 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Task-Driven, Planner-in-the-Loop Computational Design Framework for Modular Manipulators
Dec 18, 2025Modular manipulators composed of pre-manufactured and interchangeable modules offer high adaptability across diverse tasks. However, their deployment requires generating feasible motions while jointly optimizing morphology and mounted pose under kinematic, dynamic, and physical constraints. Moreover, traditional single-branch designs often extend reach by increasing link length, which can easily violate torque limits at the base joint. To address these challenges, we propose a unified task-driven computational framework that integrates trajectory planning across varying morphologies with the co-optimization of morphology and mounted pose. Within this framework, a hierarchical model predictive control (HMPC) strategy is developed to enable motion planning for both redundant and non-redundant manipulators. For design optimization, the CMA-ES is employed to efficiently explore a hybrid search space consisting of discrete morphology configurations and continuous mounted poses. Meanwhile, a virtual module abstraction is introduced to enable bi-branch morphologies, allowing an auxiliary branch to offload torque from the primary branch and extend the achievable workspace without increasing the capacity of individual joint modules. Extensive simulations and hardware experiments on polishing, drilling, and pick-and-place tasks demonstrate the effectiveness of the proposed framework. The results show that: 1) the framework can generate multiple feasible designs that satisfy kinematic and dynamic constraints while avoiding environmental collisions for given tasks; 2) flexible design objectives, such as maximizing manipulability, minimizing joint effort, or reducing the number of modules, can be achieved by customizing the cost functions; and 3) a bi-branch morphology capable of operating in a large workspace can be realized without requiring more powerful basic modules.
Versatile, Robust, and Explosive Locomotion with Rigid and Articulated Compliant Quadrupeds
Apr 17, 2025Achieving versatile and explosive motion with robustness against dynamic uncertainties is a challenging task. Introducing parallel compliance in quadrupedal design is deemed to enhance locomotion performance, which, however, makes the control task even harder. This work aims to address this challenge by proposing a general template model and establishing an efficient motion planning and control pipeline. To start, we propose a reduced-order template model-the dual-legged actuated spring-loaded inverted pendulum with trunk rotation-which explicitly models parallel compliance by decoupling spring effects from active motor actuation. With this template model, versatile acrobatic motions, such as pronking, froggy jumping, and hop-turn, are generated by a dual-layer trajectory optimization, where the singularity-free body rotation representation is taken into consideration. Integrated with a linear singularity-free tracking controller, enhanced quadrupedal locomotion is achieved. Comparisons with the existing template model reveal the improved accuracy and generalization of our model. Hardware experiments with a rigid quadruped and a newly designed compliant quadruped demonstrate that i) the template model enables generating versatile dynamic motion; ii) parallel elasticity enhances explosive motion. For example, the maximal pronking distance, hop-turn yaw angle, and froggy jumping distance increase at least by 25%, 15% and 25%, respectively; iii) parallel elasticity improves the robustness against dynamic uncertainties, including modelling errors and external disturbances. For example, the allowable support surface height variation increases by 100% for robust froggy jumping.
Explosive Jumping with Rigid and Articulated Soft Quadrupeds via Example Guided Reinforcement Learning
Mar 20, 2025Achieving controlled jumping behaviour for a quadruped robot is a challenging task, especially when introducing passive compliance in mechanical design. This study addresses this challenge via imitation-based deep reinforcement learning with a progressive training process. To start, we learn the jumping skill by mimicking a coarse jumping example generated by model-based trajectory optimization. Subsequently, we generalize the learned policy to broader situations, including various distances in both forward and lateral directions, and then pursue robust jumping in unknown ground unevenness. In addition, without tuning the reward much, we learn the jumping policy for a quadruped with parallel elasticity. Results show that using the proposed method, i) the robot learns versatile jumps by learning only from a single demonstration, ii) the robot with parallel compliance reduces the landing error by 11.1%, saves energy cost by 15.2% and reduces the peak torque by 15.8%, compared to the rigid robot without parallel elasticity, iii) the robot can perform jumps of variable distances with robustness against ground unevenness (maximal 4cm height perturbations) using only proprioceptive perception.
Curriculum-Based Reinforcement Learning for Quadrupedal Jumping: A Reference-free Design
Jan 29, 2024



Deep reinforcement learning (DRL) has emerged as a promising solution to mastering explosive and versatile quadrupedal jumping skills. However, current DRL-based frameworks usually rely on well-defined reference trajectories, which are obtained by capturing animal motions or transferring experience from existing controllers. This work explores the possibility of learning dynamic jumping without imitating a reference trajectory. To this end, we incorporate a curriculum design into DRL so as to accomplish challenging tasks progressively. Starting from a vertical in-place jump, we then generalize the learned policy to forward and diagonal jumps and, finally, learn to jump across obstacles. Conditioned on the desired landing location, orientation, and obstacle dimensions, the proposed approach contributes to a wide range of jumping motions, including omnidirectional jumping and robust jumping, alleviating the effort to extract references in advance. Particularly, without constraints from the reference motion, a 90cm forward jump is achieved, exceeding previous records for similar robots reported in the existing literature. Additionally, continuous jumping on the soft grassy floor is accomplished, even when it is not encountered in the training stage. A supplementary video showing our results can be found at https://youtu.be/nRaMCrwU5X8 .
