 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Functional trustworthiness of AI systems by statistically valid testing
Oct 04, 2023The authors are concerned about the safety, health, and rights of the European citizens due to inadequate measures and procedures required by the current draft of the EU Artificial Intelligence (AI) Act for the conformity assessment of AI systems. We observe that not only the current draft of the EU AI Act, but also the accompanying standardization efforts in CEN/CENELEC, have resorted to the position that real functional guarantees of AI systems supposedly would be unrealistic and too complex anyways. Yet enacting a conformity assessment procedure that creates the false illusion of trust in insufficiently assessed AI systems is at best naive and at worst grossly negligent. The EU AI Act thus misses the point of ensuring quality by functional trustworthiness and correctly attributing responsibilities. The trustworthiness of an AI decision system lies first and foremost in the correct statistical testing on randomly selected samples and in the precision of the definition of the application domain, which enables drawing samples in the first place. We will subsequently call this testable quality functional trustworthiness. It includes a design, development, and deployment that enables correct statistical testing of all relevant functions. We are firmly convinced and advocate that a reliable assessment of the statistical functional properties of an AI system has to be the indispensable, mandatory nucleus of the conformity assessment. In this paper, we describe the three necessary elements to establish a reliable functional trustworthiness, i.e., (1) the definition of the technical distribution of the application, (2) the risk-based minimum performance requirements, and (3) the statistically valid testing based on independent random samples.
Trusted Artificial Intelligence: Towards Certification of Machine Learning Applications
Mar 31, 2021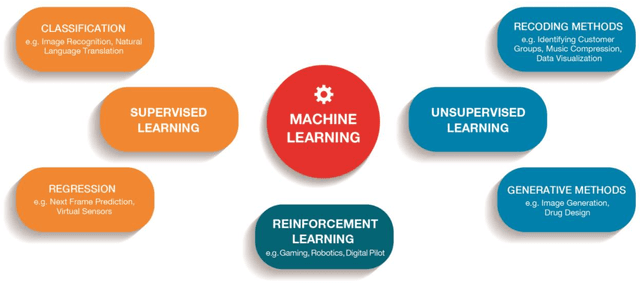

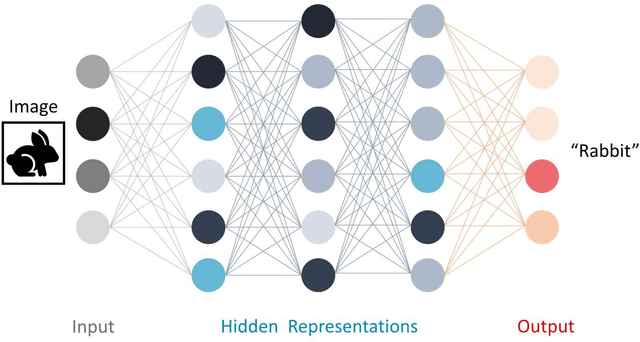
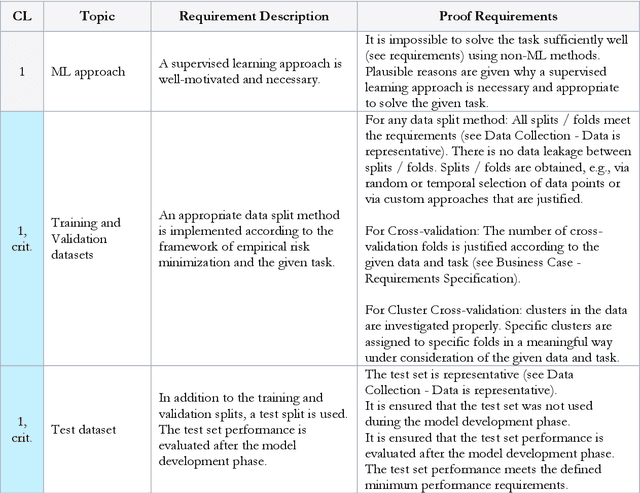
Artificial Intelligence is one of the fastest growing technologies of the 21st century and accompanies us in our daily lives when interacting with technical applications. However, reliance on such technical systems is crucial for their widespread applicability and acceptance. The societal tools to express reliance are usually formalized by lawful regulations, i.e., standards, norms, accreditations, and certificates. Therefore, the T\"UV AUSTRIA Group in cooperation with the Institute for Machine Learning at the Johannes Kepler University Linz, proposes a certification process and an audit catalog for Machine Learning applications. We are convinced that our approach can serve as the foundation for the certification of applications that use Machine Learning and Deep Learning, the techniques that drive the current revolution in Artificial Intelligence. While certain high-risk areas, such as fully autonomous robots in workspaces shared with humans, are still some time away from certification, we aim to cover low-risk applications with our certification procedure. Our holistic approach attempts to analyze Machine Learning applications from multiple perspectives to evaluate and verify the aspects of secure software development, functional requirements, data quality, data protection, and ethics. Inspired by existing work, we introduce four criticality levels to map the criticality of a Machine Learning application regarding the impact of its decisions on people, environment, and organizations. Currently, the audit catalog can be applied to low-risk applications within the scope of supervised learning as commonly encountered in industry. Guided by field experience, scientific developments, and market demands, the audit catalog will be extended and modified accordingly.
