 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaravan MultiMet: Extending Caravan with Multiple Weather Nowcasts and Forecasts
Nov 14, 2024The Caravan large-sample hydrology dataset (Kratzert et al., 2023) was created to standardize and harmonize streamflow data from various regional datasets, combined with globally available meteorological forcing and catchment attributes. This community-driven project also allows researchers to conveniently extend the dataset for additional basins, as done 6 times to date (see https://github.com/kratzert/Caravan/discussions/10). We present a novel extension to Caravan, focusing on enriching the meteorological forcing data. Our extension adds three precipitation nowcast products (CPC, IMERG v07 Early, and CHIRPS) and three weather forecast products (ECMWF IFS HRES, GraphCast, and CHIRPS-GEFS) to the existing ERA5-Land reanalysis data. The inclusion of diverse data sources, particularly weather forecasts, enables more robust evaluation and benchmarking of hydrological models, especially for real-time forecasting scenarios. To the best of our knowledge, this extension makes Caravan the first large-sample hydrology dataset to incorporate weather forecast data, significantly enhancing its capabilities and fostering advancements in hydrological research, benchmarking, and real-time hydrologic forecasting. The data is publicly available under a CC-BY-4.0 license on Zenodo in two parts (https://zenodo.org/records/14161235, https://zenodo.org/records/14161281) and on Google Cloud Platform (GCP) - see more under the Data Availability chapter.
AI Increases Global Access to Reliable Flood Forecasts
Aug 10, 2023



Floods are one of the most common and impactful natural disasters, with a disproportionate impact in developing countries that often lack dense streamflow monitoring networks. Accurate and timely warnings are critical for mitigating flood risks, but accurate hydrological simulation models typically must be calibrated to long data records in each watershed where they are applied. We developed an Artificial Intelligence (AI) model to predict extreme hydrological events at timescales up to 7 days in advance. This model significantly outperforms current state of the art global hydrology models (the Copernicus Emergency Management Service Global Flood Awareness System) across all continents, lead times, and return periods. AI is especially effective at forecasting in ungauged basins, which is important because only a few percent of the world's watersheds have stream gauges, with a disproportionate number of ungauged basins in developing countries that are especially vulnerable to the human impacts of flooding. We produce forecasts of extreme events in South America and Africa that achieve reliability approaching the current state of the art in Europe and North America, and we achieve reliability at between 4 and 6-day lead times that are similar to current state of the art nowcasts (0-day lead time). Additionally, we achieve accuracies over 10-year return period events that are similar