 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLRover: An Elastic Deep Training Extension with Auto Job Resource Recommendation
Apr 04, 2023The cloud is still a popular platform for distributed deep learning (DL) training jobs since resource sharing in the cloud can improve resource utilization and reduce overall costs. However, such sharing also brings multiple challenges for DL training jobs, e.g., high-priority jobs could impact, even interrupt, low-priority jobs. Meanwhile, most existing distributed DL training systems require users to configure the resources (i.e., the number of nodes and resources like CPU and memory allocated to each node) of jobs manually before job submission and can not adjust the job's resources during the runtime. The resource configuration of a job deeply affect this job's performance (e.g., training throughput, resource utilization, and completion rate). However, this usually leads to poor performance of jobs since users fail to provide optimal resource configuration in most cases. \system~is a distributed DL framework can auto-configure a DL job's initial resources and dynamically tune the job's resources to win the better performance. With elastic capability, \system~can effectively adjusts the resources of a job when there are performance issues detected or a job fails because of faults or eviction. Evaluations results show \system~can outperform manual well-tuned resource configurations. Furthermore, in the production Kubernetes cluster of \company, \system~reduces the medium of job completion time by 31\%, and improves the job completion rate by 6\%, CPU utilization by 15\%, and memory utilization by 20\% compared with manual configuration.
Multi-View Partial Point Cloud Challenge 2021 on Completion and Registration: Methods and Results
Dec 22, 2021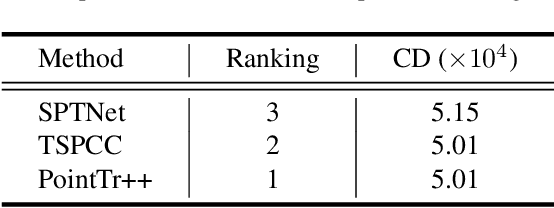
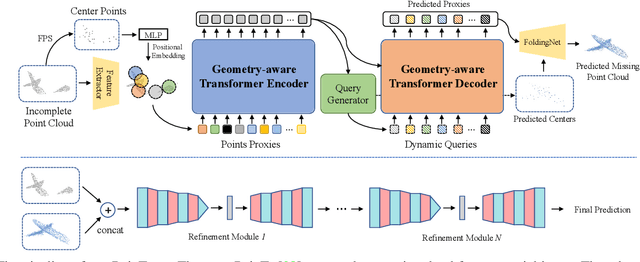
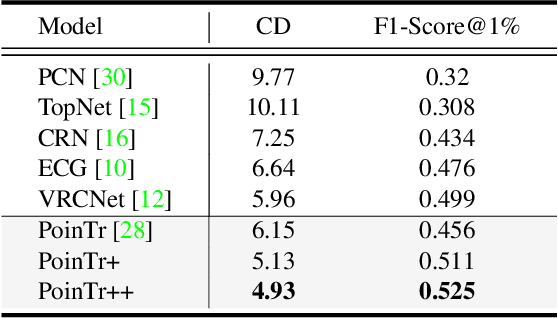
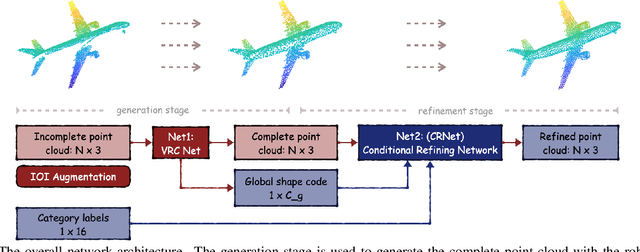
As real-scanned point clouds are mostly partial due to occlusions and viewpoints, reconstructing complete 3D shapes based on incomplete observations becomes a fundamental problem for computer vision. With a single incomplete point cloud, it becomes the partial point cloud completion problem. Given multiple different observations, 3D reconstruction can be addressed by performing partial-to-partial point cloud registration. Recently, a large-scale Multi-View Partial (MVP) point cloud dataset has been released, which consists of over 100,000 high-quality virtual-scanned partial point clouds. Based on the MVP dataset, this paper reports methods and results in the Multi-View Partial Point Cloud Challenge 2021 on Completion and Registration. In total, 128 participants registered for the competition, and 31 teams made valid submissions. The top-ranked solutions will be analyzed, and then we will discuss future research directions.
A Nested Attention Neural Hybrid Model for Grammatical Error Correction
Jul 10, 2017



Grammatical error correction (GEC) systems strive to correct both global errors in word order and usage, and local errors in spelling and inflection. Further developing upon recent work on neural machine translation, we propose a new hybrid neural model with nested attention layers for GEC. Experiments show that the new model can effectively correct errors of both types by incorporating word and character-level information,and that the model significantly outperforms previous neural models for GEC as measured on the standard CoNLL-14 benchmark dataset. Further analysis also shows that the superiority of the proposed model can be largely attributed to the use of the nested attention mechanism, which has proven particularly effective in correcting local errors that involve small edits in orthography.