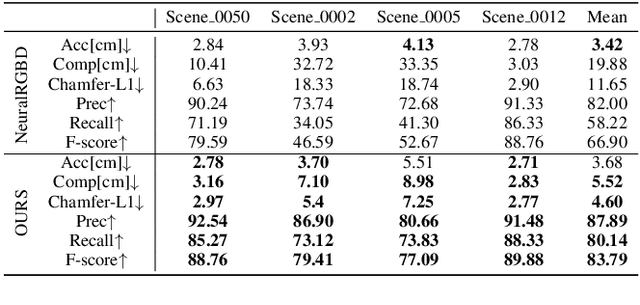
Neural implicit representations have shown remarkable abilities in jointly modeling geometry, color, and camera poses in simultaneous localization and mapping (SLAM). Current methods use coordinates, positional encodings, or other geometry features as input to query neural implicit functions for signed distances and color which produce rendering errors to drive the optimization in overfitting image observations. However, due to the run time efficiency requirement in SLAM systems, we are merely allowed to conduct optimization on each frame in few iterations, which is far from enough for neural networks to overfit these queries. The underfitting usually results in severe drifts in camera tracking and artifacts in reconstruction. To resolve this issue, we propose query quantized neural SLAM which uses quantized queries to reduce variations of input for much easier and faster overfitting a frame. To this end, we quantize a query into a discrete representation with a set of codes, and only allow neural networks to observe a finite number of variations. This allows neural networks to become increasingly familiar with these codes after overfitting more and more previous frames. Moreover, we also introduce novel initialization, losses, and argumentation to stabilize the optimization with significant uncertainty in the early optimization stage, constrain the optimization space, and estimate camera poses more accurately. We justify the effectiveness of each design and report visual and numerical comparisons on widely used benchmarks to show our superiority over the latest methods in both reconstruction and camera tracking.
Sensing Surface Patches in Volume Rendering for Inferring Signed Distance Functions
Dec 21, 2024


It is vital to recover 3D geometry from multi-view RGB images in many 3D computer vision tasks. The latest methods infer the geometry represented as a signed distance field by minimizing the rendering error on the field through volume rendering. However, it is still challenging to explicitly impose constraints on surfaces for inferring more geometry details due to the limited ability of sensing surfaces in volume rendering. To resolve this problem, we introduce a method to infer signed distance functions (SDFs) with a better sense of surfaces through volume rendering. Using the gradients and signed distances, we establish a small surface patch centered at the estimated intersection along a ray by pulling points randomly sampled nearby. Hence, we are able to explicitly impose surface constraints on the sensed surface patch, such as multi-view photo consistency and supervision from depth or normal priors, through volume rendering. We evaluate our method by numerical and visual comparisons on scene benchmarks. Our superiority over the latest methods justifies our effectiveness.
EVLM: Self-Reflective Multimodal Reasoning for Cross-Dimensional Visual Editing
Dec 13, 2024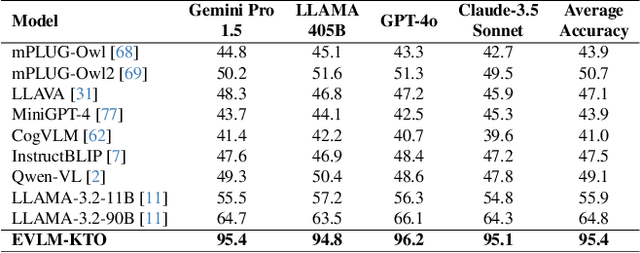



