 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Agents Enable User-Governed Personalization Beyond Platform Boundaries
May 10, 2026Personalization today is fundamentally platform-centric: services build user representations from the behavioral fragments they observe. Yet no platform can construct a complete picture of the user, as competitive incentives, legal constraints, user privacy concerns, and epistemic limits create persistent data barriers. This paper argues for a shift from platform-centric personalization to user-governed personalization, where only the user can integrate fragmented contexts across platforms and the offline world. The key asymmetry lies in data access: only users can aggregate their own cross-platform and offline information. Large language model (LLM) agents make such integration practically feasible for the first time by enabling reasoning over heterogeneous personal data and transforming users' cross-context information into actionable personalization capabilities. We provide proof-of-concept evidence that users equipped with cross-platform data exports and an off-the-shelf LLM agent can outperform single-platform personalization baselines. We conclude by outlining a research agenda for building scalable user-governed personalization systems.
GaussianGrow: Geometry-aware Gaussian Growing from 3D Point Clouds with Text Guidance
Apr 07, 20263D Gaussian Splatting has demonstrated superior performance in rendering efficiency and quality, yet the generation of 3D Gaussians still remains a challenge without proper geometric priors. Existing methods have explored predicting point maps as geometric references for inferring Gaussian primitives, while the unreliable estimated geometries may lead to poor generations. In this work, we introduce GaussianGrow, a novel approach that generates 3D Gaussians by learning to grow them from easily accessible 3D point clouds, naturally enforcing geometric accuracy in Gaussian generation. Specifically, we design a text-guided Gaussian growing scheme that leverages a multi-view diffusion model to synthesize consistent appearances from input point clouds for supervision. To mitigate artifacts caused by fusing neighboring views, we constrain novel views generated at non-preset camera poses identified in overlapping regions across different views. For completing the hard-to-observe regions, we propose to iteratively detect the camera pose by observing the largest un-grown regions in point clouds and inpainting them by inpainting the rendered view with a pretrained 2D diffusion model. The process continues until complete Gaussians are generated. We extensively evaluate GaussianGrow on text-guided Gaussian generation from synthetic and even real-scanned point clouds. Project Page: https://weiqi-zhang.github.io/GaussianGrow
MoRe: Motion-aware Feed-forward 4D Reconstruction Transformer
Mar 05, 2026Reconstructing dynamic 4D scenes remains challenging due to the presence of moving objects that corrupt camera pose estimation. Existing optimization methods alleviate this issue with additional supervision, but they are mostly computationally expensive and impractical in real-time applications. To address these limitations, we propose MoRe, a feedforward 4D reconstruction network that efficiently recovers dynamic 3D scenes from monocular videos. Built upon a strong static reconstruction backbone, MoRe employs an attention-forcing strategy to disentangle dynamic motion from static structure. To further enhance robustness, we fine-tune the model on large-scale, diverse datasets encompassing both dynamic and static scenes. Moreover, our grouped causal attention captures temporal dependencies and adapts to varying token lengths across frames, ensuring temporally coherent geometry reconstruction. Extensive experiments on multiple benchmarks demonstrate that MoRe achieves high-quality dynamic reconstructions with exceptional efficiency.
GAP: Gaussianize Any Point Clouds with Text Guidance
Aug 07, 20253D Gaussian Splatting (3DGS) has demonstrated its advantages in achieving fast and high-quality rendering. As point clouds serve as a widely-used and easily accessible form of 3D representation, bridging the gap between point clouds and Gaussians becomes increasingly important. Recent studies have explored how to convert the colored points into Gaussians, but directly generating Gaussians from colorless 3D point clouds remains an unsolved challenge. In this paper, we propose GAP, a novel approach that gaussianizes raw point clouds into high-fidelity 3D Gaussians with text guidance. Our key idea is to design a multi-view optimization framework that leverages a depth-aware image diffusion model to synthesize consistent appearances across different viewpoints. To ensure geometric accuracy, we introduce a surface-anchoring mechanism that effectively constrains Gaussians to lie on the surfaces of 3D shapes during optimization. Furthermore, GAP incorporates a diffuse-based inpainting strategy that specifically targets at completing hard-to-observe regions. We evaluate GAP on the Point-to-Gaussian generation task across varying complexity levels, from synthetic point clouds to challenging real-world scans, and even large-scale scenes. Project Page: https://weiqi-zhang.github.io/GAP.
