 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCoFormer: A controllable feature-rich polyphonic music generation method
Paper and Code
Oct 15, 2023
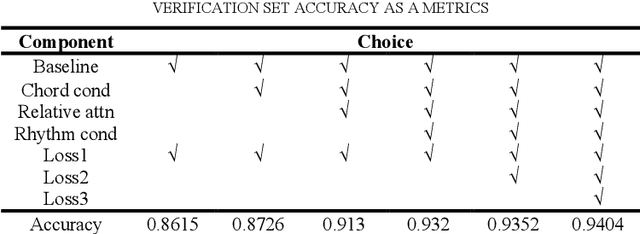
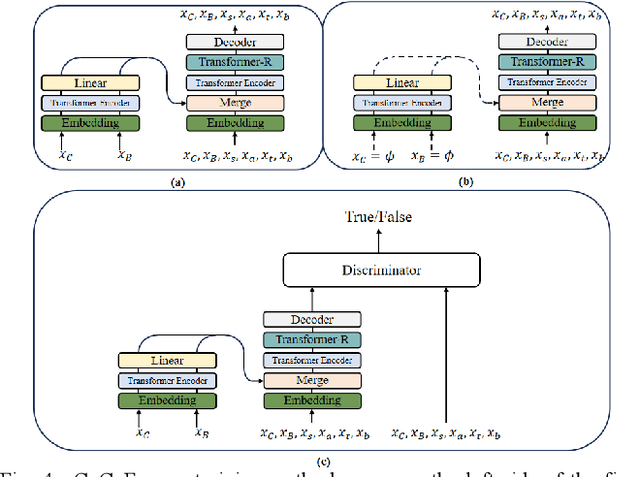
This paper explores the modeling method of polyphonic music sequence. Due to the great potential of Transformer models in music generation, controllable music generation is receiving more attention. In the task of polyphonic music, current controllable generation research focuses on controlling the generation of chords, but lacks precise adjustment for the controllable generation of choral music textures. This paper proposed Condition Choir Transformer (CoCoFormer) which controls the output of the model by controlling the chord and rhythm inputs at a fine-grained level. In this paper, the self-supervised method improves the loss function and performs joint training through conditional control input and unconditional input training. In order to alleviate the lack of diversity on generated samples caused by the teacher forcing training, this paper added an adversarial training method. CoCoFormer enhances model performance with explicit and implicit inputs to chords and rhythms. In this paper, the experiments proves that CoCoFormer has reached the current better level than current models. On the premise of specifying the polyphonic music texture, the same melody can also be generated in a variety of ways.