 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamStyle: A Unified Framework for Video Stylization
Jan 06, 2026Video stylization, an important downstream task of video generation models, has not yet been thoroughly explored. Its input style conditions typically include text, style image, and stylized first frame. Each condition has a characteristic advantage: text is more flexible, style image provides a more accurate visual anchor, and stylized first frame makes long-video stylization feasible. However, existing methods are largely confined to a single type of style condition, which limits their scope of application. Additionally, their lack of high-quality datasets leads to style inconsistency and temporal flicker. To address these limitations, we introduce DreamStyle, a unified framework for video stylization, supporting (1) text-guided, (2) style-image-guided, and (3) first-frame-guided video stylization, accompanied by a well-designed data curation pipeline to acquire high-quality paired video data. DreamStyle is built on a vanilla Image-to-Video (I2V) model and trained using a Low-Rank Adaptation (LoRA) with token-specific up matrices that reduces the confusion among different condition tokens. Both qualitative and quantitative evaluations demonstrate that DreamStyle is competent in all three video stylization tasks, and outperforms the competitors in style consistency and video quality.
DreamID-V:Bridging the Image-to-Video Gap for High-Fidelity Face Swapping via Diffusion Transformer
Jan 04, 2026Video Face Swapping (VFS) requires seamlessly injecting a source identity into a target video while meticulously preserving the original pose, expression, lighting, background, and dynamic information. Existing methods struggle to maintain identity similarity and attribute preservation while preserving temporal consistency. To address the challenge, we propose a comprehensive framework to seamlessly transfer the superiority of Image Face Swapping (IFS) to the video domain. We first introduce a novel data pipeline SyncID-Pipe that pre-trains an Identity-Anchored Video Synthesizer and combines it with IFS models to construct bidirectional ID quadruplets for explicit supervision. Building upon paired data, we propose the first Diffusion Transformer-based framework DreamID-V, employing a core Modality-Aware Conditioning module to discriminatively inject multi-model conditions. Meanwhile, we propose a Synthetic-to-Real Curriculum mechanism and an Identity-Coherence Reinforcement Learning strategy to enhance visual realism and identity consistency under challenging scenarios. To address the issue of limited benchmarks, we introduce IDBench-V, a comprehensive benchmark encompassing diverse scenes. Extensive experiments demonstrate DreamID-V outperforms state-of-the-art methods and further exhibits exceptional versatility, which can be seamlessly adapted to various swap-related tasks.
I2VControl-Camera: Precise Video Camera Control with Adjustable Motion Strength
Nov 26, 2024

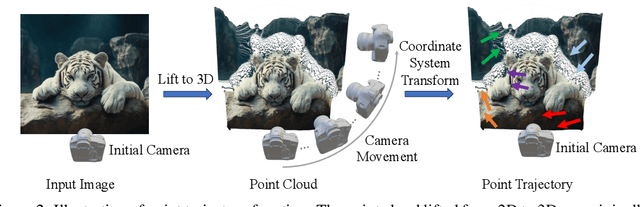
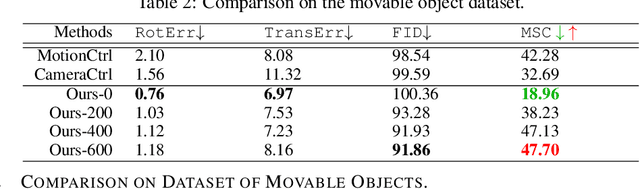
Video generation technologies are developing rapidly and have broad potential applications. Among these technologies, camera control is crucial for generating professional-quality videos that accurately meet user expectations. However, existing camera control methods still suffer from several limitations, including control precision and the neglect of the control for subject motion dynamics. In this work, we propose I2VControl-Camera, a novel camera control method that significantly enhances controllability while providing adjustability over the strength of subject motion. To improve control precision, we employ point trajectory in the camera coordinate system instead of only extrinsic matrix information as our control signal. To accurately control and adjust the strength of subject motion, we explicitly model the higher-order components of the video trajectory expansion, not merely the linear terms, and design an operator that effectively represents the motion strength. We use an adapter architecture that is independent of the base model structure. Experiments on static and dynamic scenes show that our framework outperformances previous methods both quantitatively and qualitatively. The project page is: https://wanquanf.github.io/I2VControlCamera .
I2VControl: Disentangled and Unified Video Motion Synthesis Control
Nov 26, 2024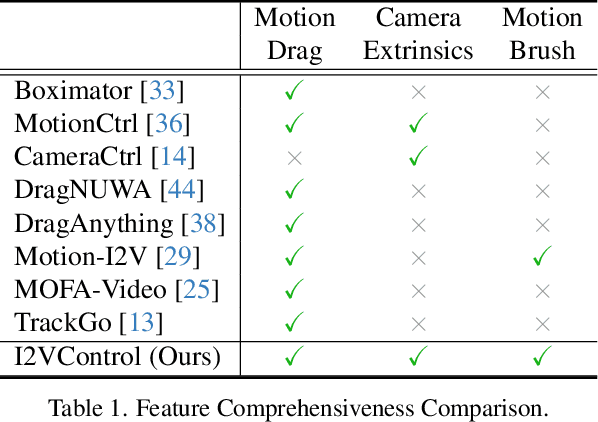
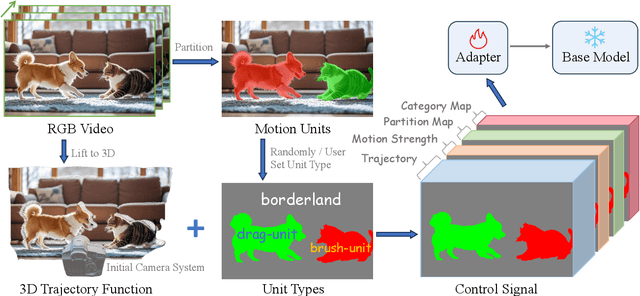
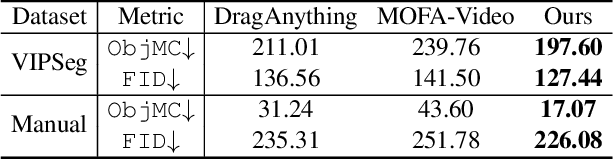

Video synthesis techniques are undergoing rapid progress, with controllability being a significant aspect of practical usability for end-users. Although text condition is an effective way to guide video synthesis, capturing the correct joint distribution between text descriptions and video motion remains a substantial challenge. In this paper, we present a disentangled and unified framework, namely I2VControl, that unifies multiple motion control tasks in image-to-video synthesis. Our approach partitions the video into individual motion units and represents each unit with disentangled control signals, which allows for various control types to be flexibly combined within our single system. Furthermore, our methodology seamlessly integrates as a plug-in for pre-trained models and remains agnostic to specific model architectures. We conduct extensive experiments, achieving excellent performance on various control tasks, and our method further facilitates user-driven creative combinations, enhancing innovation and creativity. The project page is: https://wanquanf.github.io/I2VControl .