Learning Bijective Surface Parameterization for Inferring Signed Distance Functions from Sparse Point Clouds with Grid Deformation
Mar 31, 2025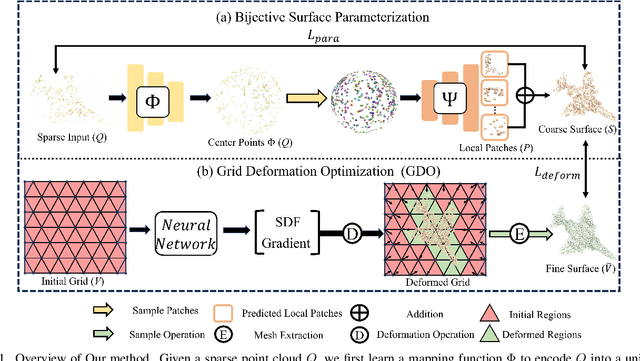
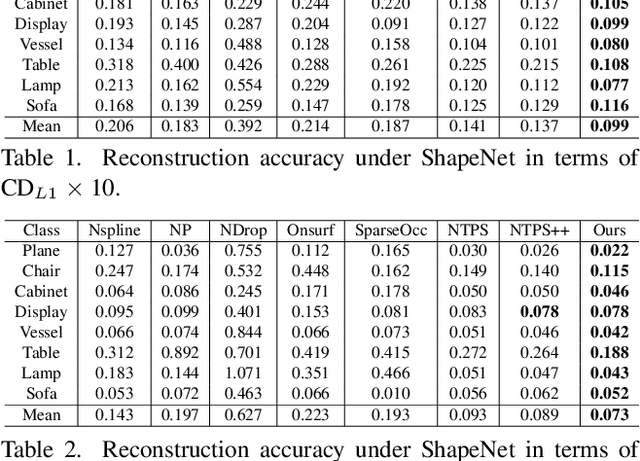
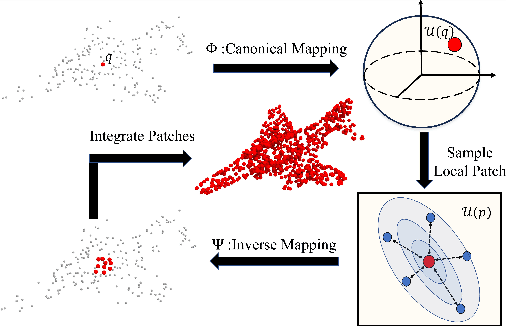
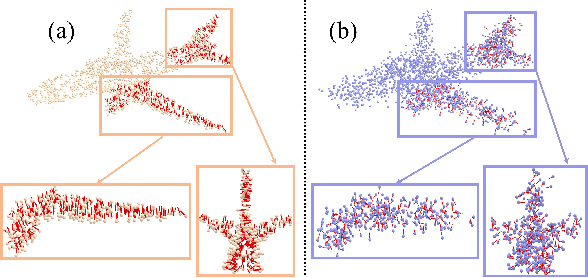
Inferring signed distance functions (SDFs) from sparse point clouds remains a challenge in surface reconstruction. The key lies in the lack of detailed geometric information in sparse point clouds, which is essential for learning a continuous field. To resolve this issue, we present a novel approach that learns a dynamic deformation network to predict SDFs in an end-to-end manner. To parameterize a continuous surface from sparse points, we propose a bijective surface parameterization (BSP) that learns the global shape from local patches. Specifically, we construct a bijective mapping for sparse points from the parametric domain to 3D local patches, integrating patches into the global surface. Meanwhile, we introduce grid deformation optimization (GDO) into the surface approximation to optimize the deformation of grid points and further refine the parametric surfaces. Experimental results on synthetic and real scanned datasets demonstrate that our method significantly outperforms the current state-of-the-art methods. Project page: https://takeshie.github.io/Bijective-SDF
Sparseformer: a Transferable Transformer with Multi-granularity Token Sparsification for Medical Time Series Classification
Mar 19, 2025



Medical time series (MedTS) classification is crucial for improved diagnosis in healthcare, and yet it is challenging due to the varying granularity of patterns, intricate inter-channel correlation, information redundancy, and label scarcity. While existing transformer-based models have shown promise in time series analysis, they mainly focus on forecasting and fail to fully exploit the distinctive characteristics of MedTS data. In this paper, we introduce Sparseformer, a transformer specifically designed for MedTS classification. We propose a sparse token-based dual-attention mechanism that enables global modeling and token compression, allowing dynamic focus on the most informative tokens while distilling redundant features. This mechanism is then applied to the multi-granularity, cross-channel encoding of medical signals, capturing intra- and inter-granularity correlations and inter-channel connections. The sparsification design allows our model to handle heterogeneous inputs of varying lengths and channels directly. Further, we introduce an adaptive label encoder to address label space misalignment across datasets, equipping our model with cross-dataset transferability to alleviate the medical label scarcity issue. Our model outperforms 12 baselines across seven medical datasets under supervised learning. In the few-shot learning experiments, our model also achieves superior average results. In addition, the in-domain and cross-domain experiments among three diagnostic scenarios demonstrate our model's zero-shot learning capability. Collectively, these findings underscore the robustness and transferability of our model in various medical applications.
