 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond BatchNorm: Towards a General Understanding of Normalization in Deep Learning
Paper and Code
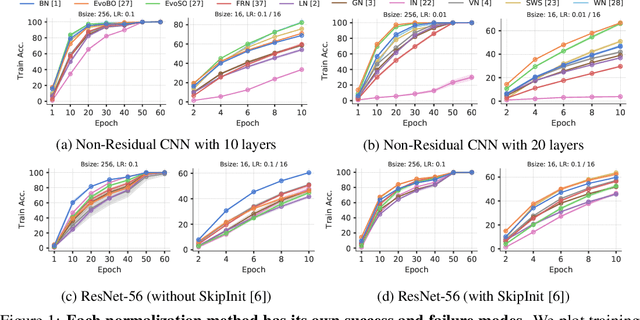

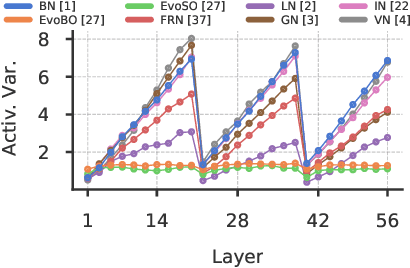
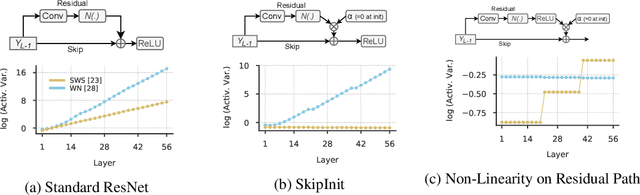
Inspired by BatchNorm, there has been an explosion of normalization layers for deep neural networks (DNNs). However, these alternative normalization layers have seen minimal use, partially due to a lack of guiding principles that can help identify when these layers can serve as a replacement for BatchNorm. To address this problem, we take a theoretical approach, generalizing the known beneficial mechanisms of BatchNorm to several recently proposed normalization techniques. Our generalized theory leads to the following set of principles: (i) similar to BatchNorm, activations-based normalization layers can prevent exponential growth of activations in ResNets, but parametric layers require explicit remedies; (ii) use of GroupNorm can ensure informative forward propagation, with different samples being assigned dissimilar activations, but increasing group size results in increasingly indistinguishable activations for different samples, explaining slow convergence speed in models with LayerNorm; (iii) small group sizes result in large gradient norm in earlier layers, hence explaining training instability issues in Instance Normalization and illustrating a speed-stability tradeoff in GroupNorm. Overall, our analysis reveals a unified set of mechanisms that underpin the success of normalization methods in deep learning, providing us with a compass to systematically explore the vast design space of DNN normalization layers.