 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLower Layer Matters: Alleviating Hallucination via Multi-Layer Fusion Contrastive Decoding with Truthfulness Refocused
Paper and Code
Aug 16, 2024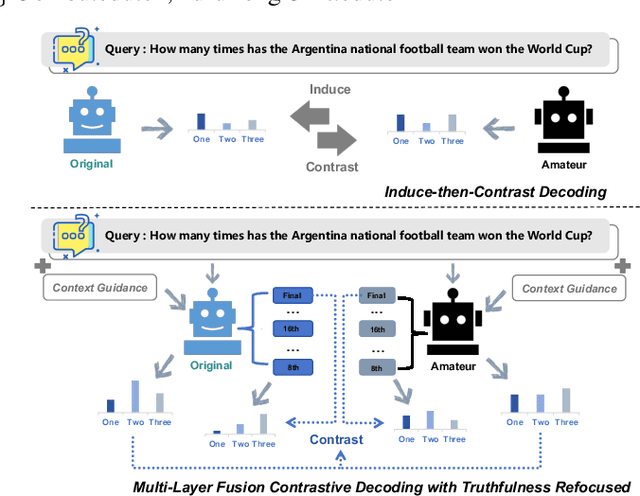

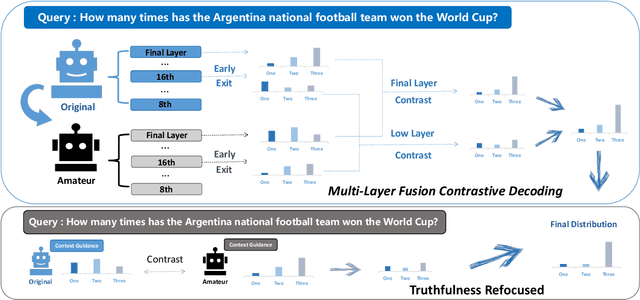
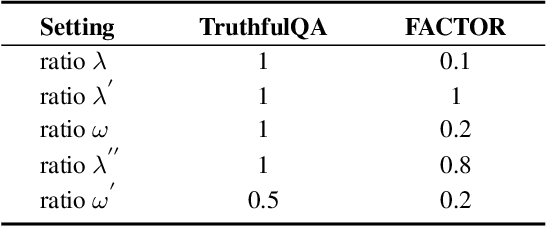
Large Language Models (LLMs) have demonstrated exceptional performance across various natural language processing tasks, yet they occasionally tend to yield content that factually inaccurate or discordant with the expected output, a phenomenon empirically referred to as "hallucination". To tackle this issue, recent works have investigated contrastive decoding between the original model and an amateur model with induced hallucination, which has shown promising results. Nonetheless, this method may undermine the output distribution of the original LLM caused by its coarse contrast and simplistic subtraction operation, potentially leading to errors in certain cases. In this paper, we introduce a novel contrastive decoding framework termed LOL (LOwer Layer Matters). Our approach involves concatenating the contrastive decoding of both the final and lower layers between the original model and the amateur model, thereby achieving multi-layer fusion to aid in the mitigation of hallucination. Additionally, we incorporate a truthfulness refocused module that leverages contextual guidance to enhance factual encoding, further capturing truthfulness during contrastive decoding. Extensive experiments conducted on two publicly available datasets illustrate that our proposed LOL framework can substantially alleviate hallucination while surpassing existing baselines in most cases. Compared with the best baseline, we improve by average 4.5 points on all metrics of TruthfulQA. The source code is coming soon.