 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPT++: Customized Feature Representation for Siamese Visual Tracking
Oct 23, 2021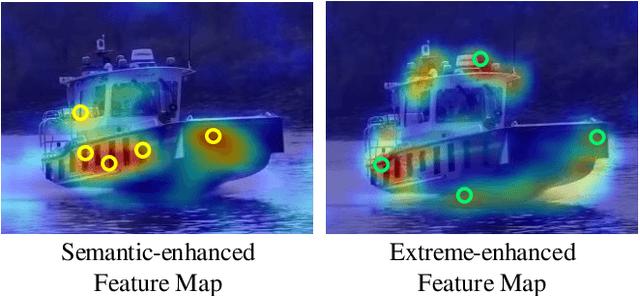


While recent years have witnessed remarkable progress in the feature representation of visual tracking, the problem of feature misalignment between the classification and regression tasks is largely overlooked. The approaches of feature extraction make no difference for these two tasks in most of advanced trackers. We argue that the performance gain of visual tracking is limited since features extracted from the salient area provide more recognizable visual patterns for classification, while these around the boundaries contribute to accurately estimating the target state. We address this problem by proposing two customized feature extractors, named polar pooling and extreme pooling to capture task-specific visual patterns. Polar pooling plays the role of enriching information collected from the semantic keypoints for stronger classification, while extreme pooling facilitates explicit visual patterns of the object boundary for accurate target state estimation. We demonstrate the effectiveness of the task-specific feature representation by integrating it into the recent and advanced tracker RPT. Extensive experiments on several benchmarks show that our Customized Features based RPT (RPT++) achieves new state-of-the-art performances on OTB-100, VOT2018, VOT2019, GOT-10k, TrackingNet and LaSOT.
RPT: Learning Point Set Representation for Siamese Visual Tracking
Sep 02, 2020

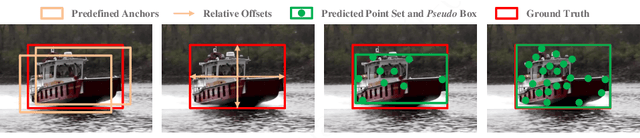
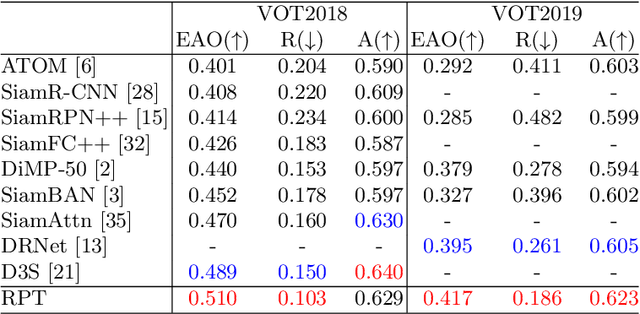
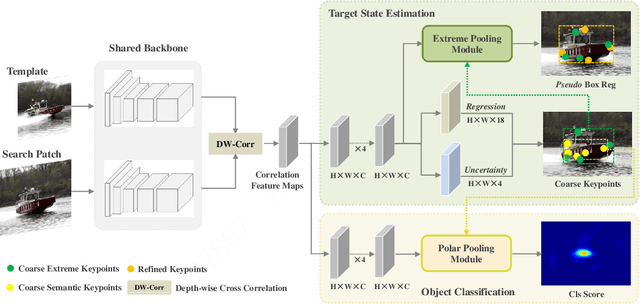
While remarkable progress has been made in robust visual tracking, accurate target state estimation still remains a highly challenging problem. In this paper, we argue that this issue is closely related to the prevalent bounding box representation, which provides only a coarse spatial extent of object. Thus an effcient visual tracking framework is proposed to accurately estimate the target state with a finer representation as a set of representative points. The point set is trained to indicate the semantically and geometrically significant positions of target region, enabling more fine-grained localization and modeling of object appearance. We further propose a multi-level aggregation strategy to obtain detailed structure information by fusing hierarchical convolution layers. Extensive experiments on several challenging benchmarks including OTB2015, VOT2018, VOT2019 and GOT-10k demonstrate that our method achieves new state-of-the-art performance while running at over 20 FPS.