 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: Spectral Concentration by Distributionally Robust Joint Covariance-Precision Estimation
Nov 18, 2025We propose a distributionally robust formulation for simultaneously estimating the covariance matrix and the precision matrix of a random vector.The proposed model minimizes the worst-case weighted sum of the Frobenius loss of the covariance estimator and Stein's loss of the precision matrix estimator against all distributions from an ambiguity set centered at the nominal distribution. The radius of the ambiguity set is measured via convex spectral divergence. We demonstrate that the proposed distributionally robust estimation model can be reduced to a convex optimization problem, thereby yielding quasi-analytical estimators. The joint estimators are shown to be nonlinear shrinkage estimators. The eigenvalues of the estimators are shrunk nonlinearly towards a positive scalar, where the scalar is determined by the weight coefficient of the loss terms. By tuning the coefficient carefully, the shrinkage corrects the spectral bias of the empirical covariance/precision matrix estimator. By this property, we call the proposed joint estimator the Spectral concentrated COvariance and Precision matrix Estimator (SCOPE). We demonstrate that the shrinkage effect improves the condition number of the estimator. We provide a parameter-tuning scheme that adjusts the shrinkage target and intensity that is asymptotically optimal. Numerical experiments on synthetic and real data show that our shrinkage estimators perform competitively against state-of-the-art estimators in practical applications.
ContentV: Efficient Training of Video Generation Models with Limited Compute
Jun 05, 2025Recent advances in video generation demand increasingly efficient training recipes to mitigate escalating computational costs. In this report, we present ContentV, an 8B-parameter text-to-video model that achieves state-of-the-art performance (85.14 on VBench) after training on 256 x 64GB Neural Processing Units (NPUs) for merely four weeks. ContentV generates diverse, high-quality videos across multiple resolutions and durations from text prompts, enabled by three key innovations: (1) A minimalist architecture that maximizes reuse of pre-trained image generation models for video generation; (2) A systematic multi-stage training strategy leveraging flow matching for enhanced efficiency; and (3) A cost-effective reinforcement learning with human feedback framework that improves generation quality without requiring additional human annotations. All the code and models are available at: https://contentv.github.io.
Towards Self-Improvement of Diffusion Models via Group Preference Optimization
May 16, 2025Aligning text-to-image (T2I) diffusion models with Direct Preference Optimization (DPO) has shown notable improvements in generation quality. However, applying DPO to T2I faces two challenges: the sensitivity of DPO to preference pairs and the labor-intensive process of collecting and annotating high-quality data. In this work, we demonstrate that preference pairs with marginal differences can degrade DPO performance. Since DPO relies exclusively on relative ranking while disregarding the absolute difference of pairs, it may misclassify losing samples as wins, or vice versa. We empirically show that extending the DPO from pairwise to groupwise and incorporating reward standardization for reweighting leads to performance gains without explicit data selection. Furthermore, we propose Group Preference Optimization (GPO), an effective self-improvement method that enhances performance by leveraging the model's own capabilities without requiring external data. Extensive experiments demonstrate that GPO is effective across various diffusion models and tasks. Specifically, combining with widely used computer vision models, such as YOLO and OCR, the GPO improves the accurate counting and text rendering capabilities of the Stable Diffusion 3.5 Medium by 20 percentage points. Notably, as a plug-and-play method, no extra overhead is introduced during inference.
