 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuvion VL: A Multimodal Foundation Model for Adversarial Content and AI Safety
Jun 23, 2026General-purpose models often struggle to reliably identify and understand real-world multimodal risks, largely due to the inherent multimodal adversarial nature of content and AI safety. We present Yuvion VL, a family of multimodal large language models purpose-built for content and AI safety, with both instruction-tuned and reasoning-oriented variants. Yuvion VL addresses this gap by treating safety as an inherently adversarial and multimodal problem and designing the entire pipeline around adversarial robustness. For data construction, we develop an automated pipeline integrating adversarial-aware data synthesis with multi-stage quality control, producing large-scale, high-quality multimodal samples augmented with domain knowledge and reasoning annotations. For training, we adopt a three-stage pipeline that includes continued pretraining for risk-concept cross-modal alignment, instruct post-training for production-grade safety tasks, and reasoning post-training for enhanced interpretability and performance in complex tasks. We further introduce Confuse-then-Contrast Fine-Tuning, a contrastive framework that mines model-specific confusions and constructs multi-image contrastive groups to enforce explicit discrimination of fine-grained visual-semantic elements, enabling the model to distinguish between visually similar cases with different safety implications in adversarial safety tasks. To support rigorous evaluation, we further introduce Yuvion VL RiskEval (YVRE), a collection of benchmarks covering diverse open and internal evaluations, with a focus on content and AI safety, adversarial robustness, and real-world capability requirements. Experiments show that Yuvion VL-32B achieves industry-leading safety performance, surpassing comparably sized open-source models and best closed-source commercial models, while maintaining comparable general capabilities.
Text-Video Multi-Grained Integration for Video Moment Montage
Dec 12, 2024The proliferation of online short video platforms has driven a surge in user demand for short video editing. However, manually selecting, cropping, and assembling raw footage into a coherent, high-quality video remains laborious and time-consuming. To accelerate this process, we focus on a user-friendly new task called Video Moment Montage (VMM), which aims to accurately locate the corresponding video segments based on a pre-provided narration text and then arrange these video clips to create a complete video that aligns with the corresponding descriptions. The challenge lies in extracting precise temporal segments while ensuring intra-sentence and inter-sentence context consistency, as a single script sentence may require trimming and assembling multiple video clips. To address this problem, we present a novel \textit{Text-Video Multi-Grained Integration} method (TV-MGI) that efficiently fuses text features from the script with both shot-level and frame-level video features, which enables the global and fine-grained alignment between the video content and the corresponding textual descriptions in the script. To facilitate further research in this area, we introduce the Multiple Sentences with Shots Dataset (MSSD), a large-scale dataset designed explicitly for the VMM task. We conduct extensive experiments on the MSSD dataset to demonstrate the effectiveness of our framework compared to baseline methods.
Training-free Subject-Enhanced Attention Guidance for Compositional Text-to-image Generation
May 11, 2024Existing subject-driven text-to-image generation models suffer from tedious fine-tuning steps and struggle to maintain both text-image alignment and subject fidelity. For generating compositional subjects, it often encounters problems such as object missing and attribute mixing, where some subjects in the input prompt are not generated or their attributes are incorrectly combined. To address these limitations, we propose a subject-driven generation framework and introduce training-free guidance to intervene in the generative process during inference time. This approach strengthens the attention map, allowing for precise attribute binding and feature injection for each subject. Notably, our method exhibits exceptional zero-shot generation ability, especially in the challenging task of compositional generation. Furthermore, we propose a novel metric GroundingScore to evaluate subject alignment thoroughly. The obtained quantitative results serve as compelling evidence showcasing the effectiveness of our proposed method. The code will be released soon.
