 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASER: Activation Smoothing and Error Reconstruction for Large Language Model Quantization
Nov 12, 2024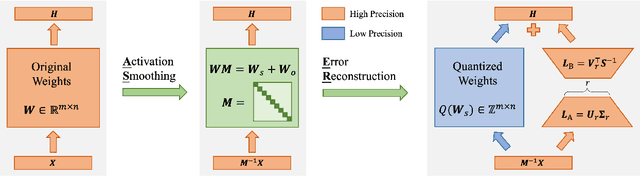


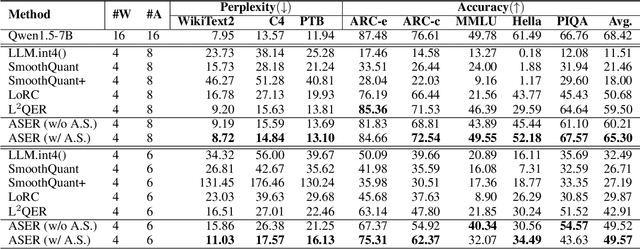
Quantization stands as a pivotal technique for large language model (LLM) serving, yet it poses significant challenges particularly in achieving effective low-bit quantization. The limited numerical mapping makes the quantized model produce a non-trivial error, bringing out intolerable performance degration. This paper is anchored in the basic idea of model compression objectives, and delves into the layer-wise error distribution of LLMs during post-training quantization. Subsequently, we introduce ASER, an algorithm consisting of (1) Error Reconstruction: low-rank compensation for quantization error with LoRA-style matrices constructed by whitening SVD; (2) Activation Smoothing: outlier extraction to gain smooth activation and better error compensation. ASER is capable of quantizing typical LLMs to low-bit ones, particularly preserving accuracy even in W4A8 per-channel setup. Experimental results show that ASER is competitive among the state-of-the-art quantization algorithms, showing potential to activation quantization, with minor overhead.
A Novel Integrated Framework for Learning both Text Detection and Recognition
Nov 21, 2018



In this paper, we propose a novel integrated framework for learning both text detection and recognition. For most of the existing methods, detection and recognition are treated as two isolated tasks and trained separately, since parameters of detection and recognition models are different and two models target to optimize their own loss functions during individual training processes. In contrast to those methods, by sharing model parameters, we merge the detection model and recognition model into a single end-to-end trainable model and train the joint model for two tasks simultaneously. The shared parameters not only help effectively reduce the computational load in inference process, but also improve the end-to-end text detection-recognition accuracy. In addition, we design a simpler and faster sequence learning method for the recognition network based on a succession of stacked convolutional layers without any recurrent structure, this is proved feasible and dramatically improves inference speed. Extensive experiments on different datasets demonstrate that the proposed method achieves very promising results.