Two-Stage Learning of Highly Dynamic Motions with Rigid and Articulated Soft Quadrupeds
Sep 18, 2023Controlled execution of dynamic motions in quadrupedal robots, especially those with articulated soft bodies, presents a unique set of challenges that traditional methods struggle to address efficiently. In this study, we tackle these issues by relying on a simple yet effective two-stage learning framework to generate dynamic motions for quadrupedal robots. First, a gradient-free evolution strategy is employed to discover simply represented control policies, eliminating the need for a predefined reference motion. Then, we refine these policies using deep reinforcement learning. Our approach enables the acquisition of complex motions like pronking and back-flipping, effectively from scratch. Additionally, our method simplifies the traditionally labour-intensive task of reward shaping, boosting the efficiency of the learning process. Importantly, our framework proves particularly effective for articulated soft quadrupeds, whose inherent compliance and adaptability make them ideal for dynamic tasks but also introduce unique control challenges.
Nonlinear Model Predictive Control for Robust Bipedal Locomotion Exploring CoM Height and Angular Momentum Changes
Feb 18, 2019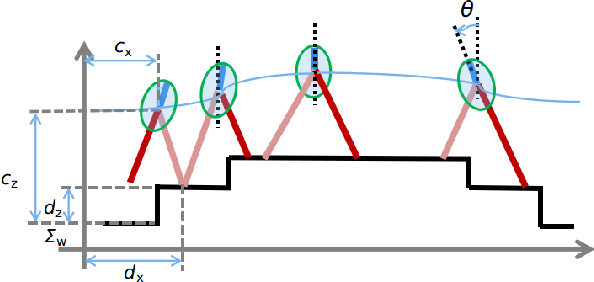
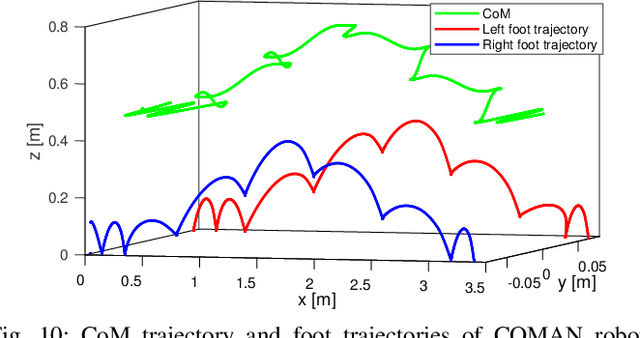
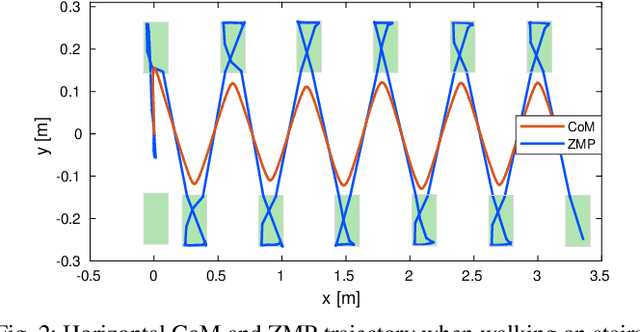
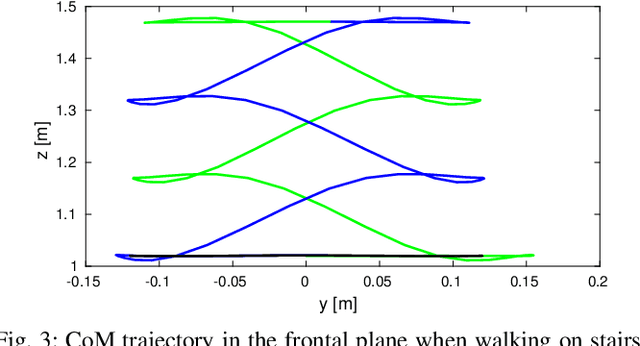
Human beings can make use of various reactive strategies, e.g. foot location adjustment and upper-body inclination, to keep balance while walking under dynamic disturbances. In this work, we propose a novel Nonlinear Model Predictive Control (NMPC) framework for versatile bipedal gait pattern generation, with the capabilities of footstep adjustment, Center of Mass (CoM) height variation and angular momentum adaptation. These features are realized by constraining the Zero Moment Point motion with considering the variable CoM height and angular momentum change of the Inverted Pendulum plus Flywheel Model. In addition, the NMPC framework also takes into account the constraints of footstep location, CoM vertical motion, upper-body inclination and joint torques, and is finally formulated as a quadratically constrained quadratic program. Therefore, it can be solved efficiently by Sequential Quadratic Programming. Using this unified framework, versatile walking pattern with exploiting time-varying CoM height trajectory and angular momentum changes can be generated based only on the terrain information input. Furthermore, the improved capability for balance recovery under external pushes has been demonstrated through simulation studies.