 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning of Rotation-invariant 3D Point Set Features using Transformer and its Self-distillation
Aug 09, 2023Invariance against rotations of 3D objects is an important property in analyzing 3D point set data. Conventional 3D point set DNNs having rotation invariance typically obtain accurate 3D shape features via supervised learning by using labeled 3D point sets as training samples. However, due to the rapid increase in 3D point set data and the high cost of labeling, a framework to learn rotation-invariant 3D shape features from numerous unlabeled 3D point sets is required. This paper proposes a novel self-supervised learning framework for acquiring accurate and rotation-invariant 3D point set features at object-level. Our proposed lightweight DNN architecture decomposes an input 3D point set into multiple global-scale regions, called tokens, that preserve the spatial layout of partial shapes composing the 3D object. We employ a self-attention mechanism to refine the tokens and aggregate them into an expressive rotation-invariant feature per 3D point set. Our DNN is effectively trained by using pseudo-labels generated by a self-distillation framework. To facilitate the learning of accurate features, we propose to combine multi-crop and cut-mix data augmentation techniques to diversify 3D point sets for training. Through a comprehensive evaluation, we empirically demonstrate that, (1) existing rotation-invariant DNN architectures designed for supervised learning do not necessarily learn accurate 3D shape features under a self-supervised learning scenario, and (2) our proposed algorithm learns rotation-invariant 3D point set features that are more accurate than those learned by existing algorithms. Code will be available at https://github.com/takahikof/RIPT_SDMM
DeepDiffusion: Unsupervised Learning of Retrieval-adapted Representations via Diffusion-based Ranking on Latent Feature Manifold
Dec 14, 2021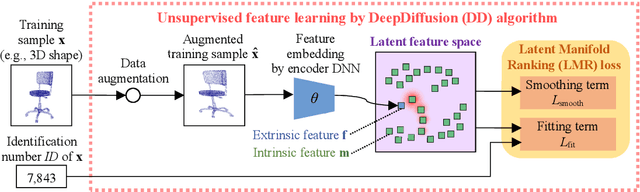
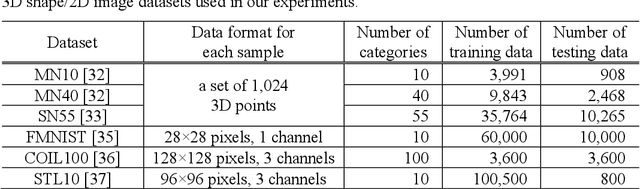
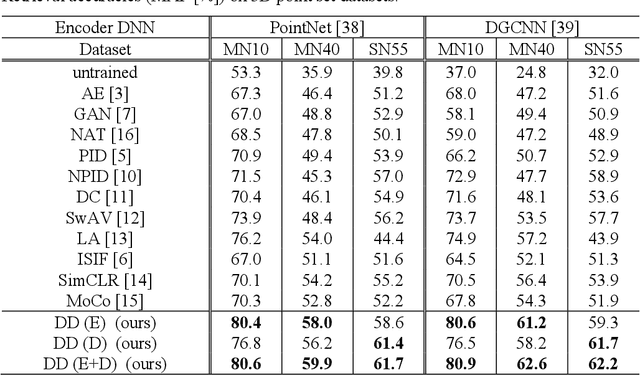
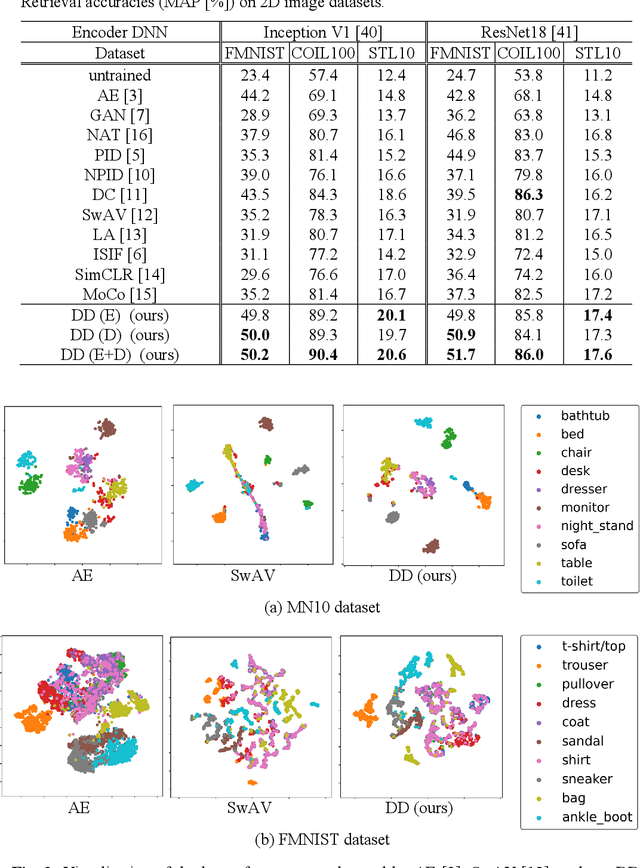
Unsupervised learning of feature representations is a challenging yet important problem for analyzing a large collection of multimedia data that do not have semantic labels. Recently proposed neural network-based unsupervised learning approaches have succeeded in obtaining features appropriate for classification of multimedia data. However, unsupervised learning of feature representations adapted to content-based matching, comparison, or retrieval of multimedia data has not been explored well. To obtain such retrieval-adapted features, we introduce the idea of combining diffusion distance on a feature manifold with neural network-based unsupervised feature learning. This idea is realized as a novel algorithm called DeepDiffusion (DD). DD simultaneously optimizes two components, a feature embedding by a deep neural network and a distance metric that leverages diffusion on a latent feature manifold, together. DD relies on its loss function but not encoder architecture. It can thus be applied to diverse multimedia data types with their respective encoder architectures. Experimental evaluation using 3D shapes and 2D images demonstrates versatility as well as high accuracy of the DD algorithm. Code is available at https://github.com/takahikof/DeepDiffusion