 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrbanNav: Learning Language-Guided Urban Navigation from Web-Scale Human Trajectories
Dec 10, 2025
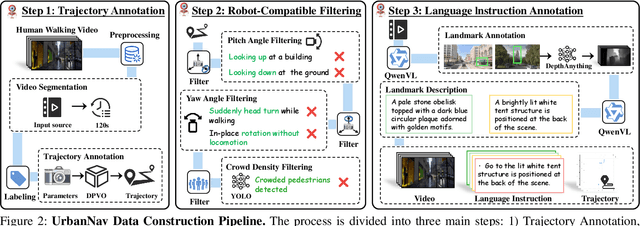
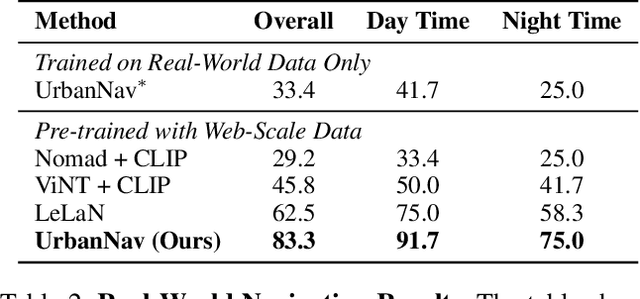
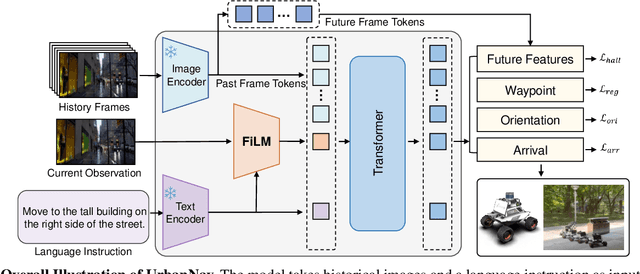
Navigating complex urban environments using natural language instructions poses significant challenges for embodied agents, including noisy language instructions, ambiguous spatial references, diverse landmarks, and dynamic street scenes. Current visual navigation methods are typically limited to simulated or off-street environments, and often rely on precise goal formats, such as specific coordinates or images. This limits their effectiveness for autonomous agents like last-mile delivery robots navigating unfamiliar cities. To address these limitations, we introduce UrbanNav, a scalable framework that trains embodied agents to follow free-form language instructions in diverse urban settings. Leveraging web-scale city walking videos, we develop an scalable annotation pipeline that aligns human navigation trajectories with language instructions grounded in real-world landmarks. UrbanNav encompasses over 1,500 hours of navigation data and 3 million instruction-trajectory-landmark triplets, capturing a wide range of urban scenarios. Our model learns robust navigation policies to tackle complex urban scenarios, demonstrating superior spatial reasoning, robustness to noisy instructions, and generalization to unseen urban settings. Experimental results show that UrbanNav significantly outperforms existing methods, highlighting the potential of large-scale web video data to enable language-guided, real-world urban navigation for embodied agents.
Reflecting with Two Voices: A Co-Adaptive Dual-Strategy Framework for LLM-Based Agent Decision Making
Dec 09, 2025Large language model (LLM) agents often rely on external demonstrations or retrieval-augmented planning, leading to brittleness, poor generalization, and high computational overhead. Inspired by human problem-solving, we propose DuSAR (Dual-Strategy Agent with Reflecting) - a demonstration-free framework that enables a single frozen LLM to perform co-adaptive reasoning via two complementary strategies: a high-level holistic plan and a context-grounded local policy. These strategies interact through a lightweight reflection mechanism, where the agent continuously assesses progress via a Strategy Fitness Score and dynamically revises its global plan when stuck or refines it upon meaningful advancement, mimicking human metacognitive behavior. On ALFWorld and Mind2Web, DuSAR achieves state-of-the-art performance with open-source LLMs (7B-70B), reaching 37.1% success on ALFWorld (Llama3.1-70B) - more than doubling the best prior result (13.0%) - and 4.02% on Mind2Web, also more than doubling the strongest baseline. Remarkably, it reduces per-step token consumption by 3-9X while maintaining strong performance. Ablation studies confirm the necessity of dual-strategy coordination. Moreover, optional integration of expert demonstrations further boosts results, highlighting DuSAR's flexibility and compatibility with external knowledge.
C-NAV: Towards Self-Evolving Continual Object Navigation in Open World
Oct 23, 2025Embodied agents are expected to perform object navigation in dynamic, open-world environments. However, existing approaches typically rely on static trajectories and a fixed set of object categories during training, overlooking the real-world requirement for continual adaptation to evolving scenarios. To facilitate related studies, we introduce the continual object navigation benchmark, which requires agents to acquire navigation skills for new object categories while avoiding catastrophic forgetting of previously learned knowledge. To tackle this challenge, we propose C-Nav, a continual visual navigation framework that integrates two key innovations: (1) A dual-path anti-forgetting mechanism, which comprises feature distillation that aligns multi-modal inputs into a consistent representation space to ensure representation consistency, and feature replay that retains temporal features within the action decoder to ensure policy consistency. (2) An adaptive sampling strategy that selects diverse and informative experiences, thereby reducing redundancy and minimizing memory overhead. Extensive experiments across multiple model architectures demonstrate that C-Nav consistently outperforms existing approaches, achieving superior performance even compared to baselines with full trajectory retention, while significantly lowering memory requirements. The code will be publicly available at https://bigtree765.github.io/C-Nav-project.
