 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction Probing
Dec 21, 2022We propose reconstruction probing, a new analysis method for contextualized representations based on reconstruction probabilities in masked language models (MLMs). This method relies on comparing the reconstruction probabilities of tokens in a given sequence when conditioned on the representation of a single token that has been fully contextualized and when conditioned on only the decontextualized lexical prior of the model. This comparison can be understood as quantifying the contribution of contextualization towards reconstruction -- the difference in the reconstruction probabilities can only be attributed to the representational change of the single token induced by contextualization. We apply this analysis to three MLMs and find that contextualization boosts reconstructability of tokens that are close to the token being reconstructed in terms of linear and syntactic distance. Furthermore, we extend our analysis to finer-grained decomposition of contextualized representations, and we find that these boosts are largely attributable to static and positional embeddings at the input layer.
FairPrep: Promoting Data to a First-Class Citizen in Studies on Fairness-Enhancing Interventions
Nov 28, 2019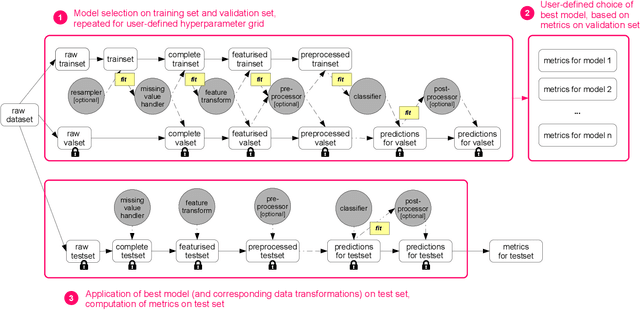
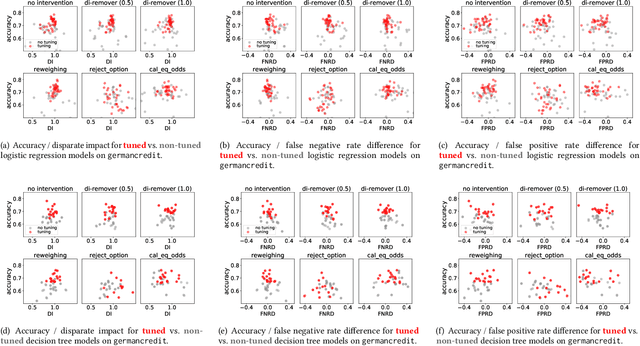
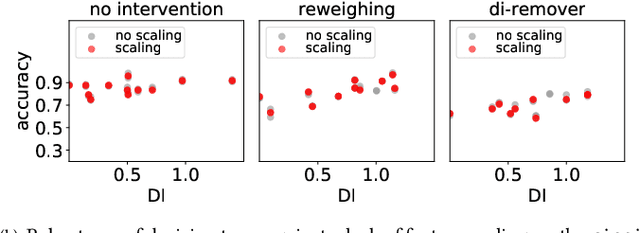
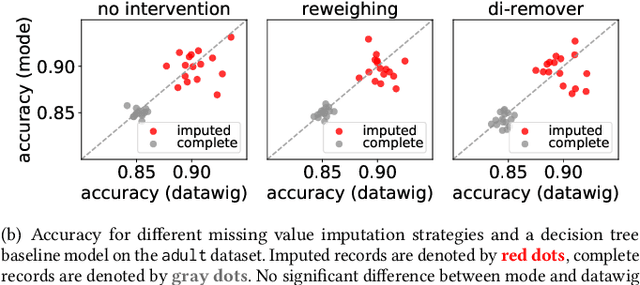
The importance of incorporating ethics and legal compliance into machine-assisted decision-making is broadly recognized. Further, several lines of recent work have argued that critical opportunities for improving data quality and representativeness, controlling for bias, and allowing humans to oversee and impact computational processes are missed if we do not consider the lifecycle stages upstream from model training and deployment. Yet, very little has been done to date to provide system-level support to data scientists who wish to develop and deploy responsible machine learning methods. We aim to fill this gap and present FairPrep, a design and evaluation framework for fairness-enhancing interventions. FairPrep is based on a developer-centered design, and helps data scientists follow best practices in software engineering and machine learning. As part of our contribution, we identify shortcomings in existing empirical studies for analyzing fairness-enhancing interventions. We then show how FairPrep can be used to measure the impact of sound best practices, such as hyperparameter tuning and feature scaling. In particular, our results suggest that the high variability of the outcomes of fairness-enhancing interventions observed in previous studies is often an artifact of a lack of hyperparameter tuning. Further, we show that the choice of a data cleaning method can impact the effectiveness of fairness-enhancing interventions.