MultiPull: Detailing Signed Distance Functions by Pulling Multi-Level Queries at Multi-Step
Nov 02, 2024



Reconstructing a continuous surface from a raw 3D point cloud is a challenging task. Recent methods usually train neural networks to overfit on single point clouds to infer signed distance functions (SDFs). However, neural networks tend to smooth local details due to the lack of ground truth signed distances or normals, which limits the performance of overfitting-based methods in reconstruction tasks. To resolve this issue, we propose a novel method, named MultiPull, to learn multi-scale implicit fields from raw point clouds by optimizing accurate SDFs from coarse to fine. We achieve this by mapping 3D query points into a set of frequency features, which makes it possible to leverage multi-level features during optimization. Meanwhile, we introduce optimization constraints from the perspective of spatial distance and normal consistency, which play a key role in point cloud reconstruction based on multi-scale optimization strategies. Our experiments on widely used object and scene benchmarks demonstrate that our method outperforms the state-of-the-art methods in surface reconstruction.
DiffGS: Functional Gaussian Splatting Diffusion
Oct 25, 2024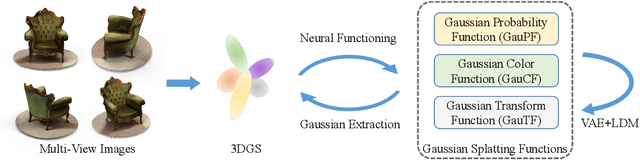
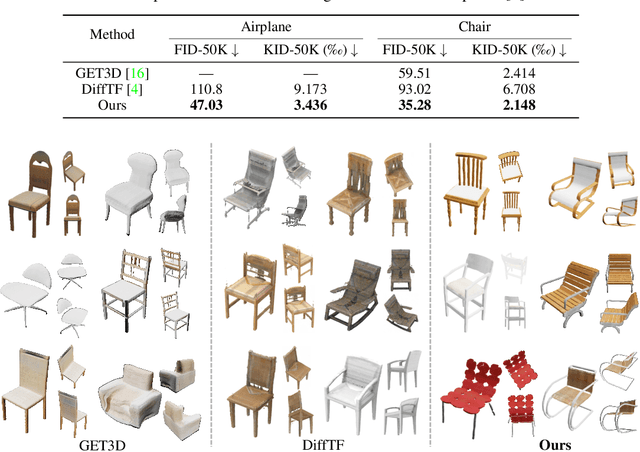
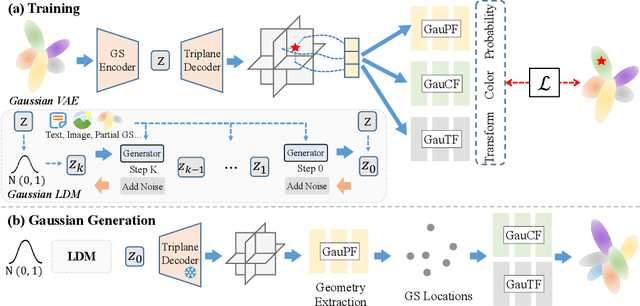
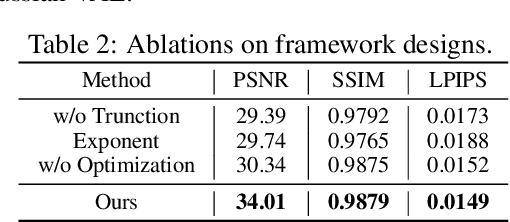
3D Gaussian Splatting (3DGS) has shown convincing performance in rendering speed and fidelity, yet the generation of Gaussian Splatting remains a challenge due to its discreteness and unstructured nature. In this work, we propose DiffGS, a general Gaussian generator based on latent diffusion models. DiffGS is a powerful and efficient 3D generative model which is capable of generating Gaussian primitives at arbitrary numbers for high-fidelity rendering with rasterization. The key insight is to represent Gaussian Splatting in a disentangled manner via three novel functions to model Gaussian probabilities, colors and transforms. Through the novel disentanglement of 3DGS, we represent the discrete and unstructured 3DGS with continuous Gaussian Splatting functions, where we then train a latent diffusion model with the target of generating these Gaussian Splatting functions both unconditionally and conditionally. Meanwhile, we introduce a discretization algorithm to extract Gaussians at arbitrary numbers from the generated functions via octree-guided sampling and optimization. We explore DiffGS for various tasks, including unconditional generation, conditional generation from text, image, and partial 3DGS, as well as Point-to-Gaussian generation. We believe that DiffGS provides a new direction for flexibly modeling and generating Gaussian Splatting.
