 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoL3D: Collaborative Learning of Single-view Depth and Camera Intrinsics for Metric 3D Shape Recovery
Paper and Code
Feb 13, 2025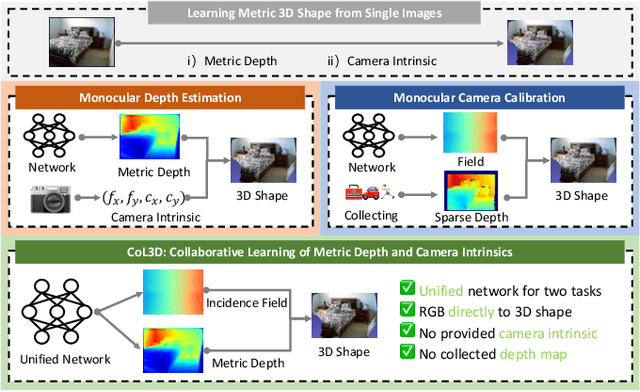
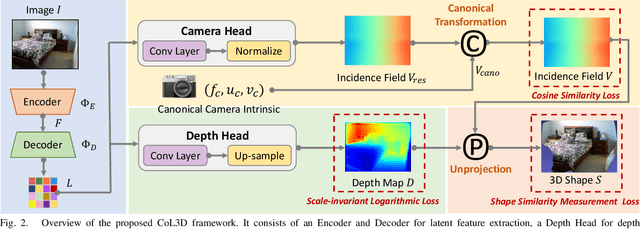


Recovering the metric 3D shape from a single image is particularly relevant for robotics and embodied intelligence applications, where accurate spatial understanding is crucial for navigation and interaction with environments. Usually, the mainstream approaches achieve it through monocular depth estimation. However, without camera intrinsics, the 3D metric shape can not be recovered from depth alone. In this study, we theoretically demonstrate that depth serves as a 3D prior constraint for estimating camera intrinsics and uncover the reciprocal relations between these two elements. Motivated by this, we propose a collaborative learning framework for jointly estimating depth and camera intrinsics, named CoL3D, to learn metric 3D shapes from single images. Specifically, CoL3D adopts a unified network and performs collaborative optimization at three levels: depth, camera intrinsics, and 3D point clouds. For camera intrinsics, we design a canonical incidence field mechanism as a prior that enables the model to learn the residual incident field for enhanced calibration. Additionally, we incorporate a shape similarity measurement loss in the point cloud space, which improves the quality of 3D shapes essential for robotic applications. As a result, when training and testing on a single dataset with in-domain settings, CoL3D delivers outstanding performance in both depth estimation and camera calibration across several indoor and outdoor benchmark datasets, which leads to remarkable 3D shape quality for the perception capabilities of robots.