 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning Dynamics with Random Binary Sequences
Oct 26, 2023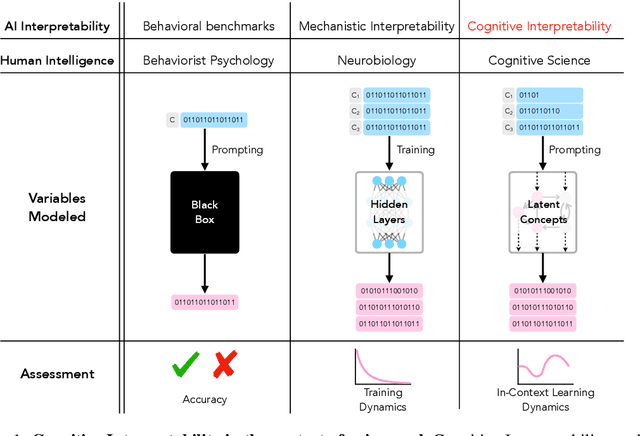
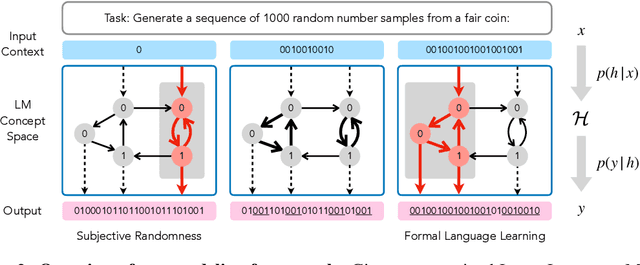
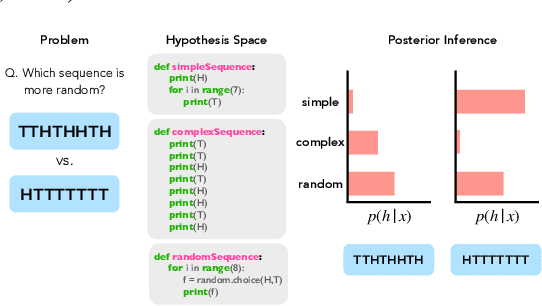
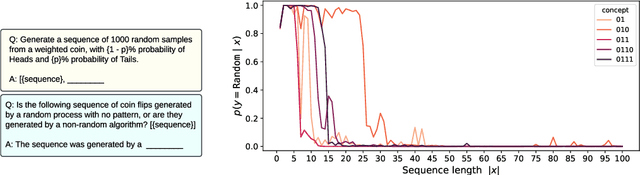
Large language models (LLMs) trained on huge corpora of text datasets demonstrate complex, emergent capabilities, achieving state-of-the-art performance on tasks they were not explicitly trained for. The precise nature of LLM capabilities is often mysterious, and different prompts can elicit different capabilities through in-context learning. We propose a Cognitive Interpretability framework that enables us to analyze in-context learning dynamics to understand latent concepts in LLMs underlying behavioral patterns. This provides a more nuanced understanding than success-or-failure evaluation benchmarks, but does not require observing internal activations as a mechanistic interpretation of circuits would. Inspired by the cognitive science of human randomness perception, we use random binary sequences as context and study dynamics of in-context learning by manipulating properties of context data, such as sequence length. In the latest GPT-3.5+ models, we find emergent abilities to generate pseudo-random numbers and learn basic formal languages, with striking in-context learning dynamics where model outputs transition sharply from pseudo-random behaviors to deterministic repetition.
Mechanistic Mode Connectivity
Nov 15, 2022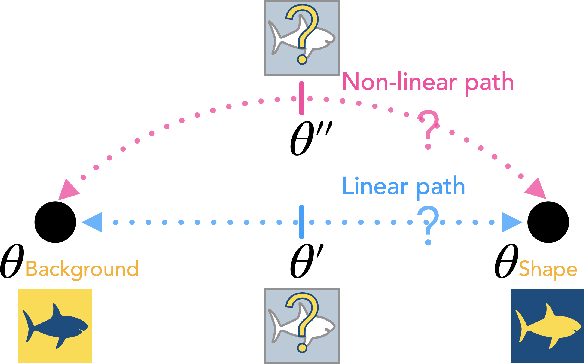
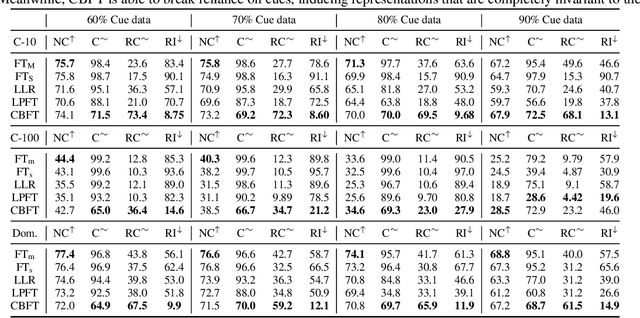
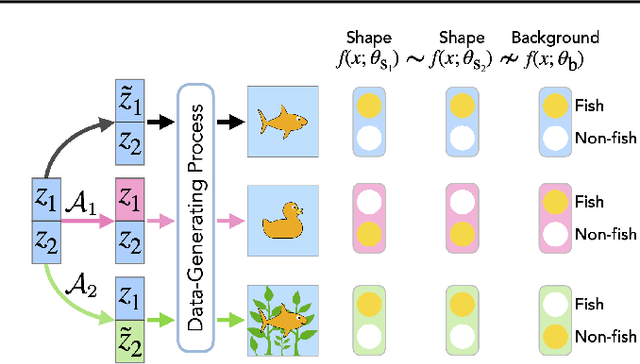
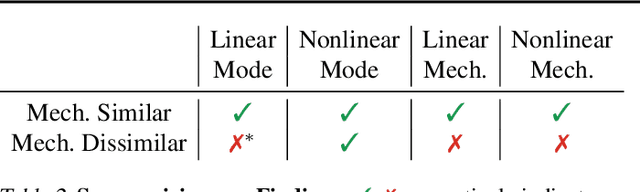
Neural networks are known to be biased towards learning mechanisms that help identify $spurious\, attributes$, yielding features that do not generalize well under distribution shifts. To understand and address this limitation, we study the geometry of neural network loss landscapes through the lens of $mode\, connectivity$, the observation that minimizers of neural networks are connected via simple paths of low loss. Our work addresses two questions: (i) do minimizers that encode dissimilar mechanisms connect via simple paths of low loss? (ii) can fine-tuning a pretrained model help switch between such minimizers? We define a notion of $\textit{mechanistic similarity}$ and demonstrate that lack of linear connectivity between two minimizers implies the corresponding models use dissimilar mechanisms for making their predictions. This property helps us demonstrate that na$\"{i}$ve fine-tuning can fail to eliminate a model's reliance on spurious attributes. We thus propose a method for altering a model's mechanisms, named $connectivity$-$based$ $fine$-$tuning$, and validate its usefulness by inducing models invariant to spurious attributes.