to current accuracies over 2-year return period events, meaning that AI can provide warnings earlier and over larger and more impactful events. The model that we develop in this paper has been incorporated into an operational early warning system that produces publicly available (free and open) forecasts in real time in over 80 countries. This work using AI and open data highlights a need for increasing the availability of hydrological data to continue to improve global access to reliable flood warnings.
Flood forecasting with machine learning models in an operational framework
Nov 04, 2021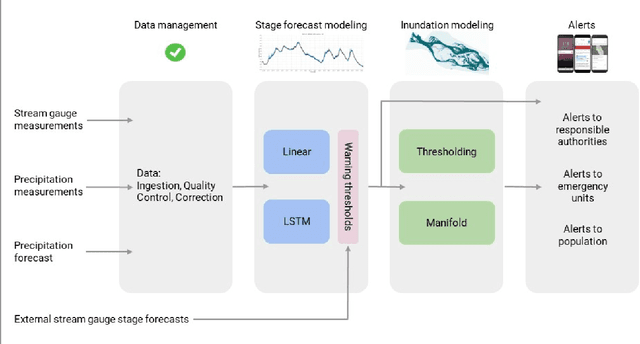
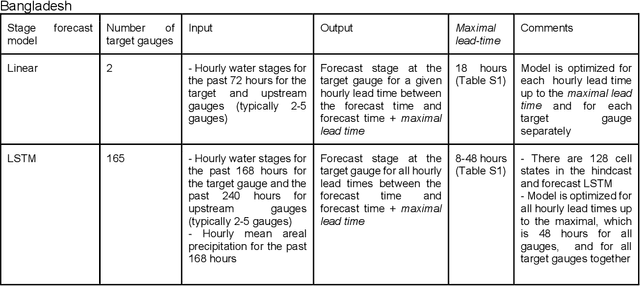
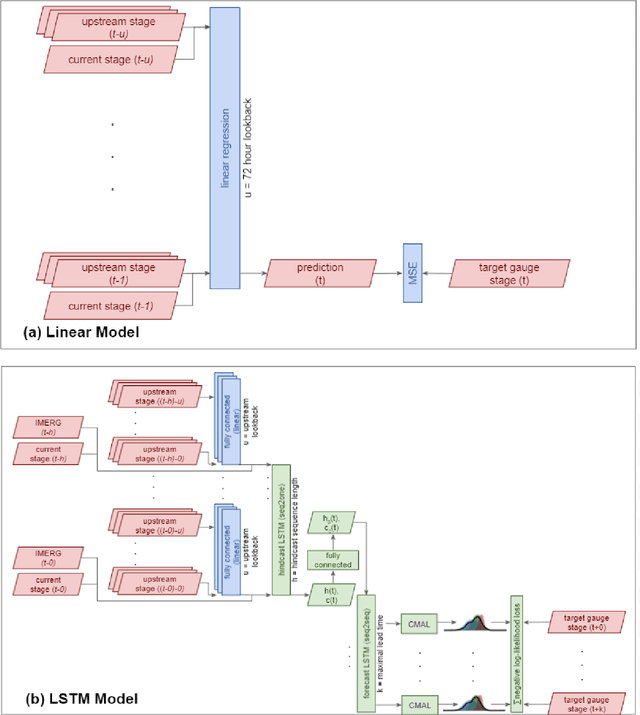
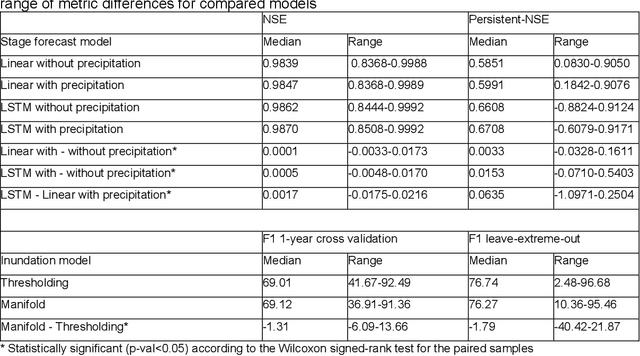
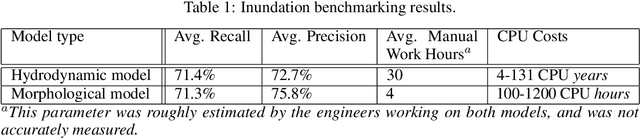
The operational flood forecasting system by Google was developed to provide accurate real-time flood warnings to agencies and the public, with a focus on riverine floods in large, gauged rivers. It became operational in 2018 and has since expanded geographically. This forecasting system consists of four subsystems: data validation, stage forecasting, inundation modeling, and alert distribution. Machine learning is used for two of the subsystems. Stage forecasting is modeled with the Long Short-Term Memory (LSTM) networks and the Linear models. Flood inundation is computed with the Thresholding and the Manifold models, where the former computes inundation extent and the latter computes both inundation extent and depth. The Manifold model, presented here for the first time, provides a machine-learning alternative to hydraulic modeling of flood inundation. When evaluated on historical data, all models achieve sufficiently high-performance metrics for operational use. The LSTM showed higher skills than the Linear model, while the Thresholding and Manifold models achieved similar performance metrics for modeling inundation extent. During the 2021 monsoon season, the flood warning system was operational in India and Bangladesh, covering flood-prone regions around rivers with a total area of 287,000 km2, home to more than 350M people. More than 100M flood alerts were sent to affected populations, to relevant authorities, and to emergency organizations. Current and future work on the system includes extending coverage to additional flood-prone locations, as well as improving modeling capabilities and accuracy.
ML-based Flood Forecasting: Advances in Scale, Accuracy and Reach
Dec 06, 2020
Floods are among the most common and deadly natural disasters in the world, and flood warning systems have been shown to be effective in reducing harm. Yet the majority of the world's vulnerable population does not have access to reliable and actionable warning systems, due to core challenges in scalability, computational costs, and data availability. In this paper we present two components of flood forecasting systems which were developed over the past year, providing access to these critical systems to 75 million people who didn't have this access before.
