 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch Refinement -- Localized 3D Object Detection
Oct 09, 2019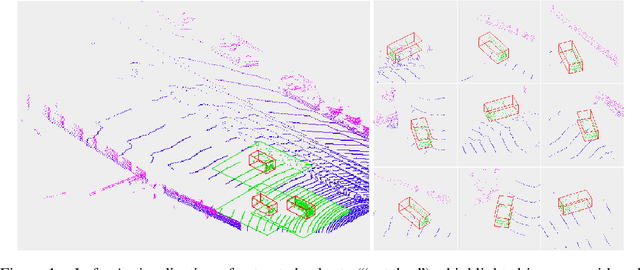
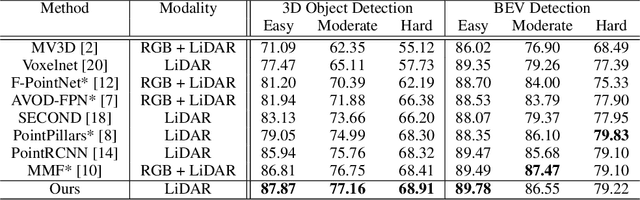
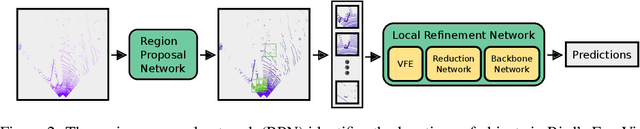
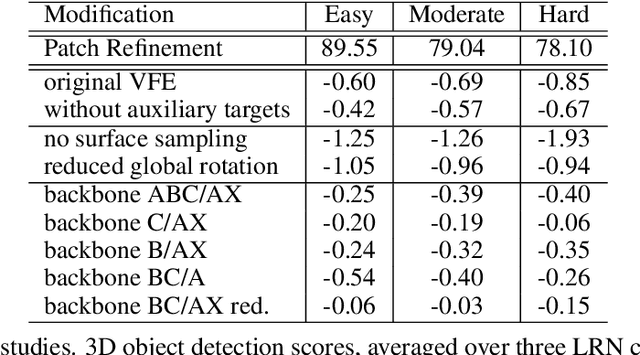
We introduce Patch Refinement a two-stage model for accurate 3D object detection and localization from point cloud data. Patch Refinement is composed of two independently trained Voxelnet-based networks, a Region Proposal Network (RPN) and a Local Refinement Network (LRN). We decompose the detection task into a preliminary Bird's Eye View (BEV) detection step and a local 3D detection step. Based on the proposed BEV locations by the RPN, we extract small point cloud subsets ("patches"), which are then processed by the LRN, which is less limited by memory constraints due to the small area of each patch. Therefore, we can apply encoding with a higher voxel resolution locally. The independence of the LRN enables the use of additional augmentation techniques and allows for an efficient, regression focused training as it uses only a small fraction of each scene. Evaluated on the KITTI 3D object detection benchmark, our submission from January 28, 2019, outperformed all previous entries on all three difficulties of the class car, using only 50 % of the available training data and only LiDAR information.