No Parameters, No Problem: 3D Gaussian Splatting without Camera Intrinsics and Extrinsics
Feb 27, 2025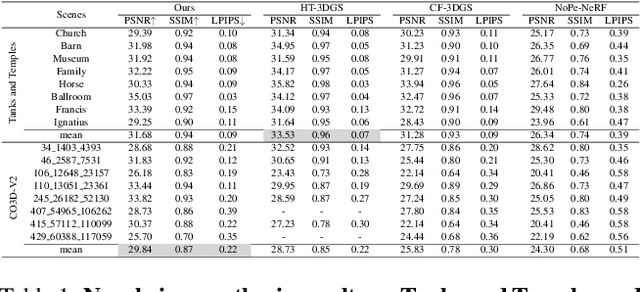
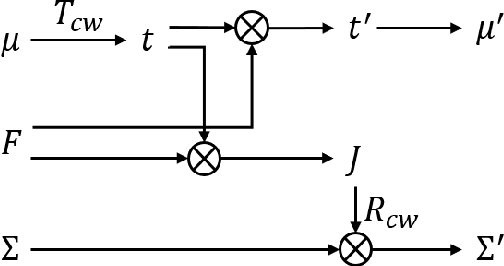
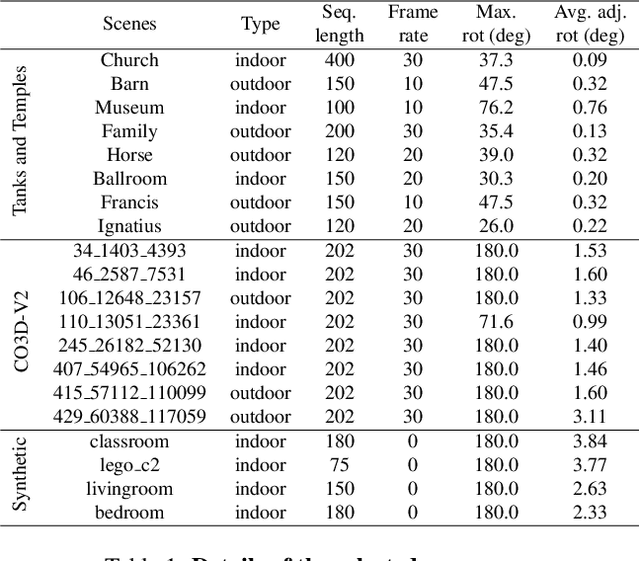
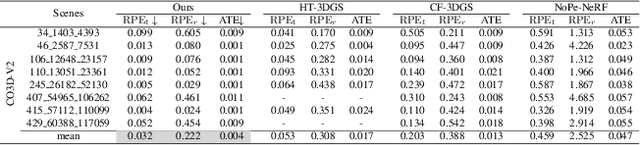
While 3D Gaussian Splatting (3DGS) has made significant progress in scene reconstruction and novel view synthesis, it still heavily relies on accurately pre-computed camera intrinsics and extrinsics, such as focal length and camera poses. In order to mitigate this dependency, the previous efforts have focused on optimizing 3DGS without the need for camera poses, yet camera intrinsics remain necessary. To further loose the requirement, we propose a joint optimization method to train 3DGS from an image collection without requiring either camera intrinsics or extrinsics. To achieve this goal, we introduce several key improvements during the joint training of 3DGS. We theoretically derive the gradient of the camera intrinsics, allowing the camera intrinsics to be optimized simultaneously during training. Moreover, we integrate global track information and select the Gaussian kernels associated with each track, which will be trained and automatically rescaled to an infinitesimally small size, closely approximating surface points, and focusing on enforcing multi-view consistency and minimizing reprojection errors, while the remaining kernels continue to serve their original roles. This hybrid training strategy nicely unifies the camera parameters estimation and 3DGS training. Extensive evaluations demonstrate that the proposed method achieves state-of-the-art (SOTA) performance on both public and synthetic datasets.
HybridGS: Decoupling Transients and Statics with 2D and 3D Gaussian Splatting
Dec 05, 2024



Generating high-quality novel view renderings of 3D Gaussian Splatting (3DGS) in scenes featuring transient objects is challenging. We propose a novel hybrid representation, termed as HybridGS, using 2D Gaussians for transient objects per image and maintaining traditional 3D Gaussians for the whole static scenes. Note that, the 3DGS itself is better suited for modeling static scenes that assume multi-view consistency, but the transient objects appear occasionally and do not adhere to the assumption, thus we model them as planar objects from a single view, represented with 2D Gaussians. Our novel representation decomposes the scene from the perspective of fundamental viewpoint consistency, making it more reasonable. Additionally, we present a novel multi-view regulated supervision method for 3DGS that leverages information from co-visible regions, further enhancing the distinctions between the transients and statics. Then, we propose a straightforward yet effective multi-stage training strategy to ensure robust training and high-quality view synthesis across various settings. Experiments on benchmark datasets show our state-of-the-art performance of novel view synthesis in both indoor and outdoor scenes, even in the presence of distracting elements.
