 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive and Parallel Split Federated Learning in Vehicular Edge Computing
May 29, 2024



Vehicular edge intelligence (VEI) is a promising paradigm for enabling future intelligent transportation systems by accommodating artificial intelligence (AI) at the vehicular edge computing (VEC) system. Federated learning (FL) stands as one of the fundamental technologies facilitating collaborative model training locally and aggregation, while safeguarding the privacy of vehicle data in VEI. However, traditional FL faces challenges in adapting to vehicle heterogeneity, training large models on resource-constrained vehicles, and remaining susceptible to model weight privacy leakage. Meanwhile, split learning (SL) is proposed as a promising collaborative learning framework which can mitigate the risk of model wights leakage, and release the training workload on vehicles. SL sequentially trains a model between a vehicle and an edge cloud (EC) by dividing the entire model into a vehicle-side model and an EC-side model at a given cut layer. In this work, we combine the advantages of SL and FL to develop an Adaptive Split Federated Learning scheme for Vehicular Edge Computing (ASFV). The ASFV scheme adaptively splits the model and parallelizes the training process, taking into account mobile vehicle selection and resource allocation. Our extensive simulations, conducted on non-independent and identically distributed data, demonstrate that the proposed ASFV solution significantly reduces training latency compared to existing benchmarks, while adapting to network dynamics and vehicles' mobility.
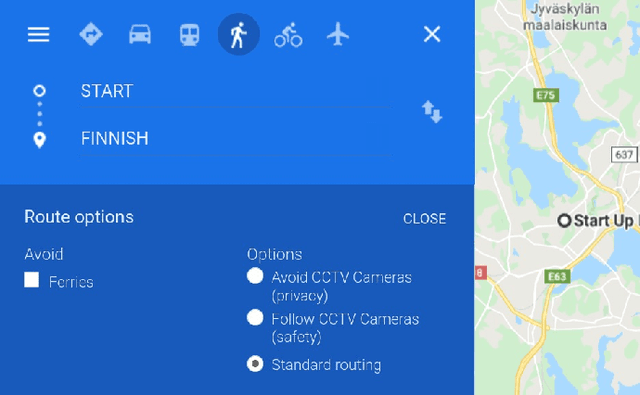
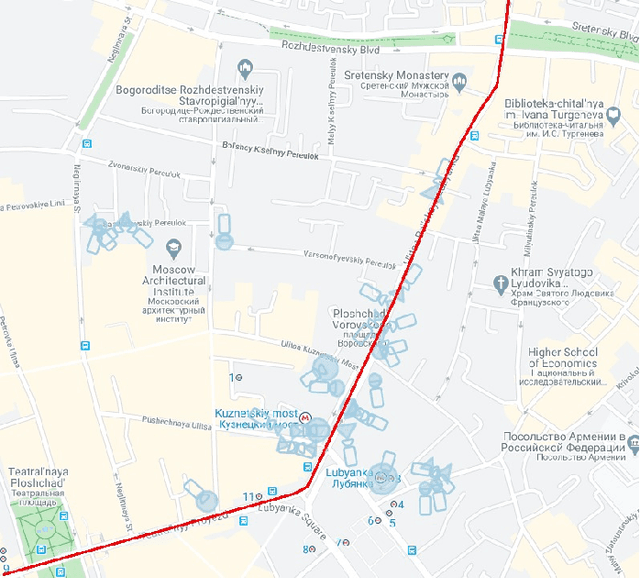
OSRM-CCTV: Open-source CCTV-aware routing and navigation system for privacy, anonymity and safety
Aug 20, 2021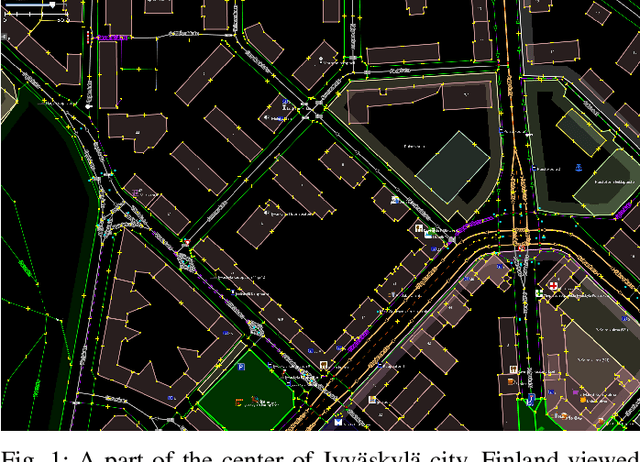
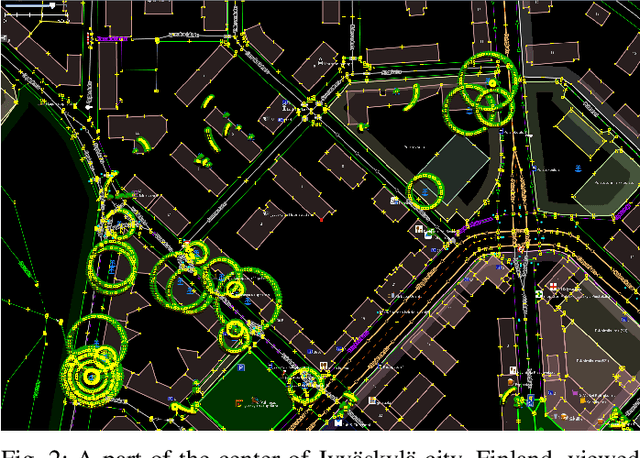

For the last several decades, the increased, widespread, unwarranted, and unaccountable use of Closed-Circuit TeleVision (CCTV) cameras globally has raised concerns about privacy risks. Additional recent features of many CCTV cameras, such as Internet of Things (IoT) connectivity and Artificial Intelligence (AI)-based facial recognition, only increase concerns among privacy advocates. Therefore, on par \emph{CCTV-aware solutions} must exist that provide privacy, safety, and cybersecurity features. We argue that an important step forward is to develop solutions addressing privacy concerns via routing and navigation systems (e.g., OpenStreetMap, Google Maps) that provide both privacy and safety options for areas where cameras are known to