 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Ring to Rule Them All: Unifying Group-Based RL via Dynamic Power-Mean Geometry
Jan 30, 2026Group-based reinforcement learning has evolved from the arithmetic mean of GRPO to the geometric mean of GMPO. While GMPO improves stability by constraining a conservative objective, it shares a fundamental limitation with GRPO: reliance on a fixed aggregation geometry that ignores the evolving and heterogeneous nature of each trajectory. In this work, we unify these approaches under Power-Mean Policy Optimization (PMPO), a generalized framework that parameterizes the aggregation geometry via the power-mean geometry exponent p. Within this framework, GRPO and GMPO are recovered as special cases. Theoretically, we demonstrate that adjusting p modulates the concentration of gradient updates, effectively reweighting tokens based on their advantage contribution. To determine p adaptively, we introduce a Clip-aware Effective Sample Size (ESS) mechanism. Specifically, we propose a deterministic rule that maps a trajectory clipping fraction to a target ESS. Then, we solve for the specific p to align the trajectory induced ESS with this target one. This allows PMPO to dynamically transition between the aggressive arithmetic mean for reliable trajectories and the conservative geometric mean for unstable ones. Experiments on multiple mathematical reasoning benchmarks demonstrate that PMPO outperforms strong baselines.
Enhancing Instruction-Following Capability of Visual-Language Models by Reducing Image Redundancy
Nov 23, 2024


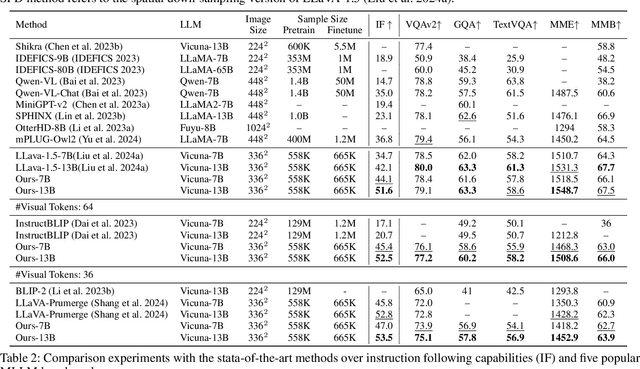
Large Language Models (LLMs) have strong instruction-following capability to interpret and execute tasks as directed by human commands. Multimodal Large Language Models (MLLMs) have inferior instruction-following ability compared to LLMs. However, there is a significant gap in the instruction-following capabilities between the MLLMs and LLMs. In this study, we conduct a pilot experiment, which demonstrates that spatially down-sampling visual tokens significantly enhances the instruction-following capability of MLLMs. This is attributed to the substantial redundancy in visual modality. However, this intuitive method severely impairs the MLLM's multimodal understanding capability. In this paper, we propose Visual-Modality Token Compression (VMTC) and Cross-Modality Attention Inhibition (CMAI) strategies to alleviate this gap between MLLMs and LLMs by inhibiting the influence of irrelevant visual tokens during content generation, increasing the instruction-following ability of the MLLMs while retaining their multimodal understanding capacity. In VMTC module, the primary tokens are retained and the redundant tokens are condensed by token clustering and merging. In CMAI process, we aggregate text-to-image attentions by text-to-text attentions to obtain a text-to-image focus score. Attention inhibition is performed on the text-image token pairs with low scores. Our comprehensive experiments over instruction-following capabilities and VQA-V2, GQA, TextVQA, MME and MMBench five benchmarks, demonstrate that proposed strategy significantly enhances the instruction following capability of MLLMs while preserving the ability to understand and process multimodal inputs.
Training-free Subject-Enhanced Attention Guidance for Compositional Text-to-image Generation
May 11, 2024Existing subject-driven text-to-image generation models suffer from tedious fine-tuning steps and struggle to maintain both text-image alignment and subject fidelity. For generating compositional subjects, it often encounters problems such as object missing and attribute mixing, where some subjects in the input prompt are not generated or their attributes are incorrectly combined. To address these limitations, we propose a subject-driven generation framework and introduce training-free guidance to intervene in the generative process during inference time. This approach strengthens the attention map, allowing for precise attribute binding and feature injection for each subject. Notably, our method exhibits exceptional zero-shot generation ability, especially in the challenging task of compositional generation. Furthermore, we propose a novel metric GroundingScore to evaluate subject alignment thoroughly. The obtained quantitative results serve as compelling evidence showcasing the effectiveness of our proposed method. The code will be released soon.