Learning Neural Volumetric Pose Features for Camera Localization
Mar 19, 2024



We introduce a novel neural volumetric pose feature, termed PoseMap, designed to enhance camera localization by encapsulating the information between images and the associated camera poses. Our framework leverages an Absolute Pose Regression (APR) architecture, together with an augmented NeRF module. This integration not only facilitates the generation of novel views to enrich the training dataset but also enables the learning of effective pose features. Additionally, we extend our architecture for self-supervised online alignment, allowing our method to be used and fine-tuned for unlabelled images within a unified framework. Experiments demonstrate that our method achieves 14.28% and 20.51% performance gain on average in indoor and outdoor benchmark scenes, outperforming existing APR methods with state-of-the-art accuracy.
PCDNF: Revisiting Learning-based Point Cloud Denoising via Joint Normal Filtering
Sep 02, 2022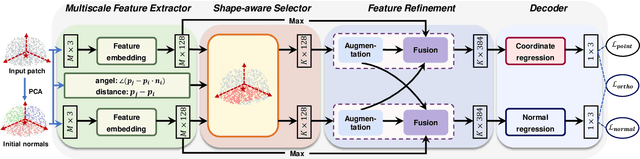
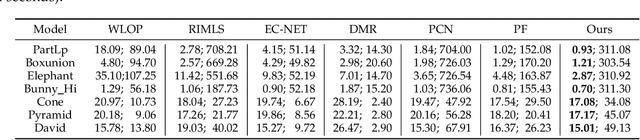
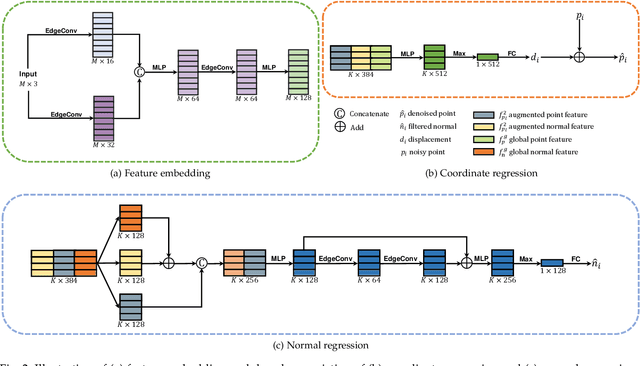
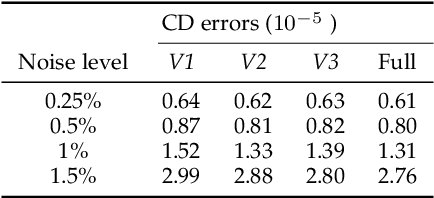
Recovering high quality surfaces from noisy point clouds, known as point cloud denoising, is a fundamental yet challenging problem in geometry processing. Most of the existing methods either directly denoise the noisy input or filter raw normals followed by updating point positions. Motivated by the essential interplay between point cloud denoising and normal filtering, we revisit point cloud denoising from a multitask perspective, and propose an end-to-end network, named PCDNF, to denoise point clouds via joint normal filtering. In particular, we introduce an auxiliary normal filtering task to help the overall network remove noise more effectively while preserving geometric features more accurately. In addition to the overall architecture, our network has two novel modules. On one hand, to improve noise removal performance, we design a shape-aware selector to construct the latent tangent space representation of the specific point by comprehensively considering the learned point and normal features and geometry priors. On the other hand, point features are more suitable for describing geometric details, and normal features are more conducive for representing geometric structures (e.g., sharp edges and corners). Combining point and normal features allows us to overcome their weaknesses. Thus, we design a feature refinement module to fuse point and normal features for better recovering geometric information. Extensive evaluations, comparisons, and ablation studies demonstrate that the proposed method outperforms state-of-the-arts for both point cloud denoising and normal filtering.
