 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal contrastive learning for remote sensing tasks
Paper and Code
Sep 06, 2022
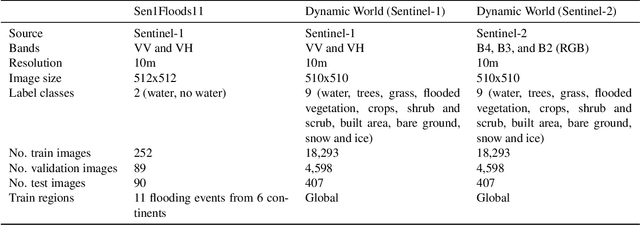

Self-supervised methods have shown tremendous success in the field of computer vision, including applications in remote sensing and medical imaging. Most popular contrastive-loss based methods like SimCLR, MoCo, MoCo-v2 use multiple views of the same image by applying contrived augmentations on the image to create positive pairs and contrast them with negative examples. Although these techniques work well, most of these techniques have been tuned on ImageNet (and similar computer vision datasets). While there have been some attempts to capture a richer set of deformations in the positive samples, in this work, we explore a promising alternative to generating positive examples for remote sensing data within the contrastive learning framework. Images captured from different sensors at the same location and nearby timestamps can be thought of as strongly augmented instances of the same scene, thus removing the need to explore and tune a set of hand crafted strong augmentations. In this paper, we propose a simple dual-encoder framework, which is pre-trained on a large unlabeled dataset (~1M) of Sentinel-1 and Sentinel-2 image pairs. We test the embeddings on two remote sensing downstream tasks: flood segmentation and land cover mapping, and empirically show that embeddings learnt from this technique outperform the conventional technique of collecting positive examples via aggressive data augmentations.