 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlocalNet: Class-aware Long-term Human Motion Synthesis
Dec 19, 2020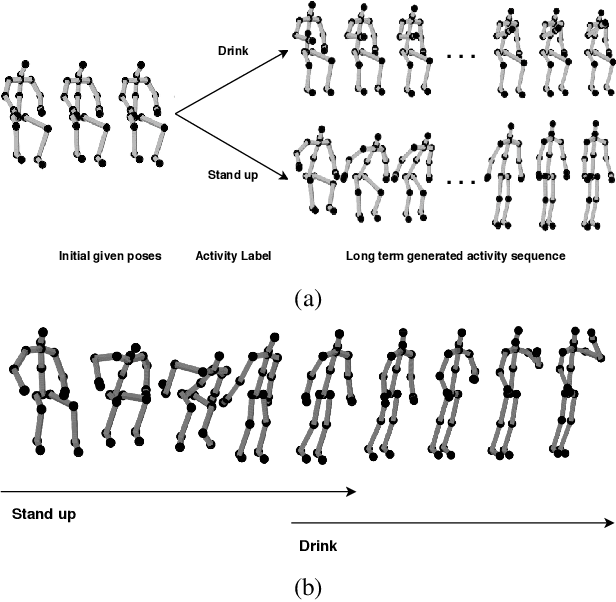
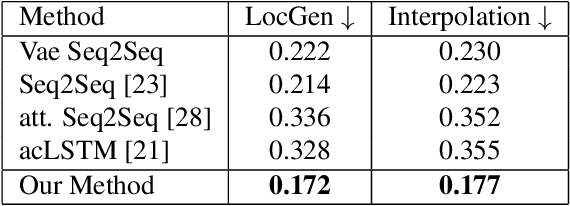
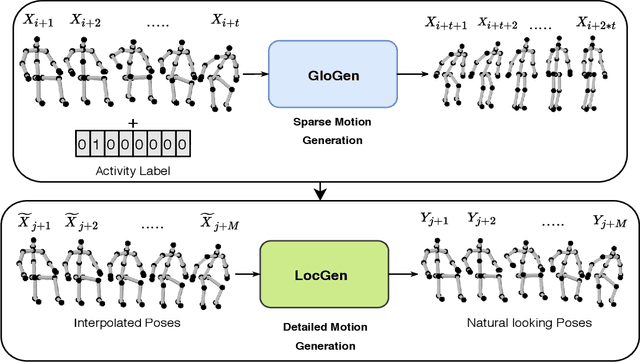
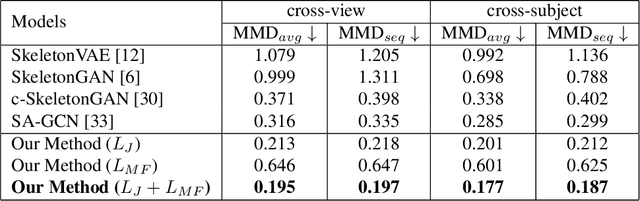
Synthesis of long-term human motion skeleton sequences is essential to aid human-centric video generation with potential applications in Augmented Reality, 3D character animations, pedestrian trajectory prediction, etc. Long-term human motion synthesis is a challenging task due to multiple factors like, long-term temporal dependencies among poses, cyclic repetition across poses, bi-directional and multi-scale dependencies among poses, variable speed of actions, and a large as well as partially overlapping space of temporal pose variations across multiple class/types of human activities. This paper aims to address these challenges to synthesize a long-term (> 6000 ms) human motion trajectory across a large variety of human activity classes (>50). We propose a two-stage activity generation method to achieve this goal, where the first stage deals with learning the long-term global pose dependencies in activity sequences by learning to synthesize a sparse motion trajectory while the second stage addresses the generation of dense motion trajectories taking the output of the first stage. We demonstrate the superiority of the proposed method over SOTA methods using various quantitative evaluation metrics on publicly available datasets.