Patch Refinement -- Localized 3D Object Detection
Oct 09, 2019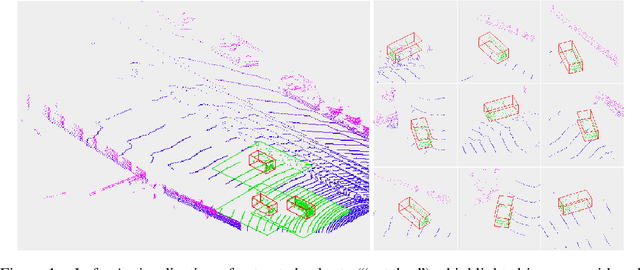
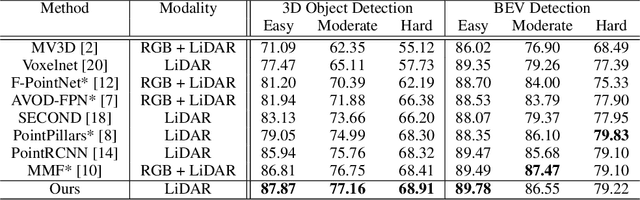
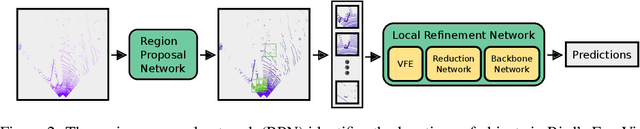
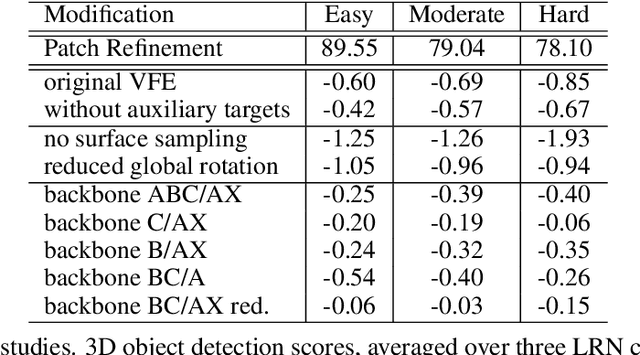
We introduce Patch Refinement a two-stage model for accurate 3D object detection and localization from point cloud data. Patch Refinement is composed of two independently trained Voxelnet-based networks, a Region Proposal Network (RPN) and a Local Refinement Network (LRN). We decompose the detection task into a preliminary Bird's Eye View (BEV) detection step and a local 3D detection step. Based on the proposed BEV locations by the RPN, we extract small point cloud subsets ("patches"), which are then processed by the LRN, which is less limited by memory constraints due to the small area of each patch. Therefore, we can apply encoding with a higher voxel resolution locally. The independence of the LRN enables the use of additional augmentation techniques and allows for an efficient, regression focused training as it uses only a small fraction of each scene. Evaluated on the KITTI 3D object detection benchmark, our submission from January 28, 2019, outperformed all previous entries on all three difficulties of the class car, using only 50 % of the available training data and only LiDAR information.
