 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlamaSeg: Image Segmentation via Autoregressive Mask Generation
May 26, 2025We present LlamaSeg, a visual autoregressive framework that unifies multiple image segmentation tasks via natural language instructions. We reformulate image segmentation as a visual generation problem, representing masks as "visual" tokens and employing a LLaMA-style Transformer to predict them directly from image inputs. By adhering to the next-token prediction paradigm, our approach naturally integrates segmentation tasks into autoregressive architectures. To support large-scale training, we introduce a data annotation pipeline and construct the SA-OVRS dataset, which contains 2M segmentation masks annotated with over 5,800 open-vocabulary labels or diverse textual descriptions, covering a wide spectrum of real-world scenarios. This enables our model to localize objects in images based on text prompts and to generate fine-grained masks. To more accurately evaluate the quality of masks produced by visual generative models, we further propose a composite metric that combines Intersection over Union (IoU) with Average Hausdorff Distance (AHD), offering a more precise assessment of contour fidelity. Experimental results demonstrate that our method surpasses existing generative models across multiple datasets and yields more detailed segmentation masks.
MonoDGP: Monocular 3D Object Detection with Decoupled-Query and Geometry-Error Priors
Oct 25, 2024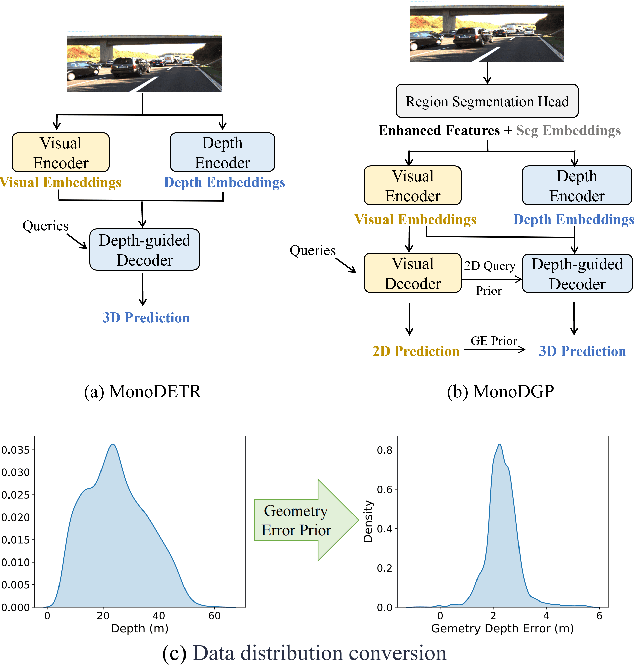
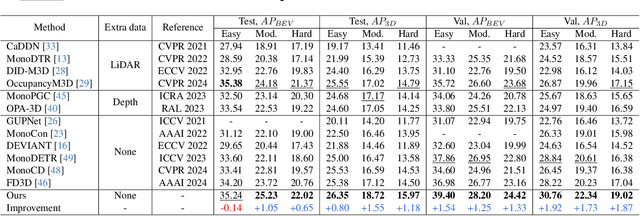
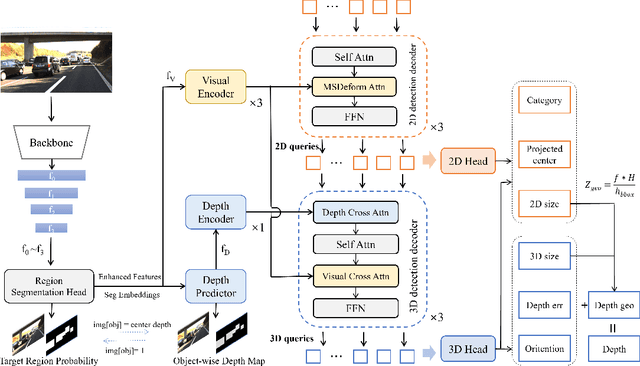
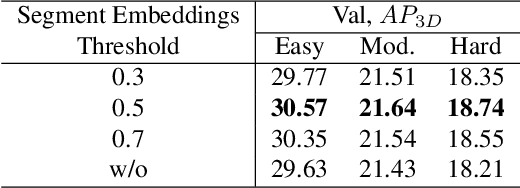
Perspective projection has been extensively utilized in monocular 3D object detection methods. It introduces geometric priors from 2D bounding boxes and 3D object dimensions to reduce the uncertainty of depth estimation. However, due to depth errors originating from the object's visual surface, the height of the bounding box often fails to represent the actual projected central height, which undermines the effectiveness of geometric depth. Direct prediction for the projected height unavoidably results in a loss of 2D priors, while multi-depth prediction with complex branches does not fully leverage geometric depth. This paper presents a Transformer-based monocular 3D object detection method called MonoDGP, which adopts perspective-invariant geometry errors to modify the projection formula. We also try to systematically discuss and explain the mechanisms and efficacy behind geometry errors, which serve as a simple but effective alternative to multi-depth prediction. Additionally, MonoDGP decouples the depth-guided decoder and constructs a 2D decoder only dependent on visual features, providing 2D priors and initializing object queries without the disturbance of 3D detection. To further optimize and fine-tune input tokens of the transformer decoder, we also introduce a Region Segment Head (RSH) that generates enhanced features and segment embeddings. Our monocular method demonstrates state-of-the-art performance on the KITTI benchmark without extra data. Code is available at https://github.com/PuFanqi23/MonoDGP.