COSMO: Combination of Selective Memorization for Low-cost Vision-and-Language Navigation
Mar 31, 2025Vision-and-Language Navigation (VLN) tasks have gained prominence within artificial intelligence research due to their potential application in fields like home assistants. Many contemporary VLN approaches, while based on transformer architectures, have increasingly incorporated additional components such as external knowledge bases or map information to enhance performance. These additions, while boosting performance, also lead to larger models and increased computational costs. In this paper, to achieve both high performance and low computational costs, we propose a novel architecture with the COmbination of Selective MemOrization (COSMO). Specifically, COSMO integrates state-space modules and transformer modules, and incorporates two VLN-customized selective state space modules: the Round Selective Scan (RSS) and the Cross-modal Selective State Space Module (CS3). RSS facilitates comprehensive inter-modal interactions within a single scan, while the CS3 module adapts the selective state space module into a dual-stream architecture, thereby enhancing the acquisition of cross-modal interactions. Experimental validations on three mainstream VLN benchmarks, REVERIE, R2R, and R2R-CE, not only demonstrate competitive navigation performance of our model but also show a significant reduction in computational costs.
FlexVLN: Flexible Adaptation for Diverse Vision-and-Language Navigation Tasks
Mar 18, 2025



The aspiration of the Vision-and-Language Navigation (VLN) task has long been to develop an embodied agent with robust adaptability, capable of seamlessly transferring its navigation capabilities across various tasks. Despite remarkable advancements in recent years, most methods necessitate dataset-specific training, thereby lacking the capability to generalize across diverse datasets encompassing distinct types of instructions. Large language models (LLMs) have demonstrated exceptional reasoning and generalization abilities, exhibiting immense potential in robot action planning. In this paper, we propose FlexVLN, an innovative hierarchical approach to VLN that integrates the fundamental navigation ability of a supervised-learning-based Instruction Follower with the robust generalization ability of the LLM Planner, enabling effective generalization across diverse VLN datasets. Moreover, a verification mechanism and a multi-model integration mechanism are proposed to mitigate potential hallucinations by the LLM Planner and enhance execution accuracy of the Instruction Follower. We take REVERIE, SOON, and CVDN-target as out-of-domain datasets for assessing generalization ability. The generalization performance of FlexVLN surpasses that of all the previous methods to a large extent.
Boter: Bootstrapping Knowledge Selection and Question Answering for Knowledge-based VQA
Apr 22, 2024
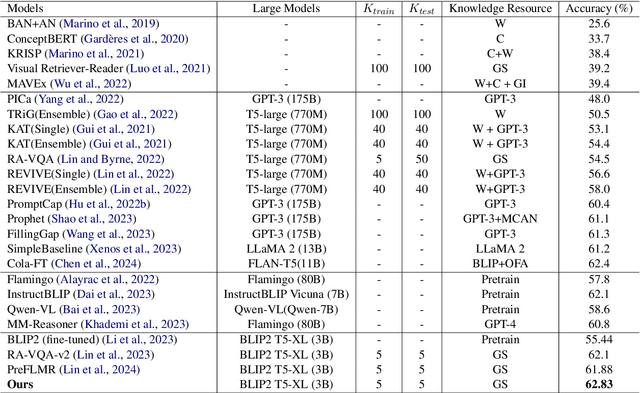


Knowledge-based Visual Question Answering (VQA) requires models to incorporate external knowledge to respond to questions about visual content. Previous methods mostly follow the "retrieve and generate" paradigm. Initially, they utilize a pre-trained retriever to fetch relevant knowledge documents, subsequently employing them to generate answers. While these methods have demonstrated commendable performance in the task, they possess limitations: (1) they employ an independent retriever to acquire knowledge solely based on the similarity between the query and knowledge embeddings, without assessing whether the knowledge document is truly conducive to helping answer the question; (2) they convert the image into text and then conduct retrieval and answering in natural language space, which may not ensure comprehensive acquisition of all image information. To address these limitations, we propose Boter, a novel framework designed to bootstrap knowledge selection and question answering by leveraging the robust multimodal perception capabilities of the Multimodal Large Language Model (MLLM). The framework consists of two modules: Selector and Answerer, where both are initialized by the MLLM and parameter-efficiently finetuned in a simple cycle: find key knowledge in the retrieved knowledge documents using the Selector, and then use them to finetune the Answerer to predict answers; obtain the pseudo-labels of key knowledge documents based on the predictions of the Answerer and weak supervision labels, and then finetune the Selector to select key knowledge; repeat. Our framework significantly enhances the performance of the baseline on the challenging open-domain Knowledge-based VQA benchmark, OK-VQA, achieving a state-of-the-art accuracy of 62.83%.