Knowledge Condensation and Reasoning for Knowledge-based VQA
Mar 15, 2024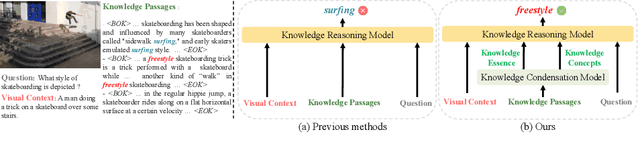
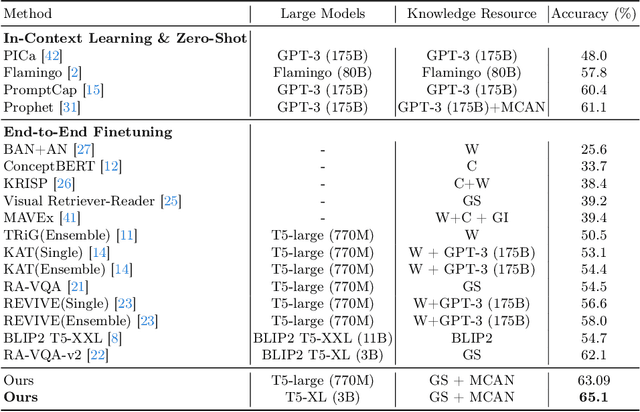
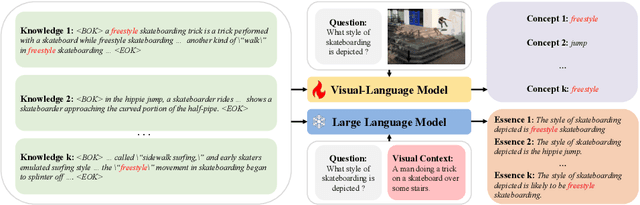
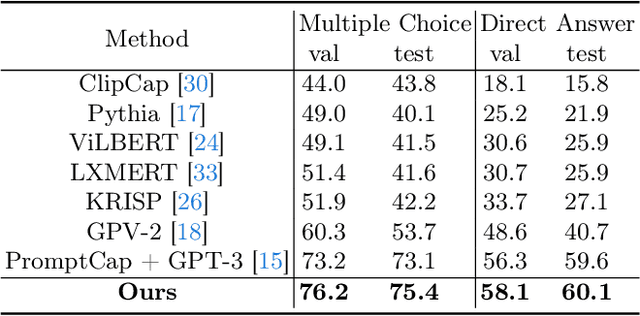
Knowledge-based visual question answering (KB-VQA) is a challenging task, which requires the model to leverage external knowledge for comprehending and answering questions grounded in visual content. Recent studies retrieve the knowledge passages from external knowledge bases and then use them to answer questions. However, these retrieved knowledge passages often contain irrelevant or noisy information, which limits the performance of the model. To address the challenge, we propose two synergistic models: Knowledge Condensation model and Knowledge Reasoning model. We condense the retrieved knowledge passages from two perspectives. First, we leverage the multimodal perception and reasoning ability of the visual-language models to distill concise knowledge concepts from retrieved lengthy passages, ensuring relevance to both the visual content and the question. Second, we leverage the text comprehension ability of the large language models to summarize and condense the passages into the knowledge essence which helps answer the question. These two types of condensed knowledge are then seamlessly integrated into our Knowledge Reasoning model, which judiciously navigates through the amalgamated information to arrive at the conclusive answer. Extensive experiments validate the superiority of the proposed method. Compared to previous methods, our method achieves state-of-the-art performance on knowledge-based VQA datasets (65.1% on OK-VQA and 60.1% on A-OKVQA) without resorting to the knowledge produced by GPT-3 (175B).