* Appearing in 2021 IEEE Winter Conference on Applications of Computer Vision (WACV)
DeepHuMS: Deep Human Motion Signature for 3D Skeletal Sequences
Aug 19, 2019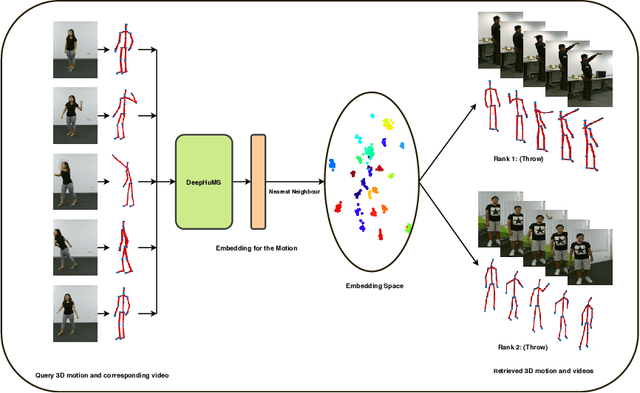
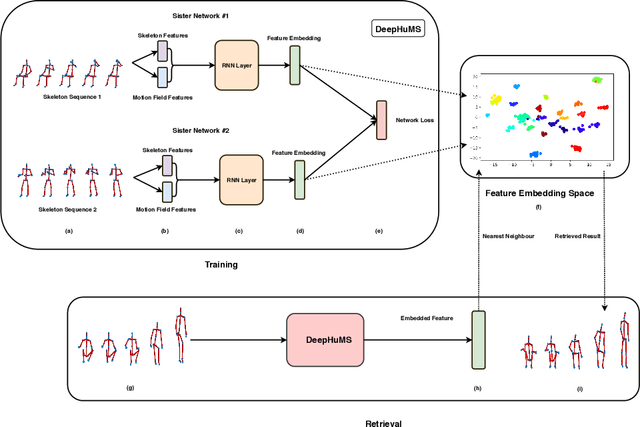
3D Human Motion Indexing and Retrieval is an interesting problem due to the rise of several data-driven applications aimed at analyzing and/or re-utilizing 3D human skeletal data, such as data-driven animation, analysis of sports bio-mechanics, human surveillance etc. Spatio-temporal articulations of humans, noisy/missing data, different speeds of the same motion etc. make it challenging and several of the existing state of the art methods use hand-craft features along with optimization based or histogram based comparison in order to perform retrieval. Further, they demonstrate it only for very small datasets and few classes. We make a case for using a learned representation that should recognize the motion as well as enforce a discriminative ranking. To that end, we propose, a 3D human motion descriptor learned using a deep network. Our learned embedding is generalizable and applicable to real-world data - addressing the aforementioned challenges and further enables sub-motion searching in its embedding space using another network. Our model exploits the inter-class similarity using trajectory cues, and performs far superior in a self-supervised setting. State of the art results on all these fronts is shown on two large scale 3D human motion datasets - NTU RGB+D and HDM05.
Curriculum Learning Strategies for Hindi-English Codemixed Sentiment Analysis
Jun 18, 2019
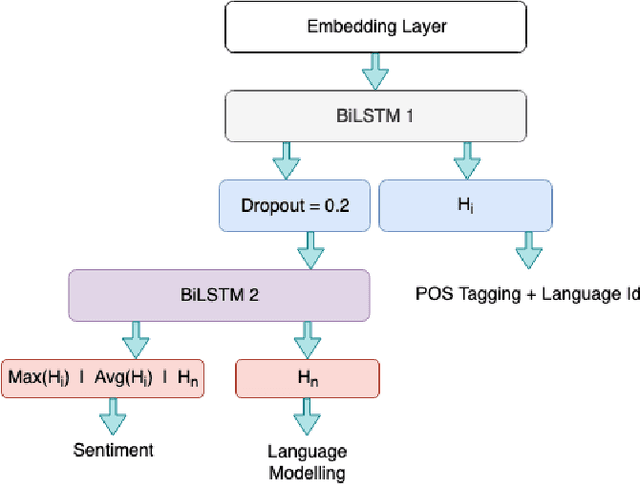


Sentiment Analysis and other semantic tasks are commonly used for social media textual analysis to gauge public opinion and make sense from the noise on social media. The language used on social media not only commonly diverges from the formal language, but is compounded by codemixing between languages, especially in large multilingual societies like India. Traditional methods for learning semantic NLP tasks have long relied on end to end task specific training, requiring expensive data creation process, even more so for deep learning methods. This challenge is even more severe for resource scarce texts like codemixed language pairs, with lack of well learnt representations as model priors, and task specific datasets can be few and small in quantities to efficiently exploit recent deep learning approaches. To address above challenges, we introduce curriculum learning strategies for semantic tasks in code-mixed Hindi-English (Hi-En) texts, and investigate various training strategies for enhancing model performance. Our method outperforms the state of the art methods for Hi-En codemixed sentiment analysis by 3.31% accuracy, and also shows better model robustness in terms of convergence, and variance in test performance.