 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVLM: Self-Reflective Multimodal Reasoning for Cross-Dimensional Visual Editing
Paper and Code
Dec 13, 2024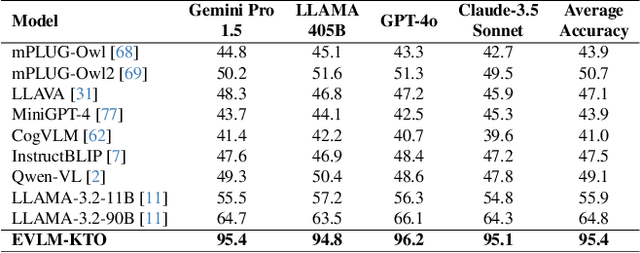



Editing complex visual content based on ambiguous instructions remains a challenging problem in vision-language modeling. While existing models can contextualize content, they often struggle to grasp the underlying intent within a reference image or scene, leading to misaligned edits. We introduce the Editing Vision-Language Model (EVLM), a system designed to interpret such instructions in conjunction with reference visuals, producing precise and context-aware editing prompts. Leveraging Chain-of-Thought (CoT) reasoning and KL-Divergence Target Optimization (KTO) alignment technique, EVLM captures subjective editing preferences without requiring binary labels. Fine-tuned on a dataset of 30,000 CoT examples, with rationale paths rated by human evaluators, EVLM demonstrates substantial improvements in alignment with human intentions. Experiments across image, video, 3D, and 4D editing tasks show that EVLM generates coherent, high-quality instructions, supporting a scalable framework for complex vision-language applications.