Clustering Activity-Travel Behavior Time Series using Topological Data Analysis
Jul 17, 2019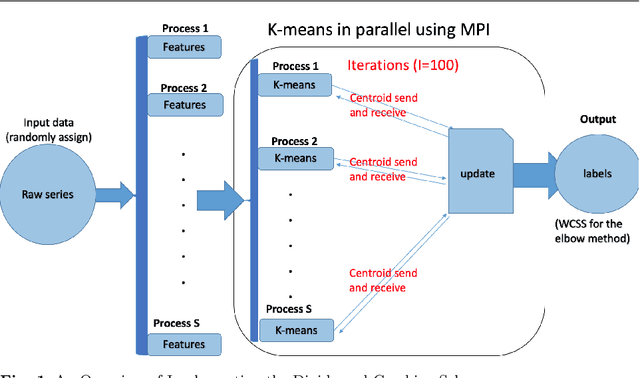
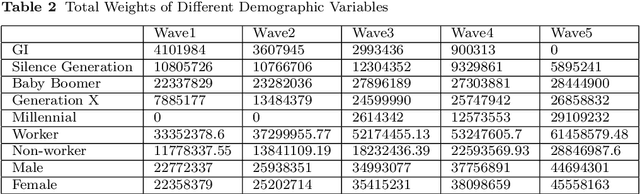
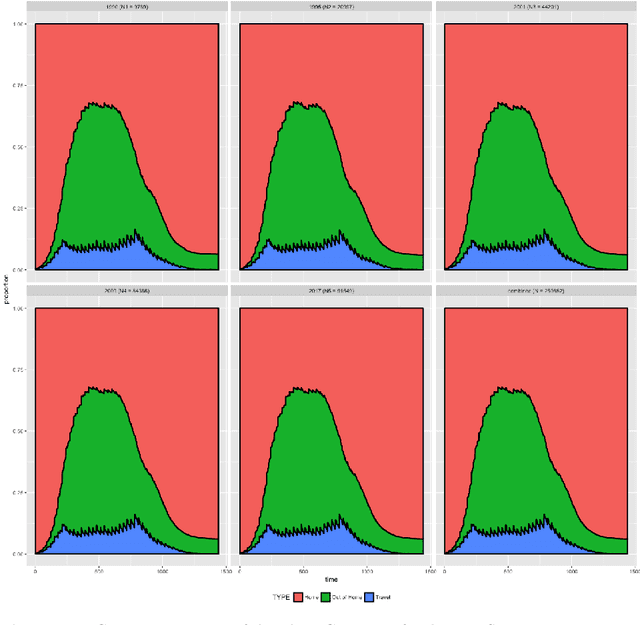
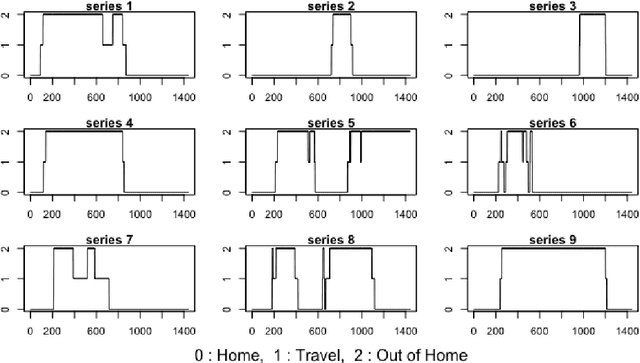
Over the last few years, traffic data has been exploding and the transportation discipline has entered the era of big data. It brings out new opportunities for doing data-driven analysis, but it also challenges traditional analytic methods. This paper proposes a new Divide and Combine based approach to do K means clustering on activity-travel behavior time series using features that are derived using tools in Time Series Analysis and Topological Data Analysis. Clustering data from five waves of the National Household Travel Survey ranging from 1990 to 2017 suggests that activity-travel patterns of individuals over the last three decades can be grouped into three clusters. Results also provide evidence in support of recent claims about differences in activity-travel patterns of different survey cohorts. The proposed method is generally applicable and is not limited only to activity-travel behavior analysis in transportation studies. Driving behavior, travel mode choice, household vehicle ownership, when being characterized as categorical time series, can all be analyzed using the proposed method.
