 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovery of skill switching criteria for learning agile quadruped locomotion
Feb 10, 2025This paper develops a hierarchical learning and optimization framework that can learn and achieve well-coordinated multi-skill locomotion. The learned multi-skill policy can switch between skills automatically and naturally in tracking arbitrarily positioned goals and recover from failures promptly. The proposed framework is composed of a deep reinforcement learning process and an optimization process. First, the contact pattern is incorporated into the reward terms for learning different types of gaits as separate policies without the need for any other references. Then, a higher level policy is learned to generate weights for individual policies to compose multi-skill locomotion in a goal-tracking task setting. Skills are automatically and naturally switched according to the distance to the goal. The proper distances for skill switching are incorporated in reward calculation for learning the high level policy and updated by an outer optimization loop as learning progresses. We first demonstrated successful multi-skill locomotion in comprehensive tasks on a simulated Unitree A1 quadruped robot. We also deployed the learned policy in the real world showcasing trotting, bounding, galloping, and their natural transitions as the goal position changes. Moreover, the learned policy can react to unexpected failures at any time, perform prompt recovery, and resume locomotion successfully. Compared to discrete switch between single skills which failed to transition to galloping in the real world, our proposed approach achieves all the learned agile skills, with smoother and more continuous skill transitions.
Constrained Skill Discovery: Quadruped Locomotion with Unsupervised Reinforcement Learning
Oct 10, 2024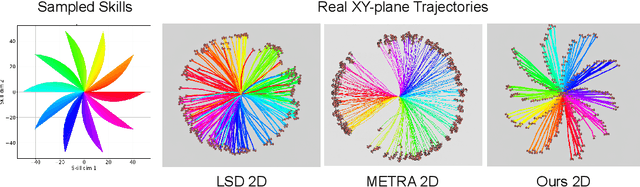
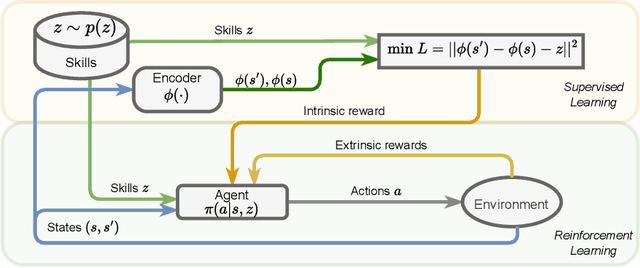
Representation learning and unsupervised skill discovery can allow robots to acquire diverse and reusable behaviors without the need for task-specific rewards. In this work, we use unsupervised reinforcement learning to learn a latent representation by maximizing the mutual information between skills and states subject to a distance constraint. Our method improves upon prior constrained skill discovery methods by replacing the latent transition maximization with a norm-matching objective. This not only results in a much a richer state space coverage compared to baseline methods, but allows the robot to learn more stable and easily controllable locomotive behaviors. We successfully deploy the learned policy on a real ANYmal quadruped robot and demonstrate that the robot can accurately reach arbitrary points of the Cartesian state space in a zero-shot manner, using only an intrinsic skill discovery and standard regularization rewards.
Curriculum-Based Reinforcement Learning for Quadrupedal Jumping: A Reference-free Design
Jan 29, 2024



Deep reinforcement learning (DRL) has emerged as a promising solution to mastering explosive and versatile quadrupedal jumping skills. However, current DRL-based frameworks usually rely on well-defined reference trajectories, which are obtained by capturing animal motions or transferring experience from existing controllers. This work explores the possibility of learning dynamic jumping without imitating a reference trajectory. To this end, we incorporate a curriculum design into DRL so as to accomplish challenging tasks progressively. Starting from a vertical in-place jump, we then generalize the learned policy to forward and diagonal jumps and, finally, learn to jump across obstacles. Conditioned on the desired landing location, orientation, and obstacle dimensions, the proposed approach contributes to a wide range of jumping motions, including omnidirectional jumping and robust jumping, alleviating the effort to extract references in advance. Particularly, without constraints from the reference motion, a 90cm forward jump is achieved, exceeding previous records for similar robots reported in the existing literature. Additionally, continuous jumping on the soft grassy floor is accomplished, even when it is not encountered in the training stage. A supplementary video showing our results can be found at https://youtu.be/nRaMCrwU5X8 .
Safe Model Predictive Control Approach for Non-holonomic Mobile Robots
Jul 26, 2022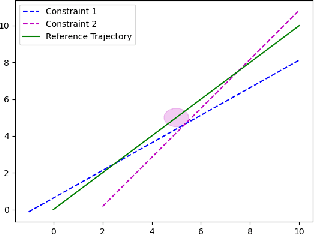
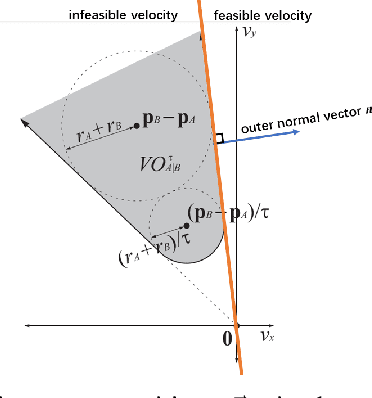

We design an MPC approach for non-holonomic mobile robots and analytically show that the time-varying, linearized system can yield asymptotic stability around the origin in the tracking task. For obstacle avoidance, we propose a constraint in velocity-space which explicitly couples the two control inputs based on the current state.