 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive and Parallel Split Federated Learning in Vehicular Edge Computing
May 29, 2024



Vehicular edge intelligence (VEI) is a promising paradigm for enabling future intelligent transportation systems by accommodating artificial intelligence (AI) at the vehicular edge computing (VEC) system. Federated learning (FL) stands as one of the fundamental technologies facilitating collaborative model training locally and aggregation, while safeguarding the privacy of vehicle data in VEI. However, traditional FL faces challenges in adapting to vehicle heterogeneity, training large models on resource-constrained vehicles, and remaining susceptible to model weight privacy leakage. Meanwhile, split learning (SL) is proposed as a promising collaborative learning framework which can mitigate the risk of model wights leakage, and release the training workload on vehicles. SL sequentially trains a model between a vehicle and an edge cloud (EC) by dividing the entire model into a vehicle-side model and an EC-side model at a given cut layer. In this work, we combine the advantages of SL and FL to develop an Adaptive Split Federated Learning scheme for Vehicular Edge Computing (ASFV). The ASFV scheme adaptively splits the model and parallelizes the training process, taking into account mobile vehicle selection and resource allocation. Our extensive simulations, conducted on non-independent and identically distributed data, demonstrate that the proposed ASFV solution significantly reduces training latency compared to existing benchmarks, while adapting to network dynamics and vehicles' mobility.
SLOTH: Structured Learning and Task-based Optimization for Time Series Forecasting on Hierarchies
Feb 27, 2023
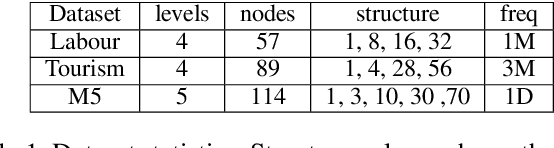
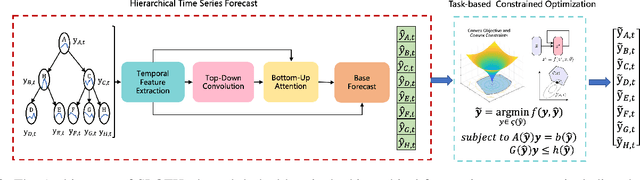
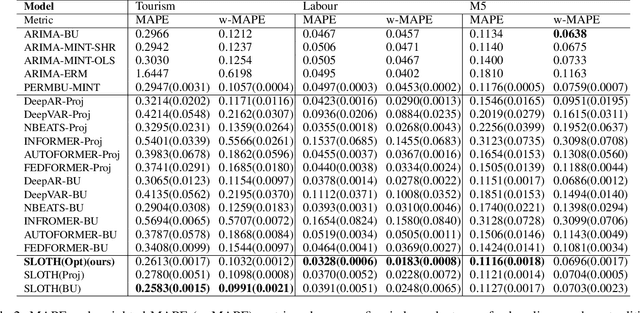
Multivariate time series forecasting with hierarchical structure is widely used in real-world applications, e.g., sales predictions for the geographical hierarchy formed by cities, states, and countries. The hierarchical time series (HTS) forecasting includes two sub-tasks, i.e., forecasting and reconciliation. In the previous works, hierarchical information is only integrated in the reconciliation step to maintain coherency, but not in forecasting step for accuracy improvement. In this paper, we propose two novel tree-based feature integration mechanisms, i.e., top-down convolution and bottom-up attention to leverage the information of the hierarchical structure to improve the forecasting performance. Moreover, unlike most previous reconciliation methods which either rely on strong assumptions or focus on coherent constraints only,we utilize deep neural optimization networks, which not only achieve coherency without any assumptions, but also allow more flexible and realistic constraints to achieve task-based targets, e.g., lower under-estimation penalty and meaningful decision-making loss to facilitate the subsequent downstream tasks. Experiments on real-world datasets demonstrate that our tree-based feature integration mechanism achieves superior performances on hierarchical forecasting tasks compared to the state-of-the-art methods, and our neural optimization networks can be applied to real-world tasks effectively without any additional effort under coherence and task-based constraints
End-to-End Modeling Hierarchical Time Series Using Autoregressive Transformer and Conditional Normalizing Flow based Reconciliation
Dec 28, 2022Multivariate time series forecasting with hierarchical structure is pervasive in real-world applications, demanding not only predicting each level of the hierarchy, but also reconciling all forecasts to ensure coherency, i.e., the forecasts should satisfy the hierarchical aggregation constraints. Moreover, the disparities of statistical characteristics between levels can be huge, worsened by non-Gaussian distributions and non-linear correlations. To this extent, we propose a novel end-to-end hierarchical time series forecasting model, based on conditioned normalizing flow-based autoregressive transformer reconciliation, to represent complex data distribution while simultaneously reconciling the forecasts to ensure coherency. Unlike other state-of-the-art methods, we achieve the forecasting and reconciliation simultaneously without requiring any explicit post-processing step. In addition, by harnessing the power of deep model, we do not rely on any assumption such as unbiased estimates or Gaussian distribution. Our evaluation experiments are conducted on four real-world hierarchical datasets from different industrial domains (three public ones and a dataset from the application servers of Alipay's data center) and the preliminary results demonstrate efficacy of our proposed method.
A Meta Reinforcement Learning Approach for Predictive Autoscaling in the Cloud
May 31, 2022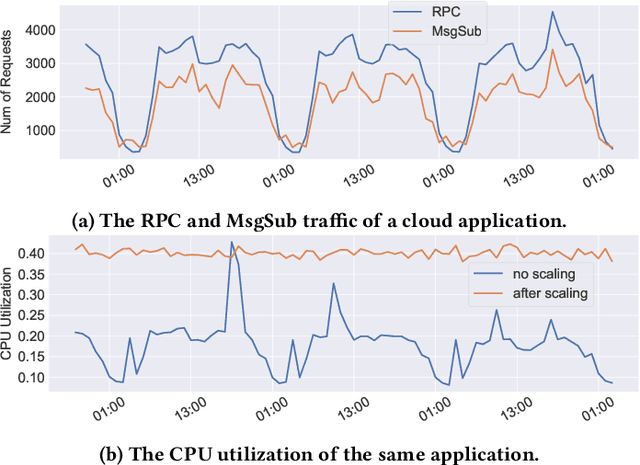