A Scalable Heuristic for Fastest-Path Computation on Very Large Road Maps
Dec 18, 2018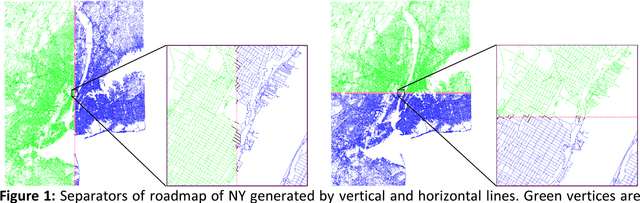
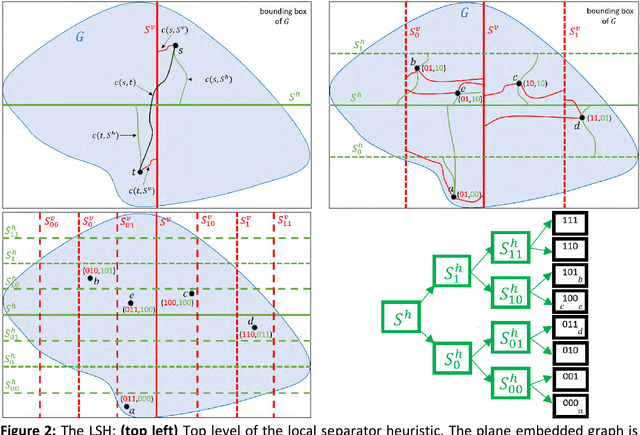
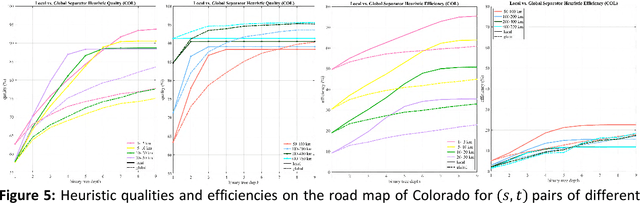
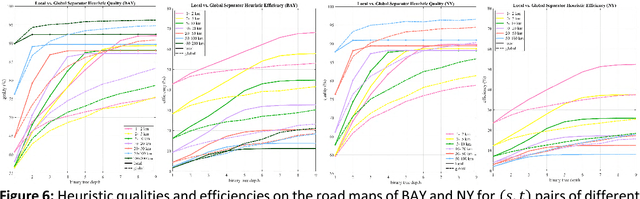
Fastest-path queries between two points in a very large road map is an increasingly important primitive in modern transportation and navigation systems, thus very efficient computation of these paths is critical for system performance and throughput. We present a method to compute an effective heuristic for the fastest path travel time between two points on a road map, which can be used to significantly accelerate the classical A* algorithm when computing fastest paths. Our method is based on two hierarchical sets of separators of the map represented by two binary trees. A preprocessing step computes a short vector of values per road junction based on the separator trees, which is then stored with the map and used to efficiently compute the heuristic at the online query stage. We demonstrate experimentally that this method scales well to any map size, providing a better quality heuristic, thus more efficient A* search, for fastest path queries between points at all distances - especially small and medium range - relative to other known heuristics.
Efficient Fastest-Path Computations in Road Maps
Oct 02, 2018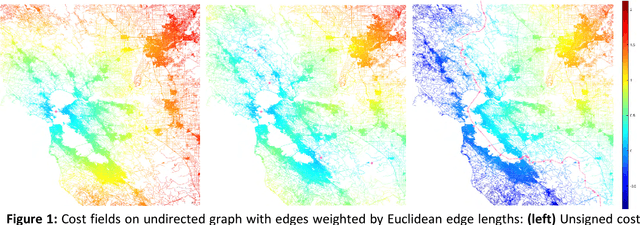

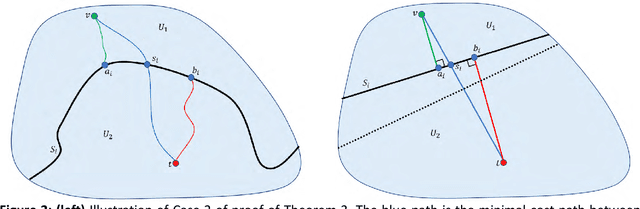

In the age of real-time online traffic information and GPS-enabled devices, fastest-path computations between two points in a road network modeled as a directed graph, where each directed edge is weighted by a "travel time" value, are becoming a standard feature of many navigation-related applications. To support this, very efficient computation of these paths in very large road networks is critical. Fastest paths may be computed as minimal-cost paths in a weighted directed graph, but traditional minimal-cost path algorithms based on variants of the classic Dijkstra algorithm do not scale well, as in the worst case they may traverse the entire graph. A common improvement, which can dramatically reduce the number of traversed graph vertices, is the A* algorithm, which requires a good heuristic lower bound on the minimal cost. We introduce a simple, but very effective, heuristic function based on a small number of values assigned to each graph vertex. The values are based on graph separators and computed efficiently in a preprocessing stage. We present experimental results demonstrating that our heuristic provides estimates of the minimal cost which are superior to those of other heuristics. Our experiments show that when used in the A* algorithm, this heuristic can reduce the number of vertices traversed by an order of magnitude compared to other heuristics.