 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMCE-Net++: Feature Map Convergence Evaluation and Training
Aug 08, 2025Deep Neural Networks (DNNs) face interpretability challenges due to their opaque internal representations. While Feature Map Convergence Evaluation (FMCE) quantifies module-level convergence via Feature Map Convergence Scores (FMCS), it lacks experimental validation and closed-loop integration. To address this limitation, we propose FMCE-Net++, a novel training framework that integrates a pretrained, frozen FMCE-Net as an auxiliary head. This module generates FMCS predictions, which, combined with task labels, jointly supervise backbone optimization through a Representation Auxiliary Loss. The RAL dynamically balances the primary classification loss and feature convergence optimization via a tunable \Representation Abstraction Factor. Extensive experiments conducted on MNIST, CIFAR-10, FashionMNIST, and CIFAR-100 demonstrate that FMCE-Net++ consistently enhances model performance without architectural modifications or additional data. Key experimental outcomes include accuracy gains of $+1.16$ pp (ResNet-50/CIFAR-10) and $+1.08$ pp (ShuffleNet v2/CIFAR-100), validating that FMCE-Net++ can effectively elevate state-of-the-art performance ceilings.
Learning Large-scale Universal User Representation with Sparse Mixture of Experts
Jul 11, 2022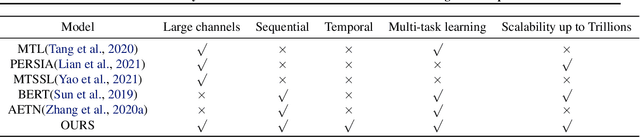
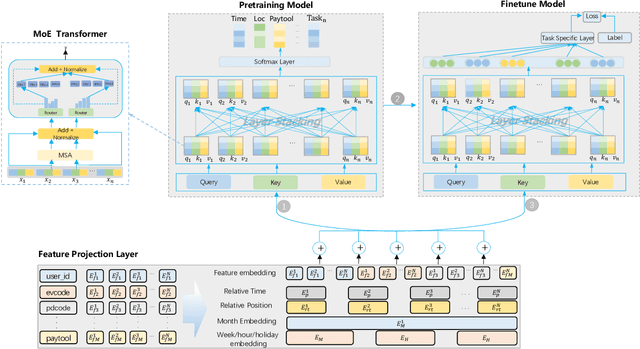
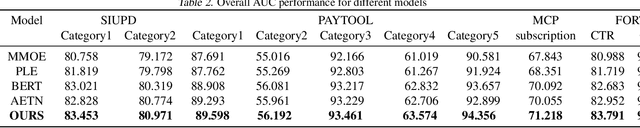
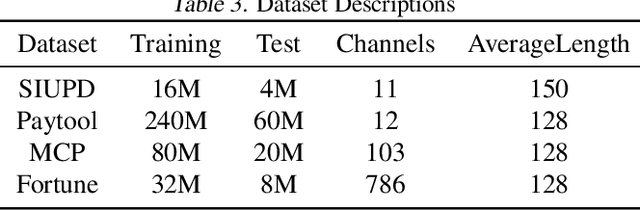
Learning user sequence behaviour embedding is very sophisticated and challenging due to the complicated feature interactions over time and high dimensions of user features. Recent emerging foundation models, e.g., BERT and its variants, encourage a large body of researchers to investigate in this field. However, unlike natural language processing (NLP) tasks, the parameters of user behaviour model come mostly from user embedding layer, which makes most existing works fail in training a universal user embedding of large scale. Furthermore, user representations are learned from multiple downstream tasks, and the past research work do not address the seesaw phenomenon. In this paper, we propose SUPERMOE, a generic framework to obtain high quality user representation from multiple tasks. Specifically, the user behaviour sequences are encoded by MoE transformer, and we can thus increase the model capacity to billions of parameters, or even to trillions of parameters. In order to deal with seesaw phenomenon when learning across multiple tasks, we design a new loss function with task indicators. We perform extensive offline experiments on public datasets and online experiments on private real-world business scenarios. Our approach achieves the best performance over state-of-the-art models, and the results demonstrate the effectiveness of our framework.
* Accepted by ICML 2022 Pre-training Workshop
MixSeq: Connecting Macroscopic Time Series Forecasting with Microscopic Time Series Data
Oct 27, 2021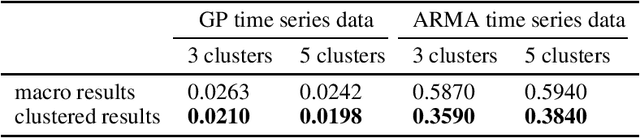


Time series forecasting is widely used in business intelligence, e.g., forecast stock market price, sales, and help the analysis of data trend. Most time series of interest are macroscopic time series that are aggregated from microscopic data. However, instead of directly modeling the macroscopic time series, rare literature studied the forecasting of macroscopic time series by leveraging data on the microscopic level. In this paper, we assume that the microscopic time series follow some unknown mixture probabilistic distributions. We theoretically show that as we identify the ground truth latent mixture components, the estimation of time series from each component could be improved because of lower variance, thus benefitting the estimation of macroscopic time series as well. Inspired by the power of Seq2seq and its variants on the modeling of time series data, we propose Mixture of Seq2seq (MixSeq), an end2end mixture model to cluster microscopic time series, where all the components come from a family of Seq2seq models parameterized by different parameters. Extensive experiments on both synthetic and real-world data show the superiority of our approach.