Explainable Student Performance Prediction With Personalized Attention for Explaining Why A Student Fails
Oct 15, 2021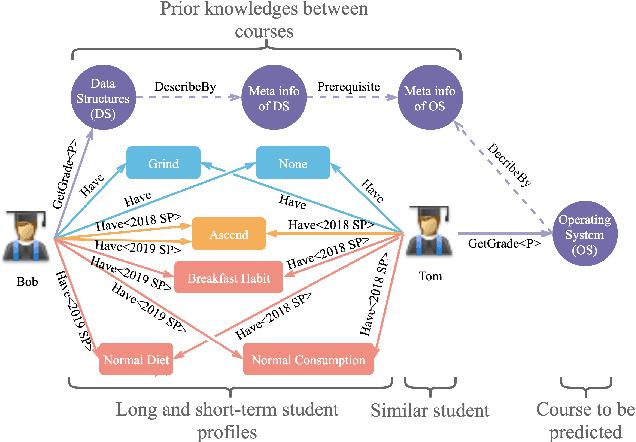
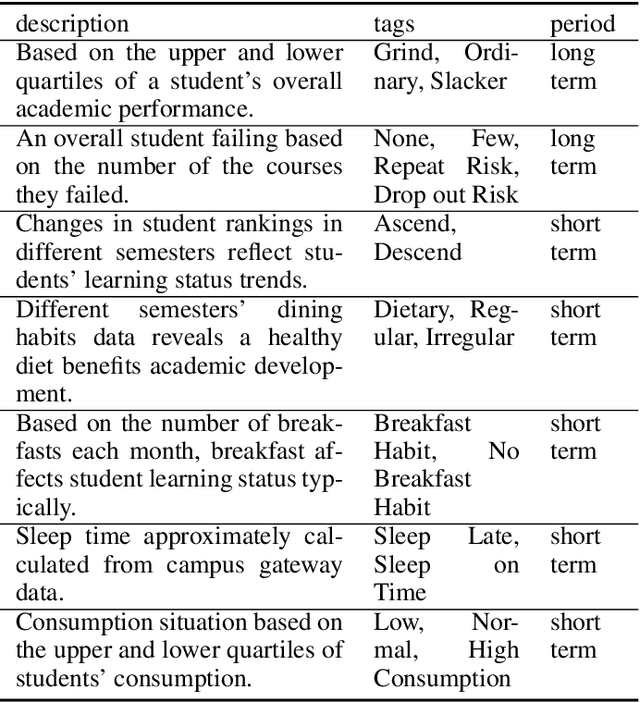
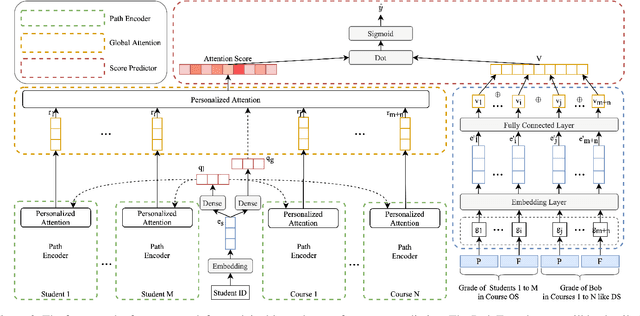
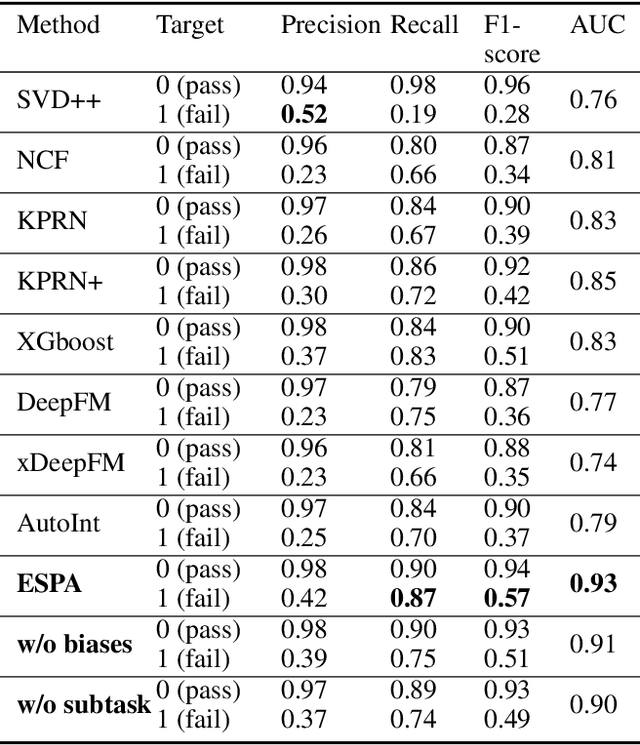
As student failure rates continue to increase in higher education, predicting student performance in the following semester has become a significant demand. Personalized student performance prediction helps educators gain a comprehensive view of student status and effectively intervene in advance. However, existing works scarcely consider the explainability of student performance prediction, which educators are most concerned about. In this paper, we propose a novel Explainable Student performance prediction method with Personalized Attention (ESPA) by utilizing relationships in student profiles and prior knowledge of related courses. The designed Bidirectional Long Short-Term Memory (BiLSTM) architecture extracts the semantic information in the paths with specific patterns. As for leveraging similar paths' internal relations, a local and global-level attention mechanism is proposed to distinguish the influence of different students or courses for making predictions. Hence, valid reasoning on paths can be applied to predict the performance of students. The ESPA consistently outperforms the other state-of-the-art models for student performance prediction, and the results are intuitively explainable. This work can help educators better understand the different impacts of behavior on students' studies.