Knowledge Condensation and Reasoning for Knowledge-based VQA
Mar 15, 2024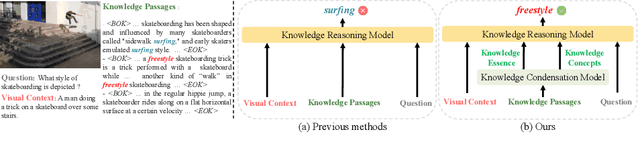
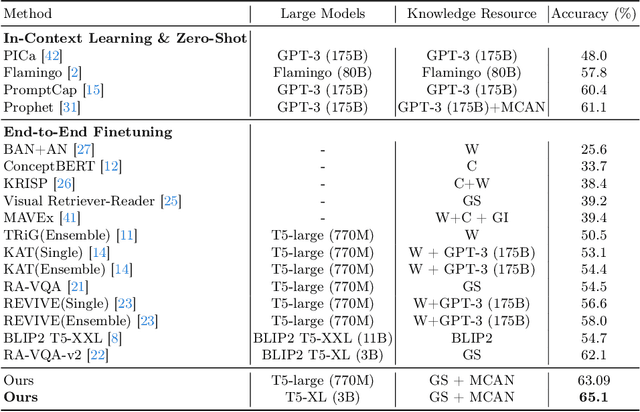
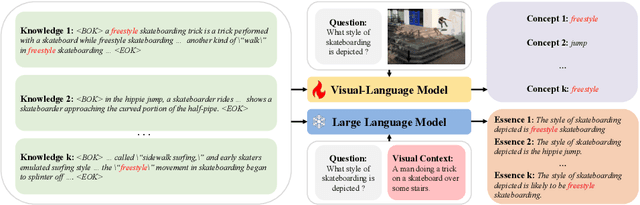
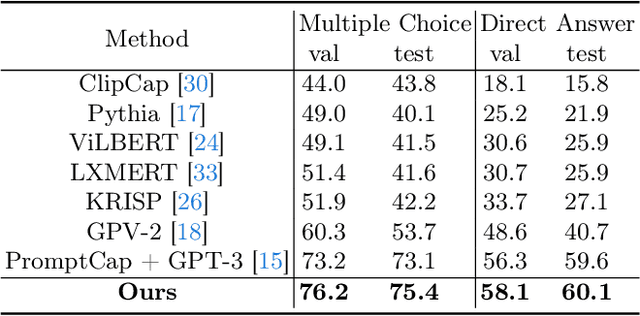
Knowledge-based visual question answering (KB-VQA) is a challenging task, which requires the model to leverage external knowledge for comprehending and answering questions grounded in visual content. Recent studies retrieve the knowledge passages from external knowledge bases and then use them to answer questions. However, these retrieved knowledge passages often contain irrelevant or noisy information, which limits the performance of the model. To address the challenge, we propose two synergistic models: Knowledge Condensation model and Knowledge Reasoning model. We condense the retrieved knowledge passages from two perspectives. First, we leverage the multimodal perception and reasoning ability of the visual-language models to distill concise knowledge concepts from retrieved lengthy passages, ensuring relevance to both the visual content and the question. Second, we leverage the text comprehension ability of the large language models to summarize and condense the passages into the knowledge essence which helps answer the question. These two types of condensed knowledge are then seamlessly integrated into our Knowledge Reasoning model, which judiciously navigates through the amalgamated information to arrive at the conclusive answer. Extensive experiments validate the superiority of the proposed method. Compared to previous methods, our method achieves state-of-the-art performance on knowledge-based VQA datasets (65.1% on OK-VQA and 60.1% on A-OKVQA) without resorting to the knowledge produced by GPT-3 (175B).
VAST: A Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset
May 29, 2023



Vision and text have been fully explored in contemporary video-text foundational models, while other modalities such as audio and subtitles in videos have not received sufficient attention. In this paper, we resort to establish connections between multi-modality video tracks, including Vision, Audio, and Subtitle, and Text by exploring an automatically generated large-scale omni-modality video caption dataset called VAST-27M. Specifically, we first collect 27 million open-domain video clips and separately train a vision and an audio captioner to generate vision and audio captions. Then, we employ an off-the-shelf Large Language Model (LLM) to integrate the generated captions, together with subtitles and instructional prompts into omni-modality captions. Based on the proposed VAST-27M dataset, we train an omni-modality video-text foundational model named VAST, which can perceive and process vision, audio, and subtitle modalities from video, and better support various tasks including vision-text, audio-text, and multi-modal video-text tasks (retrieval, captioning and QA). Extensive experiments have been conducted to demonstrate the effectiveness of our proposed VAST-27M corpus and VAST foundation model. VAST achieves 22 new state-of-the-art results on various cross-modality benchmarks. Code, model and dataset will be released at https://github.com/TXH-mercury/VAST.