be present. However, at present no routing and navigation system, whether online or offline, provide corresponding CCTV-aware functionality. In this paper we introduce OSRM-CCTV -- the first and only CCTV-aware routing and navigation system designed and built for privacy, anonymity and safety applications. We validate and demonstrate the effectiveness and usability of the system on a handful of synthetic and real-world examples. To help validate our work as well as to further encourage the development and wide adoption of the system, we release OSRM-CCTV as open-source.
Towards large-scale, automated, accurate detection of CCTV camera objects using computer vision. Applications and implications for privacy, safety, and cybersecurity. (Preprint)
Jun 06, 2020
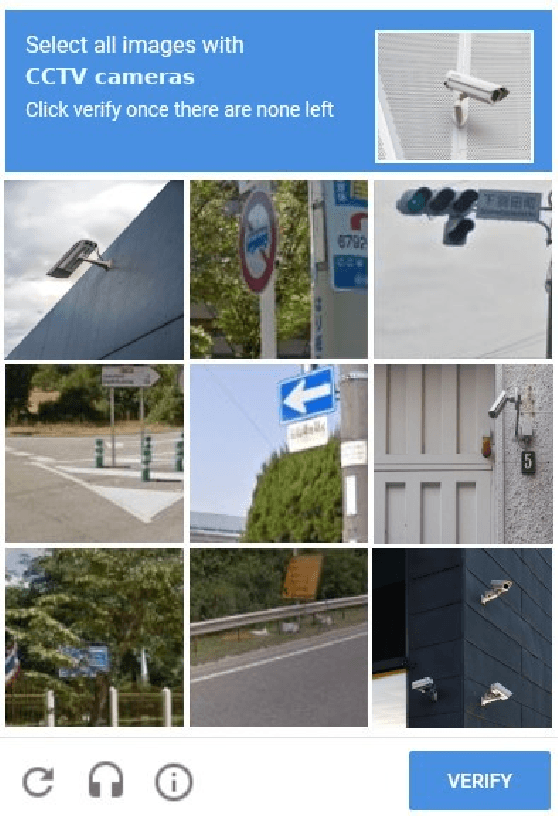
While the first CCTV camera was developed almost a century ago back in 1927, currently it is assumed as granted there are about 770 millions CCTV cameras around the globe, and their number is casually predicted to surpass 1 billion in 2021. At the same time the increasing, widespread, unwarranted, and unaccountable use of CCTV cameras globally raises privacy risks and concerns for the last several decades. Recent technological advances implemented in CCTV cameras such as AI-based facial recognition and IoT connectivity only fuel further these concerns raised by privacy-minded persons. However, many of the debates, reports, and policies are based on assumptions and numbers that are neither necessarily factually accurate nor are based on sound methodologies. For example, at present there is no accurate and global understanding of how many CCTV cameras are deployed and in use, where are those cameras located, who owns or operates those cameras, etc. In addition, there are no proper (i.e., sound, accurate, advanced) tools that can help us achieve such counting, localization, and other information gathering. Therefore, new methods and tools must be developed in order to detect, count, and localize the CCTV cameras. To close this gap, with this paper we introduce the first and only computer vision MS COCO-compatible models that are able to accurately detect CCTV and video surveillance cameras in images and video frames. To this end, our state-of-the-art detector was built using 3401 images that were manually reviewed and annotated, and achieves an accuracy between 91,1% - 95,6%. Moreover, we build and evaluate multiple models, present a comprehensive comparison of their performance, and outline core challenges associated with such research. We also present possible privacy-, safety-, and security-related practical applications of our core work.