DualTime: A Dual-Adapter Multimodal Language Model for Time Series Representation
Jun 07, 2024



The recent rapid development of language models (LMs) has attracted attention in the field of time series, including multimodal time series modeling. However, we note that current time series multimodal methods are biased, often assigning a primary role to one modality while the other assumes a secondary role. They overlook the mutual benefits and complementary of different modalities. For example, in seizure diagnosis, relying solely on textual clinical reports makes it difficult to pinpoint the area and type of the disease, while electroencephalograms (EEGs) alone cannot provide an accurate diagnosis without considering the symptoms. In this study, based on the complementary information mining of time series multimodal data, we propose DualTime, a Dual-adapter multimodal language model for Time series representation implementing temporal-primary and textual-primary modeling simultaneously. By injecting lightweight adaption tokens, the LM pipeline shared by dual adapters encourages embedding alignment and achieves efficient fine-tuning. Empirically, our method outperforms state-of-the-art models in both supervised and unsupervised settings, highlighting the complementary benefits of different modalities. In addition, we conduct few-shot label transfer experiments, which further verifies the transferability and expressiveness of our proposed DualTime.
A Survey of Time Series Foundation Models: Generalizing Time Series Representation with Large Language Model
May 07, 2024
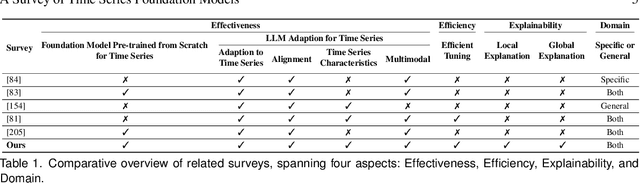
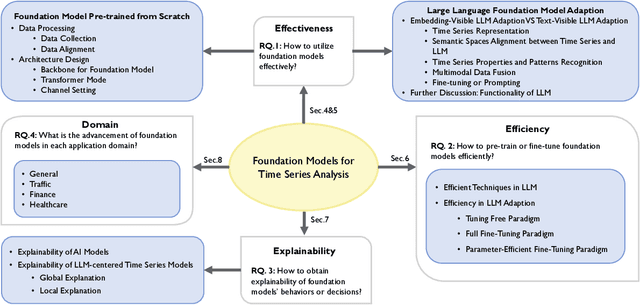
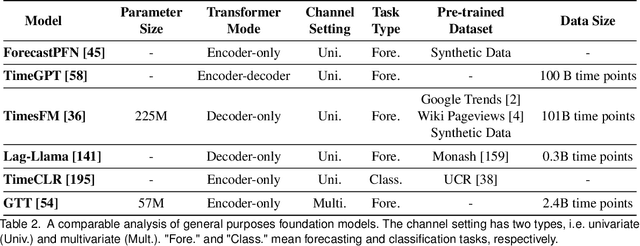
Time series data are ubiquitous across various domains, making time series analysis critically important. Traditional time series models are task-specific, featuring singular functionality and limited generalization capacity. Recently, large language foundation models have unveiled their remarkable capabilities for cross-task transferability, zero-shot/few-shot learning, and decision-making explainability. This success has sparked interest in the exploration of foundation models to solve multiple time series challenges simultaneously. There are two main research lines, namely pre-training foundation models from scratch for time series and adapting large language foundation models for time series. They both contribute to the development of a unified model that is highly generalizable, versatile, and comprehensible for time series analysis. This survey offers a 3E analytical framework for comprehensive examination of related research. Specifically, we examine existing works from three dimensions, namely Effectiveness, Efficiency and Explainability. In each dimension, we focus on discussing how related works devise tailored solution by considering unique challenges in the realm of time series. Furthermore, we provide a domain taxonomy to help followers keep up with the domain-specific advancements. In addition, we introduce extensive resources to facilitate the field's development, including datasets, open-source, time series libraries. A GitHub repository is also maintained for resource updates (https://github.com/start2020/Awesome-TimeSeries-LLM-FM).