 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSVideo: Fast Speed Video Diffusion Model in a Highly-Compressed Latent Space
Feb 02, 2026We introduce FSVideo, a fast speed transformer-based image-to-video (I2V) diffusion framework. We build our framework on the following key components: 1.) a new video autoencoder with highly-compressed latent space ($64\times64\times4$ spatial-temporal downsampling ratio), achieving competitive reconstruction quality; 2.) a diffusion transformer (DIT) architecture with a new layer memory design to enhance inter-layer information flow and context reuse within DIT, and 3.) a multi-resolution generation strategy via a few-step DIT upsampler to increase video fidelity. Our final model, which contains a 14B DIT base model and a 14B DIT upsampler, achieves competitive performance against other popular open-source models, while being an order of magnitude faster. We discuss our model design as well as training strategies in this report.
DiffLM: Controllable Synthetic Data Generation via Diffusion Language Models
Nov 05, 2024



Recent advancements in large language models (LLMs) have significantly enhanced their knowledge and generative capabilities, leading to a surge of interest in leveraging LLMs for high-quality data synthesis. However, synthetic data generation via prompting LLMs remains challenging due to LLMs' limited understanding of target data distributions and the complexity of prompt engineering, especially for structured formatted data. To address these issues, we introduce DiffLM, a controllable data synthesis framework based on variational autoencoder (VAE), which further (1) leverages diffusion models to reserve more information of original distribution and format structure in the learned latent distribution and (2) decouples the learning of target distribution knowledge from the LLM's generative objectives via a plug-and-play latent feature injection module. As we observed significant discrepancies between the VAE's latent representations and the real data distribution, the latent diffusion module is introduced into our framework to learn a fully expressive latent distribution. Evaluations on seven real-world datasets with structured formatted data (i.e., Tabular, Code and Tool data) demonstrate that DiffLM generates high-quality data, with performance on downstream tasks surpassing that of real data by 2-7 percent in certain cases. The data and code will be publicly available upon completion of internal review.
AIPO: Improving Training Objective for Iterative Preference Optimization
Sep 13, 2024



Preference Optimization (PO), is gaining popularity as an alternative choice of Proximal Policy Optimization (PPO) for aligning Large Language Models (LLMs). Recent research on aligning LLMs iteratively with synthetic or partially synthetic data shows promising results in scaling up PO training for both academic settings and proprietary trained models such as Llama3. Despite its success, our study shows that the length exploitation issue present in PO is even more severe in Iterative Preference Optimization (IPO) due to the iterative nature of the process. In this work, we study iterative preference optimization with synthetic data. We share the findings and analysis along the way of building the iterative preference optimization pipeline. More specifically, we discuss the length exploitation issue during iterative preference optimization and propose our training objective for iterative preference optimization, namely Agreement-aware Iterative Preference Optimization (AIPO). To demonstrate the effectiveness of our method, we conduct comprehensive experiments and achieve state-of-the-art performance on MT-Bench, AlpacaEval 2.0, and Arena-Hard. Our implementation and model checkpoints will be made available at https://github.com/bytedance/AIPO.
Accurate and Fast Compressed Video Captioning
Sep 22, 2023Existing video captioning approaches typically require to first sample video frames from a decoded video and then conduct a subsequent process (e.g., feature extraction and/or captioning model learning). In this pipeline, manual frame sampling may ignore key information in videos and thus degrade performance. Additionally, redundant information in the sampled frames may result in low efficiency in the inference of video captioning. Addressing this, we study video captioning from a different perspective in compressed domain, which brings multi-fold advantages over the existing pipeline: 1) Compared to raw images from the decoded video, the compressed video, consisting of I-frames, motion vectors and residuals, is highly distinguishable, which allows us to leverage the entire video for learning without manual sampling through a specialized model design; 2) The captioning model is more efficient in inference as smaller and less redundant information is processed. We propose a simple yet effective end-to-end transformer in the compressed domain for video captioning that enables learning from the compressed video for captioning. We show that even with a simple design, our method can achieve state-of-the-art performance on different benchmarks while running almost 2x faster than existing approaches. Code is available at https://github.com/acherstyx/CoCap.
AutoTransition: Learning to Recommend Video Transition Effects
Jul 27, 2022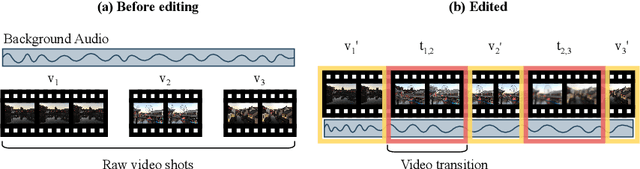


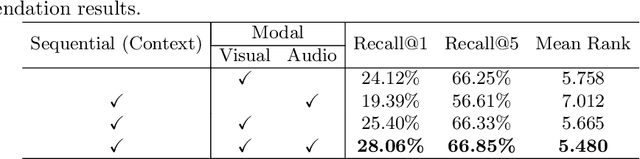
Video transition effects are widely used in video editing to connect shots for creating cohesive and visually appealing videos. However, it is challenging for non-professionals to choose best transitions due to the lack of cinematographic knowledge and design skills. In this paper, we present the premier work on performing automatic video transitions recommendation (VTR): given a sequence of raw video shots and companion audio, recommend video transitions for each pair of neighboring shots. To solve this task, we collect a large-scale video transition dataset using publicly available video templates on editing softwares. Then we formulate VTR as a multi-modal retrieval problem from vision/audio to video transitions and propose a novel multi-modal matching framework which consists of two parts. First we learn the embedding of video transitions through a video transition classification task. Then we propose a model to learn the matching correspondence from vision/audio inputs to video transitions. Specifically, the proposed model employs a multi-modal transformer to fuse vision and audio information, as well as capture the context cues in sequential transition outputs. Through both quantitative and qualitative experiments, we clearly demonstrate the effectiveness of our method. Notably, in the comprehensive user study, our method receives comparable scores compared with professional editors while improving the video editing efficiency by \textbf{300\scalebox{1.25}{$\times$}}. We hope our work serves to inspire other researchers to work on this new task. The dataset and codes are public at \url{https://github.com/acherstyx/AutoTransition}.