 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Inclusive Theoretical Framework of Robust Supervised Contrastive Loss against Label Noise
Jan 02, 2025
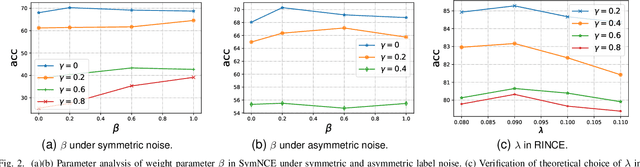
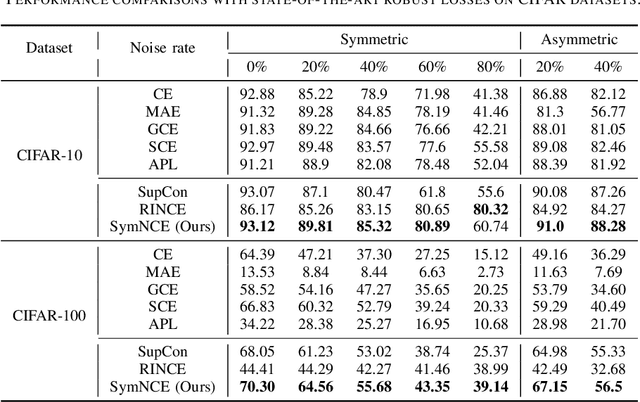
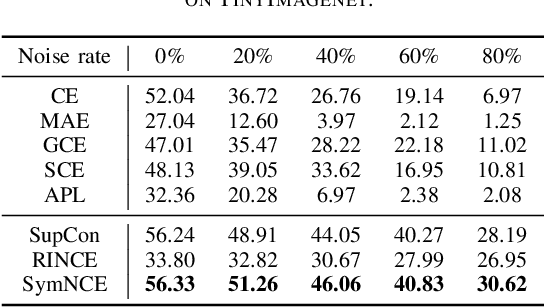
Learning from noisy labels is a critical challenge in machine learning, with vast implications for numerous real-world scenarios. While supervised contrastive learning has recently emerged as a powerful tool for navigating label noise, many existing solutions remain heuristic, often devoid of a systematic theoretical foundation for crafting robust supervised contrastive losses. To address the gap, in this paper, we propose a unified theoretical framework for robust losses under the pairwise contrastive paradigm. In particular, we for the first time derive a general robust condition for arbitrary contrastive losses, which serves as a criterion to verify the theoretical robustness of a supervised contrastive loss against label noise. The theory indicates that the popular InfoNCE loss is in fact non-robust, and accordingly inspires us to develop a robust version of InfoNCE, termed Symmetric InfoNCE (SymNCE). Moreover, we highlight that our theory is an inclusive framework that provides explanations to prior robust techniques such as nearest-neighbor (NN) sample selection and robust contrastive loss. Validation experiments on benchmark datasets demonstrate the superiority of SymNCE against label noise.
Understanding Difficult-to-learn Examples in Contrastive Learning: A Theoretical Framework for Spectral Contrastive Learning
Jan 02, 2025

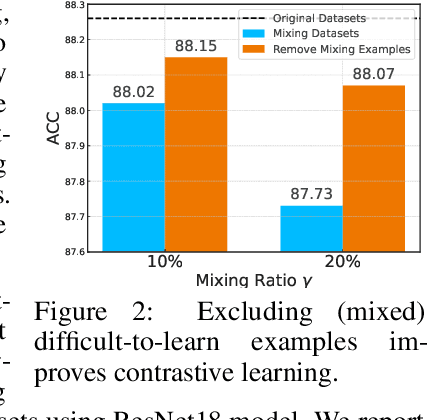
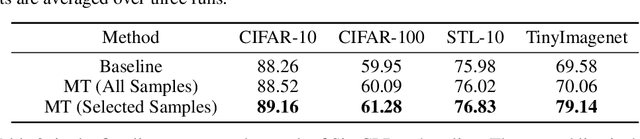
Unsupervised contrastive learning has shown significant performance improvements in recent years, often approaching or even rivaling supervised learning in various tasks. However, its learning mechanism is fundamentally different from that of supervised learning. Previous works have shown that difficult-to-learn examples (well-recognized in supervised learning as examples around the decision boundary), which are essential in supervised learning, contribute minimally in unsupervised settings. In this paper, perhaps surprisingly, we find that the direct removal of difficult-to-learn examples, although reduces the sample size, can boost the downstream classification performance of contrastive learning. To uncover the reasons behind this, we develop a theoretical framework modeling the similarity between different pairs of samples. Guided by this theoretical framework, we conduct a thorough theoretical analysis revealing that the presence of difficult-to-learn examples negatively affects the generalization of contrastive learning. Furthermore, we demonstrate that the removal of these examples, and techniques such as margin tuning and temperature scaling can enhance its generalization bounds, thereby improving performance. Empirically, we propose a simple and efficient mechanism for selecting difficult-to-learn examples and validate the effectiveness of the aforementioned methods, which substantiates the reliability of our proposed theoretical framework.