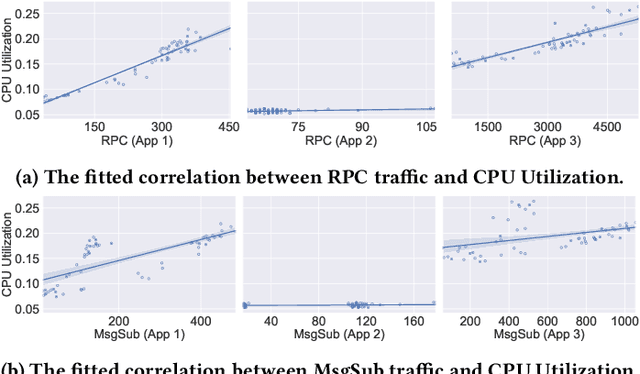

Predictive autoscaling (autoscaling with workload forecasting) is an important mechanism that supports autonomous adjustment of computing resources in accordance with fluctuating workload demands in the Cloud. In recent works, Reinforcement Learning (RL) has been introduced as a promising approach to learn the resource management policies to guide the scaling actions under the dynamic and uncertain cloud environment. However, RL methods face the following challenges in steering predictive autoscaling, such as lack of accuracy in decision-making, inefficient sampling and significant variability in workload patterns that may cause policies to fail at test time. To this end, we propose an end-to-end predictive meta model-based RL algorithm, aiming to optimally allocate resource to maintain a stable CPU utilization level, which incorporates a specially-designed deep periodic workload prediction model as the input and embeds the Neural Process to guide the learning of the optimal scaling actions over numerous application services in the Cloud. Our algorithm not only ensures the predictability and accuracy of the scaling strategy, but also enables the scaling decisions to adapt to the changing workloads with high sample efficiency. Our method has achieved significant performance improvement compared to the existing algorithms and has been deployed online at Alipay, supporting the autoscaling of applications for the world-leading payment platform.