Editing complex visual content based on ambiguous instructions remains a challenging problem in vision-language modeling. While existing models can contextualize content, they often struggle to grasp the underlying intent within a reference image or scene, leading to misaligned edits. We introduce the Editing Vision-Language Model (EVLM), a system designed to interpret such instructions in conjunction with reference visuals, producing precise and context-aware editing prompts. Leveraging Chain-of-Thought (CoT) reasoning and KL-Divergence Target Optimization (KTO) alignment technique, EVLM captures subjective editing preferences without requiring binary labels. Fine-tuned on a dataset of 30,000 CoT examples, with rationale paths rated by human evaluators, EVLM demonstrates substantial improvements in alignment with human intentions. Experiments across image, video, 3D, and 4D editing tasks show that EVLM generates coherent, high-quality instructions, supporting a scalable framework for complex vision-language applications.
NASM: Neural Anisotropic Surface Meshing
Oct 30, 2024This paper introduces a new learning-based method, NASM, for anisotropic surface meshing. Our key idea is to propose a graph neural network to embed an input mesh into a high-dimensional (high-d) Euclidean embedding space to preserve curvature-based anisotropic metric by using a dot product loss between high-d edge vectors. This can dramatically reduce the computational time and increase the scalability. Then, we propose a novel feature-sensitive remeshing on the generated high-d embedding to automatically capture sharp geometric features. We define a high-d normal metric, and then derive an automatic differentiation on a high-d centroidal Voronoi tessellation (CVT) optimization with the normal metric to simultaneously preserve geometric features and curvature anisotropy that exhibit in the original 3D shapes. To our knowledge, this is the first time that a deep learning framework and a large dataset are proposed to construct a high-d Euclidean embedding space for 3D anisotropic surface meshing. Experimental results are evaluated and compared with the state-of-the-art in anisotropic surface meshing on a large number of surface models from Thingi10K dataset as well as tested on extensive unseen 3D shapes from Multi-Garment Network dataset and FAUST human dataset.
3DEgo: 3D Editing on the Go!
Jul 14, 2024We introduce 3DEgo to address a novel problem of directly synthesizing photorealistic 3D scenes from monocular videos guided by textual prompts. Conventional methods construct a text-conditioned 3D scene through a three-stage process, involving pose estimation using Structure-from-Motion (SfM) libraries like COLMAP, initializing the 3D model with unedited images, and iteratively updating the dataset with edited images to achieve a 3D scene with text fidelity. Our framework streamlines the conventional multi-stage 3D editing process into a single-stage workflow by overcoming the reliance on COLMAP and eliminating the cost of model initialization. We apply a diffusion model to edit video frames prior to 3D scene creation by incorporating our designed noise blender module for enhancing multi-view editing consistency, a step that does not require additional training or fine-tuning of T2I diffusion models. 3DEgo utilizes 3D Gaussian Splatting to create 3D scenes from the multi-view consistent edited frames, capitalizing on the inherent temporal continuity and explicit point cloud data. 3DEgo demonstrates remarkable editing precision, speed, and adaptability across a variety of video sources, as validated by extensive evaluations on six datasets, including our own prepared GS25 dataset. Project Page: https://3dego.github.io/
Free-Editor: Zero-shot Text-driven 3D Scene Editing
Dec 21, 2023



