 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Large-scale Universal User Representation with Sparse Mixture of Experts
Jul 11, 2022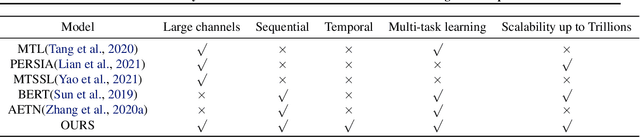
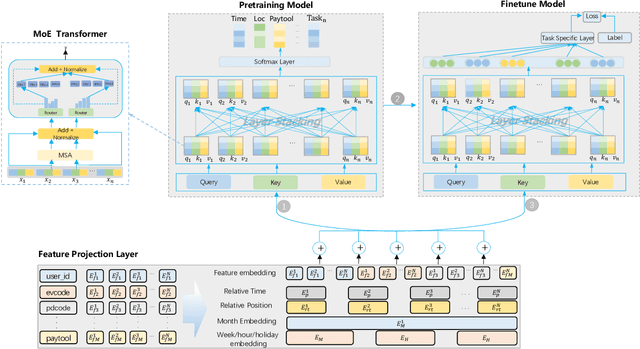
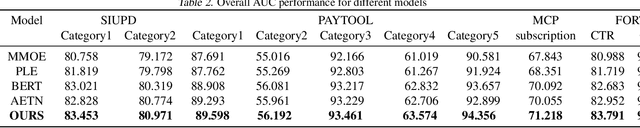
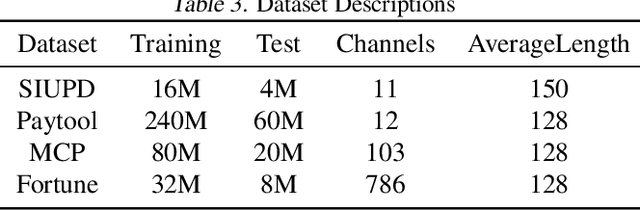
Learning user sequence behaviour embedding is very sophisticated and challenging due to the complicated feature interactions over time and high dimensions of user features. Recent emerging foundation models, e.g., BERT and its variants, encourage a large body of researchers to investigate in this field. However, unlike natural language processing (NLP) tasks, the parameters of user behaviour model come mostly from user embedding layer, which makes most existing works fail in training a universal user embedding of large scale. Furthermore, user representations are learned from multiple downstream tasks, and the past research work do not address the seesaw phenomenon. In this paper, we propose SUPERMOE, a generic framework to obtain high quality user representation from multiple tasks. Specifically, the user behaviour sequences are encoded by MoE transformer, and we can thus increase the model capacity to billions of parameters, or even to trillions of parameters. In order to deal with seesaw phenomenon when learning across multiple tasks, we design a new loss function with task indicators. We perform extensive offline experiments on public datasets and online experiments on private real-world business scenarios. Our approach achieves the best performance over state-of-the-art models, and the results demonstrate the effectiveness of our framework.
* Accepted by ICML 2022 Pre-training Workshop