Accurate Hydrologic Modeling Using Less Information
Nov 21, 2019
Joint models are a common and important tool in the intersection of machine learning and the physical sciences, particularly in contexts where real-world measurements are scarce. Recent developments in rainfall-runoff modeling, one of the prime challenges in hydrology, show the value of a joint model with shared representation in this important context. However, current state-of-the-art models depend on detailed and reliable attributes characterizing each site to help the model differentiate correctly between the behavior of different sites. This dependency can present a challenge in data-poor regions. In this paper, we show that we can replace the need for such location-specific attributes with a completely data-driven learned embedding, and match previous state-of-the-art results with less information.
Benchmarking a Catchment-Aware Long Short-Term Memory Network (LSTM) for Large-Scale Hydrological Modeling
Jul 19, 2019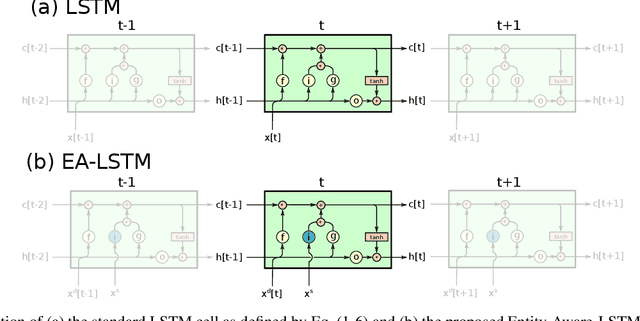



Regional rainfall-runoff modeling is an old but still mostly out-standing problem in Hydrological Sciences. The problem currently is that traditional hydrological models degrade significantly in performance when calibrated for multiple basins together instead of for a single basin alone. In this paper, we propose a novel, data-driven approach using Long Short-Term Memory networks (LSTMs), and demonstrate that under a 'big data' paradigm, this is not necessarily the case. By training a single LSTM model on 531 basins from the CAMELS data set using meteorological time series data and static catchment attributes, we were able to significantly improve performance compared to a set of several different hydrological benchmark models. Our proposed approach not only significantly outperforms hydrological models that were calibrated regionally but also achieves better performance than hydrological models that were calibrated for each basin individually. Furthermore, we propose an adaption to the standard LSTM architecture, which we call an Entity-Aware-LSTM (EA-LSTM), that allows for learning, and embedding as a feature layer in a deep learning model, catchment similarities. We show that this learned catchment similarity corresponds well with what we would expect from prior hydrological understanding.
ML for Flood Forecasting at Scale
Jan 28, 2019Effective riverine flood forecasting at scale is hindered by a multitude of factors, most notably the need to rely on human calibration in current methodology, the limited amount of data for a specific location, and the computational difficulty of building continent/global level models that are sufficiently accurate. Machine learning (ML) is primed to be useful in this scenario: learned models often surpass human experts in complex high-dimensional scenarios, and the framework of transfer or multitask learning is an appealing solution for leveraging local signals to achieve improved global performance. We propose to build on these strengths and develop ML systems for timely and accurate riverine flood prediction.
Towards Global Remote Discharge Estimation: Using the Few to Estimate The Many
Jan 03, 2019
Learning hydrologic models for accurate riverine flood prediction at scale is a challenge of great importance. One of the key difficulties is the need to rely on in-situ river discharge measurements, which can be quite scarce and unreliable, particularly in regions where floods cause the most damage every year. Accordingly, in this work we tackle the problem of river discharge estimation at different river locations. A core characteristic of the data at hand (e.g. satellite measurements) is that we have few measurements for many locations, all sharing the same physics that underlie the water discharge. We capture this scenario in a simple but powerful common mechanism regression (CMR) model with a local component as well as a shared one which captures the global discharge mechanism. The resulting learning objective is non-convex, but we show that we can find its global optimum by leveraging the power of joining local measurements across sites. In particular, using a spectral initialization with provable near-optimal accuracy, we can find the optimum using standard descent methods. We demonstrate the efficacy of our approach for the problem of discharge estimation using simulations.