Coulomb GANs: Provably Optimal Nash Equilibria via Potential Fields
Jan 30, 2018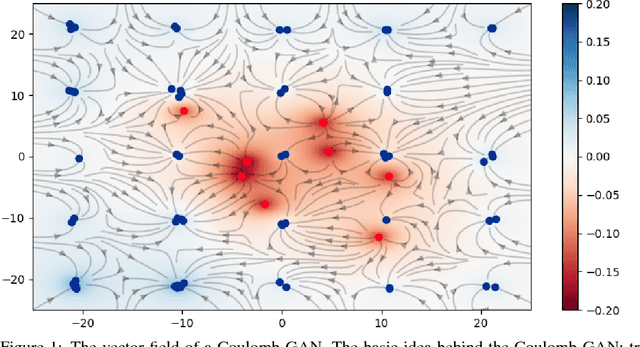
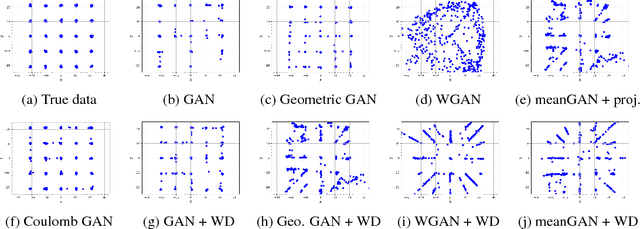


Generative adversarial networks (GANs) evolved into one of the most successful unsupervised techniques for generating realistic images. Even though it has recently been shown that GAN training converges, GAN models often end up in local Nash equilibria that are associated with mode collapse or otherwise fail to model the target distribution. We introduce Coulomb GANs, which pose the GAN learning problem as a potential field of charged particles, where generated samples are attracted to training set samples but repel each other. The discriminator learns a potential field while the generator decreases the energy by moving its samples along the vector (force) field determined by the gradient of the potential field. Through decreasing the energy, the GAN model learns to generate samples according to the whole target distribution and does not only cover some of its modes. We prove that Coulomb GANs possess only one Nash equilibrium which is optimal in the sense that the model distribution equals the target distribution. We show the efficacy of Coulomb GANs on a variety of image datasets. On LSUN and celebA, Coulomb GANs set a new state of the art and produce a previously unseen variety of different samples.
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
Jan 12, 2018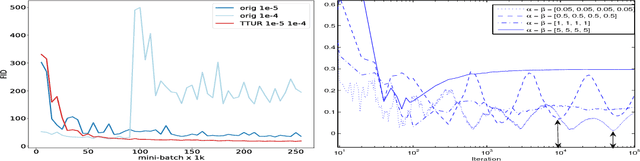
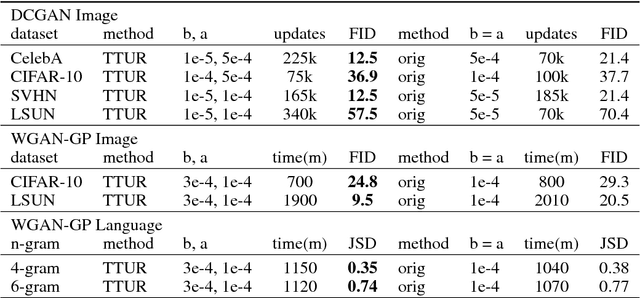
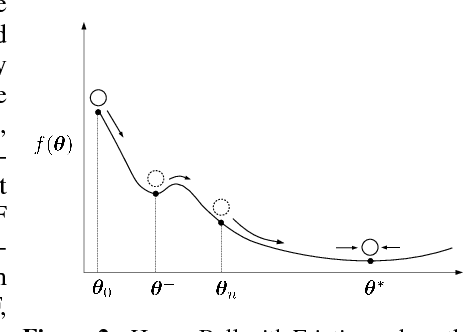
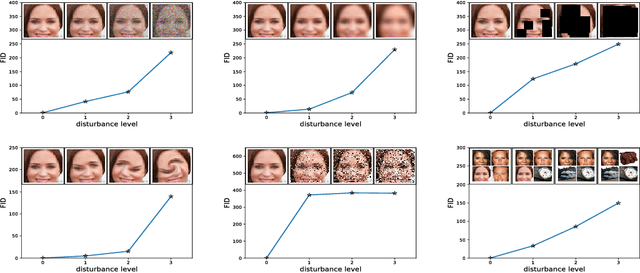
Generative Adversarial Networks (GANs) excel at creating realistic images with complex models for which maximum likelihood is infeasible. However, the convergence of GAN training has still not been proved. We propose a two time-scale update rule (TTUR) for training GANs with stochastic gradient descent on arbitrary GAN loss functions. TTUR has an individual learning rate for both the discriminator and the generator. Using the theory of stochastic approximation, we prove that the TTUR converges under mild assumptions to a stationary local Nash equilibrium. The convergence carries over to the popular Adam optimization, for which we prove that it follows the dynamics of a heavy ball with friction and thus prefers flat minima in the objective landscape. For the evaluation of the performance of GANs at image generation, we introduce the "Fr\'echet Inception Distance" (FID) which captures the similarity of generated images to real ones better than the Inception Score. In experiments, TTUR improves learning for DCGANs and Improved Wasserstein GANs (WGAN-GP) outperforming conventional GAN training on CelebA, CIFAR-10, SVHN, LSUN Bedrooms, and the One Billion Word Benchmark.
* Implementations are available at: https://github.com/bioinf-jku/TTUR