 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Adaptation via Side Graph Convolution for Efficient Fine-tuning of 3D Point Cloud Transformers
Feb 21, 2025Parameter-efficient fine-tuning (PEFT) of pre-trained 3D point cloud Transformers has emerged as a promising technique for 3D point cloud analysis. While existing PEFT methods attempt to minimize the number of tunable parameters, they often suffer from high temporal and spatial computational costs during fine-tuning. This paper proposes a novel PEFT algorithm called Side Token Adaptation on a neighborhood Graph (STAG) to achieve superior temporal and spatial efficiency. STAG employs a graph convolutional side network operating in parallel with a frozen backbone Transformer to adapt tokens to downstream tasks. Through efficient graph convolution, parameter sharing, and reduced gradient computation, STAG significantly reduces both temporal and spatial costs for fine-tuning. We also present Point Cloud Classification 13 (PCC13), a new benchmark comprising diverse publicly available 3D point cloud datasets to facilitate comprehensive evaluation. Extensive experiments using multiple pre-trained models and PCC13 demonstrates the effectiveness of STAG. Specifically, STAG maintains classification accuracy comparable to existing methods while reducing tunable parameters to only 0.43M and achieving significant reductions in both computation time and memory consumption for fine-tuning. Code and benchmark will be available at: https://github.com/takahikof/STAG.
MaskLRF: Self-supervised Pretraining via Masked Autoencoding of Local Reference Frames for Rotation-invariant 3D Point Set Analysis
Mar 01, 2024Following the successes in the fields of vision and language, self-supervised pretraining via masked autoencoding of 3D point set data, or Masked Point Modeling (MPM), has achieved state-of-the-art accuracy in various downstream tasks. However, current MPM methods lack a property essential for 3D point set analysis, namely, invariance against rotation of 3D objects/scenes. Existing MPM methods are thus not necessarily suitable for real-world applications where 3D point sets may have inconsistent orientations. This paper develops, for the first time, a rotation-invariant self-supervised pretraining framework for practical 3D point set analysis. The proposed algorithm, called MaskLRF, learns rotation-invariant and highly generalizable latent features via masked autoencoding of 3D points within Local Reference Frames (LRFs), which are not affected by rotation of 3D point sets. MaskLRF enhances the quality of latent features by integrating feature refinement using relative pose encoding and feature reconstruction using low-level but rich 3D geometry. The efficacy of MaskLRF is validated via extensive experiments on diverse downstream tasks including classification, segmentation, registration, and domain adaptation. I confirm that MaskLRF achieves new state-of-the-art accuracies in analyzing 3D point sets having inconsistent orientations. Code will be available at: https://github.com/takahikof/MaskLRF
Self-supervised Learning of Rotation-invariant 3D Point Set Features using Transformer and its Self-distillation
