 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Hallucinations in LLMs via Factuality-Aware Preference Learning
Jan 06, 2026Preference alignment methods such as RLHF and Direct Preference Optimization (DPO) improve instruction following, but they can also reinforce hallucinations when preference judgments reward fluency and confidence over factual correctness. We introduce F-DPO (Factuality-aware Direct Preference Optimization), a simple extension of DPO that uses only binary factuality labels. F-DPO (i) applies a label-flipping transformation that corrects misordered preference pairs so the chosen response is never less factual than the rejected one, and (ii) adds a factuality-aware margin that emphasizes pairs with clear correctness differences, while reducing to standard DPO when both responses share the same factuality. We construct factuality-aware preference data by augmenting DPO pairs with binary factuality indicators and synthetic hallucinated variants. Across seven open-weight LLMs (1B-14B), F-DPO consistently improves factuality and reduces hallucination rates relative to both base models and standard DPO. On Qwen3-8B, F-DPO reduces hallucination rates by five times (from 0.424 to 0.084) while improving factuality scores by 50 percent (from 5.26 to 7.90). F-DPO also generalizes to out-of-distribution benchmarks: on TruthfulQA, Qwen2.5-14B achieves plus 17 percent MC1 accuracy (0.500 to 0.585) and plus 49 percent MC2 accuracy (0.357 to 0.531). F-DPO requires no auxiliary reward model, token-level annotations, or multi-stage training.
PSF-4D: A Progressive Sampling Framework for View Consistent 4D Editing
Mar 14, 2025Instruction-guided generative models, especially those using text-to-image (T2I) and text-to-video (T2V) diffusion frameworks, have advanced the field of content editing in recent years. To extend these capabilities to 4D scene, we introduce a progressive sampling framework for 4D editing (PSF-4D) that ensures temporal and multi-view consistency by intuitively controlling the noise initialization during forward diffusion. For temporal coherence, we design a correlated Gaussian noise structure that links frames over time, allowing each frame to depend meaningfully on prior frames. Additionally, to ensure spatial consistency across views, we implement a cross-view noise model, which uses shared and independent noise components to balance commonalities and distinct details among different views. To further enhance spatial coherence, PSF-4D incorporates view-consistent iterative refinement, embedding view-aware information into the denoising process to ensure aligned edits across frames and views. Our approach enables high-quality 4D editing without relying on external models, addressing key challenges in previous methods. Through extensive evaluation on multiple benchmarks and multiple editing aspects (e.g., style transfer, multi-attribute editing, object removal, local editing, etc.), we show the effectiveness of our proposed method. Experimental results demonstrate that our proposed method outperforms state-of-the-art 4D editing methods in diverse benchmarks.
EVLM: Self-Reflective Multimodal Reasoning for Cross-Dimensional Visual Editing
Dec 13, 2024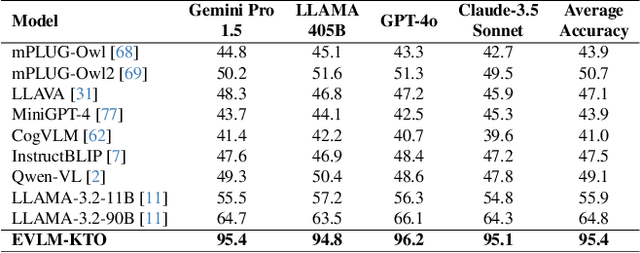



Editing complex visual content based on ambiguous instructions remains a challenging problem in vision-language modeling. While existing models can contextualize content, they often struggle to grasp the underlying intent within a reference image or scene, leading to misaligned edits. We introduce the Editing Vision-Language Model (EVLM), a system designed to interpret such instructions in conjunction with reference visuals, producing precise and context-aware editing prompts. Leveraging Chain-of-Thought (CoT) reasoning and KL-Divergence Target Optimization (KTO) alignment technique, EVLM captures subjective editing preferences without requiring binary labels. Fine-tuned on a dataset of 30,000 CoT examples, with rationale paths rated by human evaluators, EVLM demonstrates substantial improvements in alignment with human intentions. Experiments across image, video, 3D, and 4D editing tasks show that EVLM generates coherent, high-quality instructions, supporting a scalable framework for complex vision-language applications.
3DEgo: 3D Editing on the Go!
Jul 14, 2024We introduce 3DEgo to address a novel problem of directly synthesizing photorealistic 3D scenes from monocular videos guided by textual prompts. Conventional methods construct a text-conditioned 3D scene through a three-stage process, involving pose estimation using Structure-from-Motion (SfM) libraries like COLMAP, initializing the 3D model with unedited images, and iteratively updating the dataset with edited images to achieve a 3D scene with text fidelity. Our framework streamlines the conventional multi-stage 3D editing process into a single-stage workflow by overcoming the reliance on COLMAP and eliminating the cost of model initialization. We apply a diffusion model to edit video frames prior to 3D scene creation by incorporating our designed noise blender module for enhancing multi-view editing consistency, a step that does not require additional training or fine-tuning of T2I diffusion models. 3DEgo utilizes 3D Gaussian Splatting to create 3D scenes from the multi-view consistent edited frames, capitalizing on the inherent temporal continuity and explicit point cloud data. 3DEgo demonstrates remarkable editing precision, speed, and adaptability across a variety of video sources, as validated by extensive evaluations on six datasets, including our own prepared GS25 dataset. Project Page: https://3dego.github.io/
Interpretation of Chest x-rays affected by bullets using deep transfer learning
Mar 25, 2022



The potential of deep learning, especially in medical imaging, initiated astonishing results and improved the methodologies after every passing day. Deep learning in radiology provides the opportunity to classify, detect and segment different diseases automatically. In the proposed study, we worked on a non-trivial aspect of medical imaging where we classified and localized the X-Rays affected by bullets. We tested Images on different classification and localization models to get considerable accuracy. The replicated data set used in the study was replicated on different images of chest X-Rays. The proposed model worked not only on chest radiographs but other body organs X-rays like leg, abdomen, head, even the training dataset based on chest radiographs. Custom models have been used for classification and localization purposes after tuning parameters. Finally, the results of our findings manifested using different frameworks. This might assist the research enlightening towards this field. To the best of our knowledge, this is the first study on the detection and classification of radiographs affected by bullets using deep learning.