Text-to-Image (T2I) diffusion models have gained popularity recently due to their multipurpose and easy-to-use nature, e.g. image and video generation as well as editing. However, training a diffusion model specifically for 3D scene editing is not straightforward due to the lack of large-scale datasets. To date, editing 3D scenes requires either re-training the model to adapt to various 3D edited scenes or design-specific methods for each special editing type. Furthermore, state-of-the-art (SOTA) methods require multiple synchronized edited images from the same scene to facilitate the scene editing. Due to the current limitations of T2I models, it is very challenging to apply consistent editing effects to multiple images, i.e. multi-view inconsistency in editing. This in turn compromises the desired 3D scene editing performance if these images are used. In our work, we propose a novel training-free 3D scene editing technique, Free-Editor, which allows users to edit 3D scenes without further re-training the model during test time. Our proposed method successfully avoids the multi-view style inconsistency issue in SOTA methods with the help of a "single-view editing" scheme. Specifically, we show that editing a particular 3D scene can be performed by only modifying a single view. To this end, we introduce an Edit Transformer that enforces intra-view consistency and inter-view style transfer by utilizing self- and cross-attention, respectively. Since it is no longer required to re-train the model and edit every view in a scene, the editing time, as well as memory resources, are reduced significantly, e.g., the runtime being $\sim \textbf{20} \times$ faster than SOTA. We have conducted extensive experiments on a wide range of benchmark datasets and achieve diverse editing capabilities with our proposed technique.
LatentEditor: Text Driven Local Editing of 3D Scenes
Dec 18, 2023While neural fields have made significant strides in view synthesis and scene reconstruction, editing them poses a formidable challenge due to their implicit encoding of geometry and texture information from multi-view inputs. In this paper, we introduce \textsc{LatentEditor}, an innovative framework designed to empower users with the ability to perform precise and locally controlled editing of neural fields using text prompts. Leveraging denoising diffusion models, we successfully embed real-world scenes into the latent space, resulting in a faster and more adaptable NeRF backbone for editing compared to traditional methods. To enhance editing precision, we introduce a delta score to calculate the 2D mask in the latent space that serves as a guide for local modifications while preserving irrelevant regions. Our novel pixel-level scoring approach harnesses the power of InstructPix2Pix (IP2P) to discern the disparity between IP2P conditional and unconditional noise predictions in the latent space. The edited latents conditioned on the 2D masks are then iteratively updated in the training set to achieve 3D local editing. Our approach achieves faster editing speeds and superior output quality compared to existing 3D editing models, bridging the gap between textual instructions and high-quality 3D scene editing in latent space. We show the superiority of our approach on four benchmark 3D datasets, LLFF, IN2N, NeRFStudio and NeRF-Art.
CEFHRI: A Communication Efficient Federated Learning Framework for Recognizing Industrial Human-Robot Interaction
Aug 29, 2023



Human-robot interaction (HRI) is a rapidly growing field that encompasses social and industrial applications. Machine learning plays a vital role in industrial HRI by enhancing the adaptability and autonomy of robots in complex environments. However, data privacy is a crucial concern in the interaction between humans and robots, as companies need to protect sensitive data while machine learning algorithms require access to large datasets. Federated Learning (FL) offers a solution by enabling the distributed training of models without sharing raw data. Despite extensive research on Federated learning (FL) for tasks such as natural language processing (NLP) and image classification, the question of how to use FL for HRI remains an open research problem. The traditional FL approach involves transmitting large neural network parameter matrices between the server and clients, which can lead to high communication costs and often becomes a bottleneck in FL. This paper proposes a communication-efficient FL framework for human-robot interaction (CEFHRI) to address the challenges of data heterogeneity and communication costs. The framework leverages pre-trained models and introduces a trainable spatiotemporal adapter for video understanding tasks in HRI. Experimental results on three human-robot interaction benchmark datasets: HRI30, InHARD, and COIN demonstrate the superiority of CEFHRI over full fine-tuning in terms of communication costs. The proposed methodology provides a secure and efficient approach to HRI federated learning, particularly in industrial environments with data privacy concerns and limited communication bandwidth. Our code is available at https://github.com/umarkhalidAI/CEFHRI-Efficient-Federated-Learning.
Coordinate Quantized Neural Implicit Representations for Multi-view Reconstruction
Aug 21, 2023



In recent years, huge progress has been made on learning neural implicit representations from multi-view images for 3D reconstruction. As an additional input complementing coordinates, using sinusoidal functions as positional encodings plays a key role in revealing high frequency details with coordinate-based neural networks. However, high frequency positional encodings make the optimization unstable, which results in noisy reconstructions and artifacts in empty space. To resolve this issue in a general sense, we introduce to learn neural implicit representations with quantized coordinates, which reduces the uncertainty and ambiguity in the field during optimization. Instead of continuous coordinates, we discretize continuous coordinates into discrete coordinates using nearest interpolation among quantized coordinates which are obtained by discretizing the field in an extremely high resolution. We use discrete coordinates and their positional encodings to learn implicit functions through volume rendering. This significantly reduces the variations in the sample space, and triggers more multi-view consistency constraints on intersections of rays from different views, which enables to infer implicit function in a more effective way. Our quantized coordinates do not bring any computational burden, and can seamlessly work upon the latest methods. Our evaluations under the widely used benchmarks show our superiority over the state-of-the-art. Our code is available at https://github.com/MachinePerceptionLab/CQ-NIR.