Aug 09, 2023Invariance against rotations of 3D objects is an important property in analyzing 3D point set data. Conventional 3D point set DNNs having rotation invariance typically obtain accurate 3D shape features via supervised learning by using labeled 3D point sets as training samples. However, due to the rapid increase in 3D point set data and the high cost of labeling, a framework to learn rotation-invariant 3D shape features from numerous unlabeled 3D point sets is required. This paper proposes a novel self-supervised learning framework for acquiring accurate and rotation-invariant 3D point set features at object-level. Our proposed lightweight DNN architecture decomposes an input 3D point set into multiple global-scale regions, called tokens, that preserve the spatial layout of partial shapes composing the 3D object. We employ a self-attention mechanism to refine the tokens and aggregate them into an expressive rotation-invariant feature per 3D point set. Our DNN is effectively trained by using pseudo-labels generated by a self-distillation framework. To facilitate the learning of accurate features, we propose to combine multi-crop and cut-mix data augmentation techniques to diversify 3D point sets for training. Through a comprehensive evaluation, we empirically demonstrate that, (1) existing rotation-invariant DNN architectures designed for supervised learning do not necessarily learn accurate 3D shape features under a self-supervised learning scenario, and (2) our proposed algorithm learns rotation-invariant 3D point set features that are more accurate than those learned by existing algorithms. Code will be available at https://github.com/takahikof/RIPT_SDMM
DeepDiffusion: Unsupervised Learning of Retrieval-adapted Representations via Diffusion-based Ranking on Latent Feature Manifold
Dec 14, 2021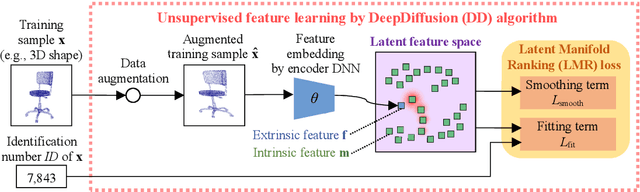
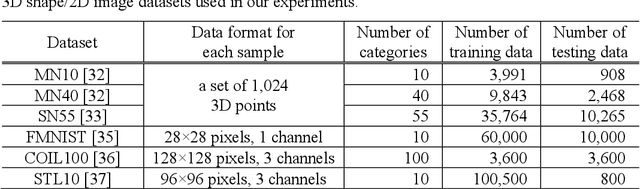
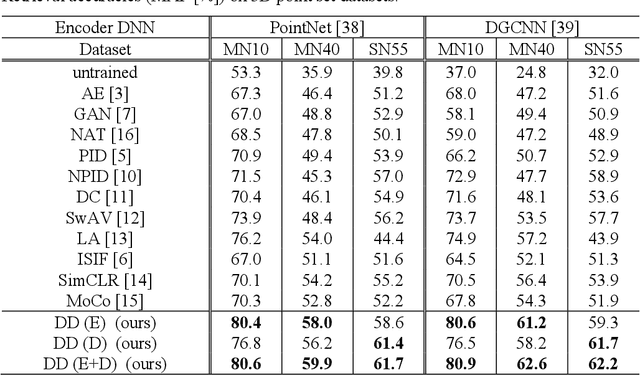
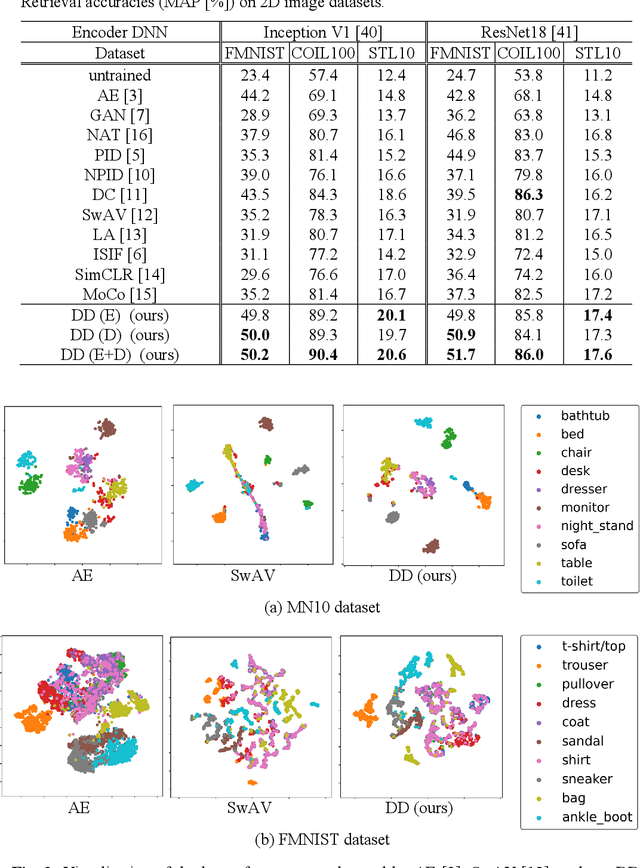
Unsupervised learning of feature representations is a challenging yet important problem for analyzing a large collection of multimedia data that do not have semantic labels. Recently proposed neural network-based unsupervised learning approaches have succeeded in obtaining features appropriate for classification of multimedia data. However, unsupervised learning of feature representations adapted to content-based matching, comparison, or retrieval of multimedia data has not been explored well. To obtain such retrieval-adapted features, we introduce the idea of combining diffusion distance on a feature manifold with neural network-based unsupervised feature learning. This idea is realized as a novel algorithm called DeepDiffusion (DD). DD simultaneously optimizes two components, a feature embedding by a deep neural network and a distance metric that leverages diffusion on a latent feature manifold, together. DD relies on its loss function but not encoder architecture. It can thus be applied to diverse multimedia data types with their respective encoder architectures. Experimental evaluation using 3D shapes and 2D images demonstrates versatility as well as high accuracy of the DD algorithm. Code is available at https://github.com/takahikof/DeepDiffusion