 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPAN: Spatial-Projection Alignment for Monocular 3D Object Detection
Nov 10, 2025Existing monocular 3D detectors typically tame the pronounced nonlinear regression of 3D bounding box through decoupled prediction paradigm, which employs multiple branches to estimate geometric center, depth, dimensions, and rotation angle separately. Although this decoupling strategy simplifies the learning process, it inherently ignores the geometric collaborative constraints between different attributes, resulting in the lack of geometric consistency prior, thereby leading to suboptimal performance. To address this issue, we propose novel Spatial-Projection Alignment (SPAN) with two pivotal components: (i). Spatial Point Alignment enforces an explicit global spatial constraint between the predicted and ground-truth 3D bounding boxes, thereby rectifying spatial drift caused by decoupled attribute regression. (ii). 3D-2D Projection Alignment ensures that the projected 3D box is aligned tightly within its corresponding 2D detection bounding box on the image plane, mitigating projection misalignment overlooked in previous works. To ensure training stability, we further introduce a Hierarchical Task Learning strategy that progressively incorporates spatial-projection alignment as 3D attribute predictions refine, preventing early stage error propagation across attributes. Extensive experiments demonstrate that the proposed method can be easily integrated into any established monocular 3D detector and delivers significant performance improvements.
Efficient Feature Aggregation and Scale-Aware Regression for Monocular 3D Object Detection
Nov 05, 2024



Monocular 3D object detection has attracted great attention due to simplicity and low cost. Existing methods typically follow conventional 2D detection paradigms, first locating object centers and then predicting 3D attributes via neighboring features. However, these methods predominantly rely on progressive cross-scale feature aggregation and focus solely on local information, which may result in a lack of global awareness and the omission of small-scale objects. In addition, due to large variation in object scales across different scenes and depths, inaccurate receptive fields often lead to background noise and degraded feature representation. To address these issues, we introduces MonoASRH, a novel monocular 3D detection framework composed of Efficient Hybrid Feature Aggregation Module (EH-FAM) and Adaptive Scale-Aware 3D Regression Head (ASRH). Specifically, EH-FAM employs multi-head attention with a global receptive field to extract semantic features for small-scale objects and leverages lightweight convolutional modules to efficiently aggregate visual features across different scales. The ASRH encodes 2D bounding box dimensions and then fuses scale features with the semantic features aggregated by EH-FAM through a scale-semantic feature fusion module. The scale-semantic feature fusion module guides ASRH in learning dynamic receptive field offsets, incorporating scale priors into 3D position prediction for better scale-awareness. Extensive experiments on the KITTI and Waymo datasets demonstrate that MonoASRH achieves state-of-the-art performance.
MonoDGP: Monocular 3D Object Detection with Decoupled-Query and Geometry-Error Priors
Oct 25, 2024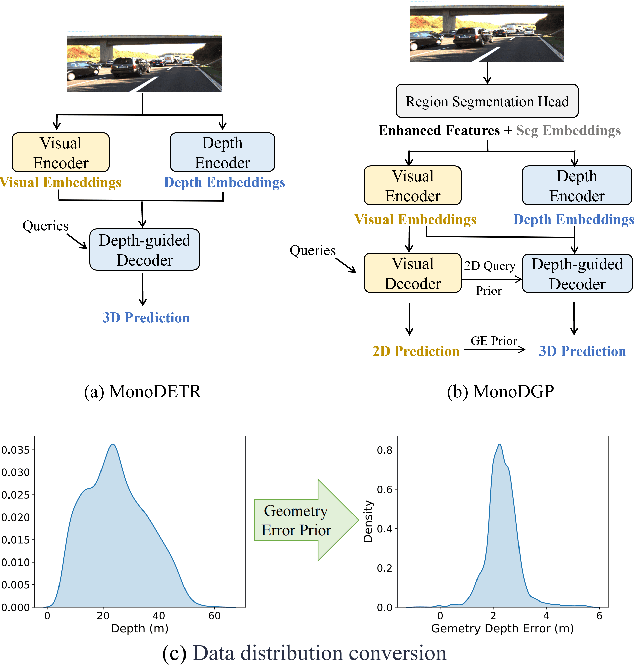
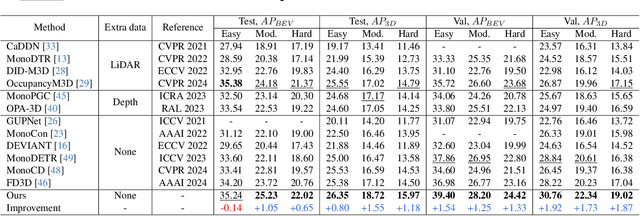
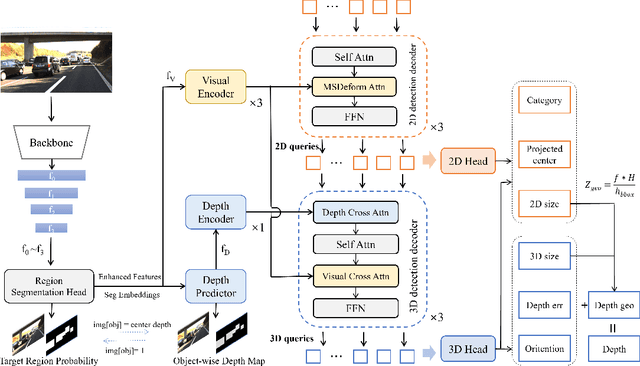
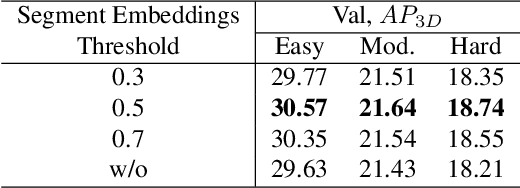
Perspective projection has been extensively utilized in monocular 3D object detection methods. It introduces geometric priors from 2D bounding boxes and 3D object dimensions to reduce the uncertainty of depth estimation. However, due to depth errors originating from the object's visual surface, the height of the bounding box often fails to represent the actual projected central height, which undermines the effectiveness of geometric depth. Direct prediction for the projected height unavoidably results in a loss of 2D priors, while multi-depth prediction with complex branches does not fully leverage geometric depth. This paper presents a Transformer-based monocular 3D object detection method called MonoDGP, which adopts perspective-invariant geometry errors to modify the projection formula. We also try to systematically discuss and explain the mechanisms and efficacy behind geometry errors, which serve as a simple but effective alternative to multi-depth prediction. Additionally, MonoDGP decouples the depth-guided decoder and constructs a 2D decoder only dependent on visual features, providing 2D priors and initializing object queries without the disturbance of 3D detection. To further optimize and fine-tune input tokens of the transformer decoder, we also introduce a Region Segment Head (RSH) that generates enhanced features and segment embeddings. Our monocular method demonstrates state-of-the-art performance on the KITTI benchmark without extra data. Code is available at https://github.com/PuFanqi23/MonoDGP.